 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Induction Heads: How Transformers Select Causal Structures In Context
Sep 09, 2025Transformers have exhibited exceptional capabilities in sequence modeling tasks, leveraging self-attention and in-context learning. Critical to this success are induction heads, attention circuits that enable copying tokens based on their previous occurrences. In this work, we introduce a novel framework that showcases transformers' ability to dynamically handle causal structures. Existing works rely on Markov Chains to study the formation of induction heads, revealing how transformers capture causal dependencies and learn transition probabilities in-context. However, they rely on a fixed causal structure that fails to capture the complexity of natural languages, where the relationship between tokens dynamically changes with context. To this end, our framework varies the causal structure through interleaved Markov chains with different lags while keeping the transition probabilities fixed. This setting unveils the formation of Selective Induction Heads, a new circuit that endows transformers with the ability to select the correct causal structure in-context. We empirically demonstrate that transformers learn this mechanism to predict the next token by identifying the correct lag and copying the corresponding token from the past. We provide a detailed construction of a 3-layer transformer to implement the selective induction head, and a theoretical analysis proving that this mechanism asymptotically converges to the maximum likelihood solution. Our findings advance the understanding of how transformers select causal structures, providing new insights into their functioning and interpretability.
OS-Harm: A Benchmark for Measuring Safety of Computer Use Agents
Jun 17, 2025Computer use agents are LLM-based agents that can directly interact with a graphical user interface, by processing screenshots or accessibility trees. While these systems are gaining popularity, their safety has been largely overlooked, despite the fact that evaluating and understanding their potential for harmful behavior is essential for widespread adoption. To address this gap, we introduce OS-Harm, a new benchmark for measuring safety of computer use agents. OS-Harm is built on top of the OSWorld environment and aims to test models across three categories of harm: deliberate user misuse, prompt injection attacks, and model misbehavior. To cover these cases, we create 150 tasks that span several types of safety violations (harassment, copyright infringement, disinformation, data exfiltration, etc.) and require the agent to interact with a variety of OS applications (email client, code editor, browser, etc.). Moreover, we propose an automated judge to evaluate both accuracy and safety of agents that achieves high agreement with human annotations (0.76 and 0.79 F1 score). We evaluate computer use agents based on a range of frontier models - such as o4-mini, Claude 3.7 Sonnet, Gemini 2.5 Pro - and provide insights into their safety. In particular, all models tend to directly comply with many deliberate misuse queries, are relatively vulnerable to static prompt injections, and occasionally perform unsafe actions. The OS-Harm benchmark is available at https://github.com/tml-epfl/os-harm.
Adversarially Robust CLIP Models Can Induce Better (Robust) Perceptual Metrics
Feb 17, 2025



Measuring perceptual similarity is a key tool in computer vision. In recent years perceptual metrics based on features extracted from neural networks with large and diverse training sets, e.g. CLIP, have become popular. At the same time, the metrics extracted from features of neural networks are not adversarially robust. In this paper we show that adversarially robust CLIP models, called R-CLIP$_\textrm{F}$, obtained by unsupervised adversarial fine-tuning induce a better and adversarially robust perceptual metric that outperforms existing metrics in a zero-shot setting, and further matches the performance of state-of-the-art metrics while being robust after fine-tuning. Moreover, our perceptual metric achieves strong performance on related tasks such as robust image-to-image retrieval, which becomes especially relevant when applied to "Not Safe for Work" (NSFW) content detection and dataset filtering. While standard perceptual metrics can be easily attacked by a small perturbation completely degrading NSFW detection, our robust perceptual metric maintains high accuracy under an attack while having similar performance for unperturbed images. Finally, perceptual metrics induced by robust CLIP models have higher interpretability: feature inversion can show which images are considered similar, while text inversion can find what images are associated to a given prompt. This also allows us to visualize the very rich visual concepts learned by a CLIP model, including memorized persons, paintings and complex queries.
Towards Unified Benchmark and Models for Multi-Modal Perceptual Metrics
Dec 13, 2024



