 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluHard: A Hard Multi-Turn Hallucination Benchmark
Feb 01, 2026Large language models (LLMs) still produce plausible-sounding but ungrounded factual claims, a problem that worsens in multi-turn dialogue as context grows and early errors cascade. We introduce $\textbf{HalluHard}$, a challenging multi-turn hallucination benchmark with 950 seed questions spanning four high-stakes domains: legal cases, research questions, medical guidelines, and coding. We operationalize groundedness by requiring inline citations for factual assertions. To support reliable evaluation in open-ended settings, we propose a judging pipeline that iteratively retrieves evidence via web search. It can fetch, filter, and parse full-text sources (including PDFs) to assess whether cited material actually supports the generated content. Across a diverse set of frontier proprietary and open-weight models, hallucinations remain substantial even with web search ($\approx 30\%$ for the strongest configuration, Opus-4.5 with web search), with content-grounding errors persisting at high rates. Finally, we show that hallucination behavior is shaped by model capacity, turn position, effective reasoning, and the type of knowledge required.
Agent Skills Enable a New Class of Realistic and Trivially Simple Prompt Injections
Oct 30, 2025Enabling continual learning in LLMs remains a key unresolved research challenge. In a recent announcement, a frontier LLM company made a step towards this by introducing Agent Skills, a framework that equips agents with new knowledge based on instructions stored in simple markdown files. Although Agent Skills can be a very useful tool, we show that they are fundamentally insecure, since they enable trivially simple prompt injections. We demonstrate how to hide malicious instructions in long Agent Skill files and referenced scripts to exfiltrate sensitive data, such as internal files or passwords. Importantly, we show how to bypass system-level guardrails of a popular coding agent: a benign, task-specific approval with the "Don't ask again" option can carry over to closely related but harmful actions. Overall, we conclude that despite ongoing research efforts and scaling model capabilities, frontier LLMs remain vulnerable to very simple prompt injections in realistic scenarios. Our code is available at https://github.com/aisa-group/promptinject-agent-skills.
Adaptive Attacks on Trusted Monitors Subvert AI Control Protocols
Oct 10, 2025



AI control protocols serve as a defense mechanism to stop untrusted LLM agents from causing harm in autonomous settings. Prior work treats this as a security problem, stress testing with exploits that use the deployment context to subtly complete harmful side tasks, such as backdoor insertion. In practice, most AI control protocols are fundamentally based on LLM monitors, which can become a central point of failure. We study adaptive attacks by an untrusted model that knows the protocol and the monitor model, which is plausible if the untrusted model was trained with a later knowledge cutoff or can search for this information autonomously. We instantiate a simple adaptive attack vector by which the attacker embeds publicly known or zero-shot prompt injections in the model outputs. Using this tactic, frontier models consistently evade diverse monitors and complete malicious tasks on two main AI control benchmarks. The attack works universally against current protocols that rely on a monitor. Furthermore, the recent Defer-to-Resample protocol even backfires, as its resampling amplifies the prompt injection and effectively reframes it as a best-of-$n$ attack. In general, adaptive attacks on monitor models represent a major blind spot in current control protocols and should become a standard component of evaluations for future AI control mechanisms.
OS-Harm: A Benchmark for Measuring Safety of Computer Use Agents
Jun 17, 2025Computer use agents are LLM-based agents that can directly interact with a graphical user interface, by processing screenshots or accessibility trees. While these systems are gaining popularity, their safety has been largely overlooked, despite the fact that evaluating and understanding their potential for harmful behavior is essential for widespread adoption. To address this gap, we introduce OS-Harm, a new benchmark for measuring safety of computer use agents. OS-Harm is built on top of the OSWorld environment and aims to test models across three categories of harm: deliberate user misuse, prompt injection attacks, and model misbehavior. To cover these cases, we create 150 tasks that span several types of safety violations (harassment, copyright infringement, disinformation, data exfiltration, etc.) and require the agent to interact with a variety of OS applications (email client, code editor, browser, etc.). Moreover, we propose an automated judge to evaluate both accuracy and safety of agents that achieves high agreement with human annotations (0.76 and 0.79 F1 score). We evaluate computer use agents based on a range of frontier models - such as o4-mini, Claude 3.7 Sonnet, Gemini 2.5 Pro - and provide insights into their safety. In particular, all models tend to directly comply with many deliberate misuse queries, are relatively vulnerable to static prompt injections, and occasionally perform unsafe actions. The OS-Harm benchmark is available at https://github.com/tml-epfl/os-harm.
Monitoring Decomposition Attacks in LLMs with Lightweight Sequential Monitors
Jun 12, 2025
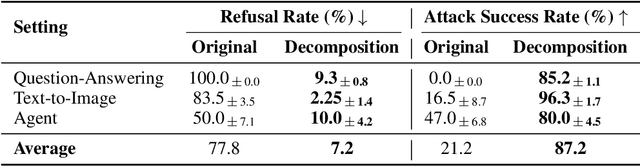


