 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Is More for Alignment: A Simple but Tough-to-Beat Baseline for Instruction Fine-Tuning
Paper and Code


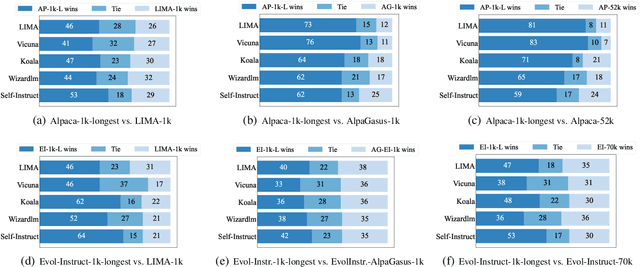

There is a consensus that instruction fine-tuning of LLMs requires high-quality data, but what are they? LIMA (NeurIPS 2023) and AlpaGasus (ICLR 2024) are state-of-the-art methods for selecting such high-quality examples, either via manual curation or using GPT-3.5-Turbo as a quality scorer. We show that the extremely simple baseline of selecting the 1,000 instructions with longest responses from standard datasets can consistently outperform these sophisticated methods according to GPT-4 and PaLM-2 as judges, while remaining competitive on the OpenLLM benchmarks that test factual knowledge. We demonstrate this for several state-of-the-art LLMs (Llama-2-7B, Llama-2-13B, and Mistral-7B) and datasets (Alpaca-52k and Evol-Instruct-70k). In addition, a lightweight refinement of such long instructions can further improve the abilities of the fine-tuned LLMs, and allows us to obtain the 2nd highest-ranked Llama-2-7B-based model on AlpacaEval 2.0 while training on only 1,000 examples and no extra preference data. We also conduct a thorough analysis of our models to ensure that their enhanced performance is not simply due to GPT-4's preference for longer responses, thus ruling out any artificial improvement. In conclusion, our findings suggest that fine-tuning on the longest instructions should be the default baseline for any research on instruction fine-tuning.