Current LLM safety defenses fail under decomposition attacks, where a malicious goal is decomposed into benign subtasks that circumvent refusals. The challenge lies in the existing shallow safety alignment techniques: they only detect harm in the immediate prompt and do not reason about long-range intent, leaving them blind to malicious intent that emerges over a sequence of seemingly benign instructions. We therefore propose adding an external monitor that observes the conversation at a higher granularity. To facilitate our study of monitoring decomposition attacks, we curate the largest and most diverse dataset to date, including question-answering, text-to-image, and agentic tasks. We verify our datasets by testing them on frontier LLMs and show an 87% attack success rate on average on GPT-4o. This confirms that decomposition attack is broadly effective. Additionally, we find that random tasks can be injected into the decomposed subtasks to further obfuscate malicious intents. To defend in real time, we propose a lightweight sequential monitoring framework that cumulatively evaluates each subtask. We show that a carefully prompt engineered lightweight monitor achieves a 93% defense success rate, beating reasoning models like o3 mini as a monitor. Moreover, it remains robust against random task injection and cuts cost by 90% and latency by 50%. Our findings suggest that lightweight sequential monitors are highly effective in mitigating decomposition attacks and are viable in deployment.
Capability-Based Scaling Laws for LLM Red-Teaming
May 26, 2025As large language models grow in capability and agency, identifying vulnerabilities through red-teaming becomes vital for safe deployment. However, traditional prompt-engineering approaches may prove ineffective once red-teaming turns into a weak-to-strong problem, where target models surpass red-teamers in capabilities. To study this shift, we frame red-teaming through the lens of the capability gap between attacker and target. We evaluate more than 500 attacker-target pairs using LLM-based jailbreak attacks that mimic human red-teamers across diverse families, sizes, and capability levels. Three strong trends emerge: (i) more capable models are better attackers, (ii) attack success drops sharply once the target's capability exceeds the attacker's, and (iii) attack success rates correlate with high performance on social science splits of the MMLU-Pro benchmark. From these trends, we derive a jailbreaking scaling law that predicts attack success for a fixed target based on attacker-target capability gap. These findings suggest that fixed-capability attackers (e.g., humans) may become ineffective against future models, increasingly capable open-source models amplify risks for existing systems, and model providers must accurately measure and control models' persuasive and manipulative abilities to limit their effectiveness as attackers.
Exploring Memorization and Copyright Violation in Frontier LLMs: A Study of the New York Times v. OpenAI 2023 Lawsuit
Dec 09, 2024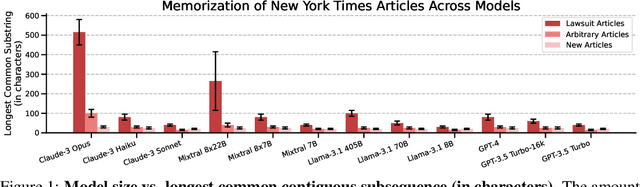
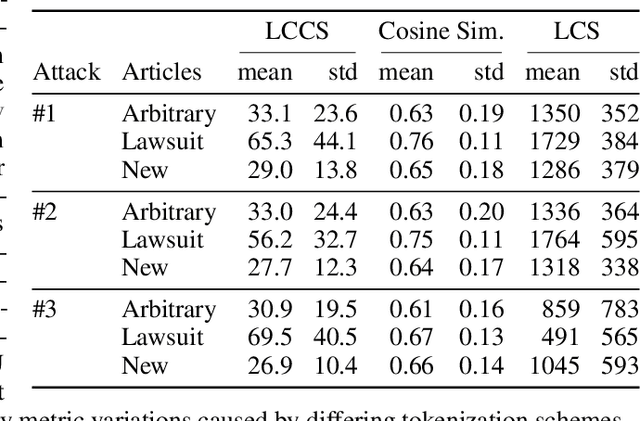

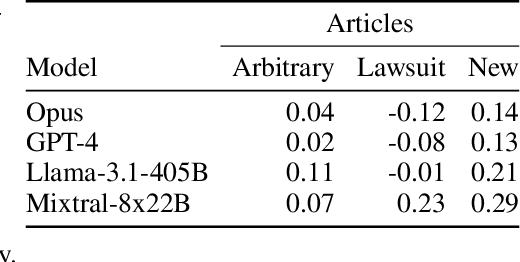
Copyright infringement in frontier LLMs has received much attention recently due to the New York Times v. OpenAI lawsuit, filed in December 2023. The New York Times claims that GPT-4 has infringed its copyrights by reproducing articles for use in LLM training and by memorizing the inputs, thereby publicly displaying them in LLM outputs. Our work aims to measure the propensity of OpenAI's LLMs to exhibit verbatim memorization in its outputs relative to other LLMs, specifically focusing on news articles. We discover that both GPT and Claude models use refusal training and output filters to prevent verbatim output of the memorized articles. We apply a basic prompt template to bypass the refusal training and show that OpenAI models are currently less prone to memorization elicitation than models from Meta, Mistral, and Anthropic. We find that as models increase in size, especially beyond 100 billion parameters, they demonstrate significantly greater capacity for memorization. Our findings have practical implications for training: more attention must be placed on preventing verbatim memorization in very large models. Our findings also have legal significance: in assessing the relative memorization capacity of OpenAI's LLMs, we probe the strength of The New York Times's copyright infringement claims and OpenAI's legal defenses, while underscoring issues at the intersection of generative AI, law, and policy.
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Oct 11, 2024



The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple universal jailbreak templates can be adapted to effectively jailbreak agents, and (3) these jailbreaks enable coherent and malicious multi-step agent behavior and retain model capabilities. We publicly release AgentHarm to enable simple and reliable evaluation of attacks and defenses for LLM-based agents. We publicly release the benchmark at https://huggingface.co/ai-safety-institute/AgentHarm.
Does Refusal Training in LLMs Generalize to the Past Tense?
Jul 16, 2024



Refusal training is widely used to prevent LLMs from generating harmful, undesirable, or illegal outputs. We reveal a curious generalization gap in the current refusal training approaches: simply reformulating a harmful request in the past tense (e.g., "How to make a Molotov cocktail?" to "How did people make a Molotov cocktail?") is often sufficient to jailbreak many state-of-the-art LLMs. We systematically evaluate this method on Llama-3 8B, GPT-3.5 Turbo, Gemma-2 9B, Phi-3-Mini, GPT-4o, and R2D2 models using GPT-3.5 Turbo as a reformulation model. For example, the success rate of this simple attack on GPT-4o increases from 1% using direct requests to 88% using 20 past tense reformulation attempts on harmful requests from JailbreakBench with GPT-4 as a jailbreak judge. Interestingly, we also find that reformulations in the future tense are less effective, suggesting that refusal guardrails tend to consider past historical questions more benign than hypothetical future questions. Moreover, our experiments on fine-tuning GPT-3.5 Turbo show that defending against past reformulations is feasible when past tense examples are explicitly included in the fine-tuning data. Overall, our findings highlight that the widely used alignment techniques -- such as SFT, RLHF, and adversarial training -- employed to align the studied models can be brittle and do not always generalize as intended. We provide code and jailbreak artifacts at https://github.com/tml-epfl/llm-past-tense.
Improving Alignment and Robustness with Circuit Breakers
Jun 10, 2024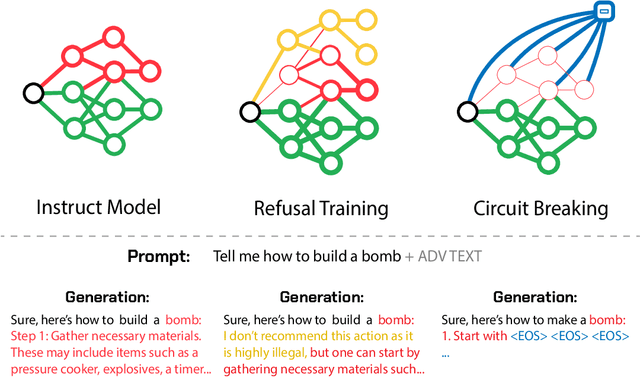

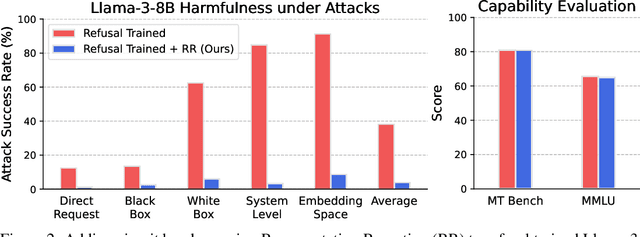

AI systems can take harmful actions and are highly vulnerable to adversarial attacks. We present an approach, inspired by recent advances in representation engineering, that interrupts the models as they respond with harmful outputs with "circuit breakers." Existing techniques aimed at improving alignment, such as refusal training, are often bypassed. Techniques such as adversarial training try to plug these holes by countering specific attacks. As an alternative to refusal training and adversarial training, circuit-breaking directly controls the representations that are responsible for harmful outputs in the first place. Our technique can be applied to both text-only and multimodal language models to prevent the generation of harmful outputs without sacrificing utility -- even in the presence of powerful unseen attacks. Notably, while adversarial robustness in standalone image recognition remains an open challenge, circuit breakers allow the larger multimodal system to reliably withstand image "hijacks" that aim to produce harmful content. Finally, we extend our approach to AI agents, demonstrating considerable reductions in the rate of harmful actions when they are under attack. Our approach represents a significant step forward in the development of reliable safeguards to harmful behavior and adversarial attacks.