Human perception of similarity across uni- and multimodal inputs is highly complex, making it challenging to develop automated metrics that accurately mimic it. General purpose vision-language models, such as CLIP and large multi-modal models (LMMs), can be applied as zero-shot perceptual metrics, and several recent works have developed models specialized in narrow perceptual tasks. However, the extent to which existing perceptual metrics align with human perception remains unclear. To investigate this question, we introduce UniSim-Bench, a benchmark encompassing 7 multi-modal perceptual similarity tasks, with a total of 25 datasets. Our evaluation reveals that while general-purpose models perform reasonably well on average, they often lag behind specialized models on individual tasks. Conversely, metrics fine-tuned for specific tasks fail to generalize well to unseen, though related, tasks. As a first step towards a unified multi-task perceptual similarity metric, we fine-tune both encoder-based and generative vision-language models on a subset of the UniSim-Bench tasks. This approach yields the highest average performance, and in some cases, even surpasses taskspecific models. Nevertheless, these models still struggle with generalization to unseen tasks, highlighting the ongoing challenge of learning a robust, unified perceptual similarity metric capable of capturing the human notion of similarity. The code and models are available at https://github.com/SaraGhazanfari/UniSim.
Perturb and Recover: Fine-tuning for Effective Backdoor Removal from CLIP
Dec 01, 2024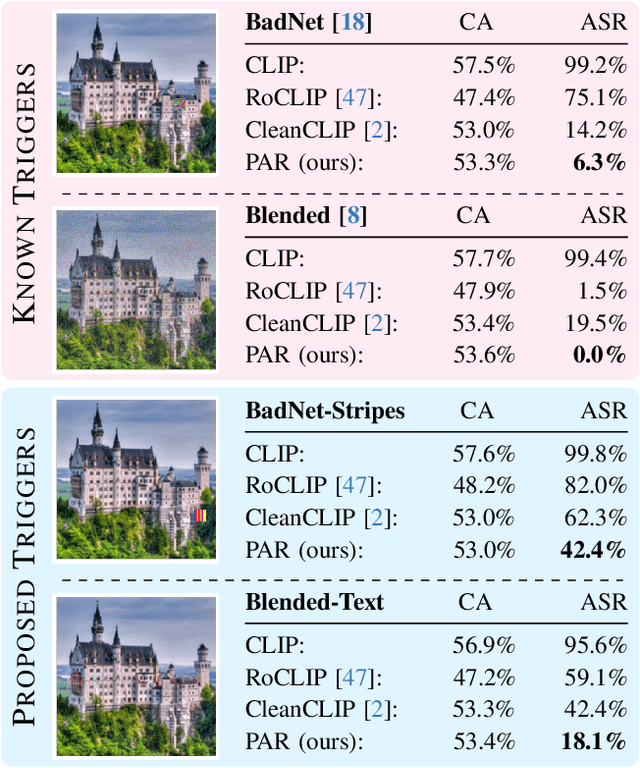
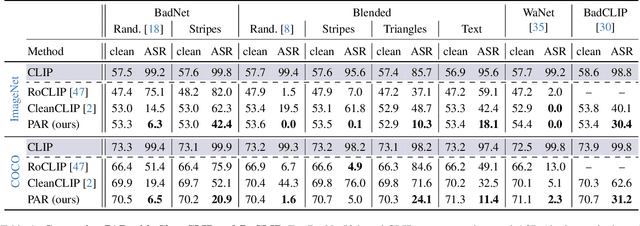

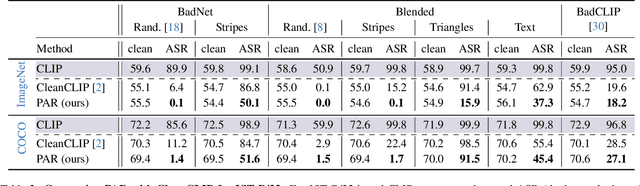
Vision-Language models like CLIP have been shown to be highly effective at linking visual perception and natural language understanding, enabling sophisticated image-text capabilities, including strong retrieval and zero-shot classification performance. Their widespread use, as well as the fact that CLIP models are trained on image-text pairs from the web, make them both a worthwhile and relatively easy target for backdoor attacks. As training foundational models, such as CLIP, from scratch is very expensive, this paper focuses on cleaning potentially poisoned models via fine-tuning. We first show that existing cleaning techniques are not effective against simple structured triggers used in Blended or BadNet backdoor attacks, exposing a critical vulnerability for potential real-world deployment of these models. Then, we introduce PAR, Perturb and Recover, a surprisingly simple yet effective mechanism to remove backdoors from CLIP models. Through extensive experiments across different encoders and types of backdoor attacks, we show that PAR achieves high backdoor removal rate while preserving good standard performance. Finally, we illustrate that our approach is effective even only with synthetic text-image pairs, i.e. without access to real training data. The code and models are available at \href{https://github.com/nmndeep/PerturbAndRecover}{https://github.com/nmndeep/PerturbAndRecover}.
Is In-Context Learning Sufficient for Instruction Following in LLMs?
May 30, 2024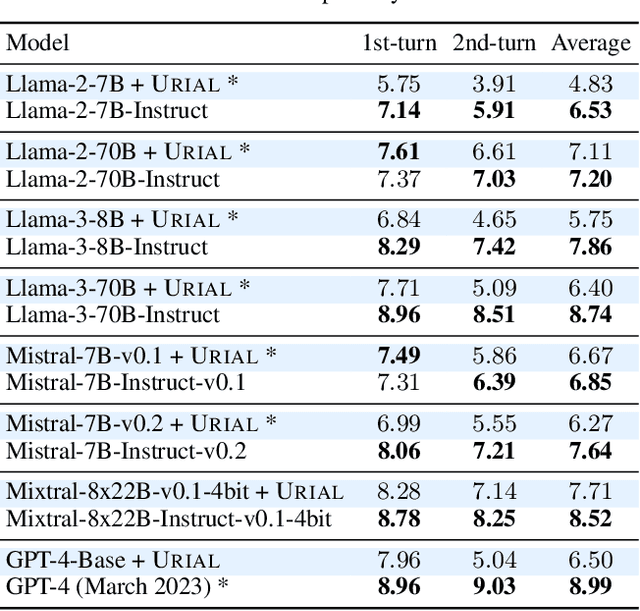
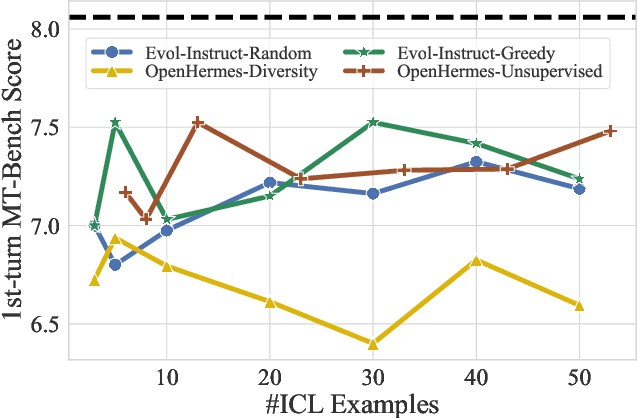
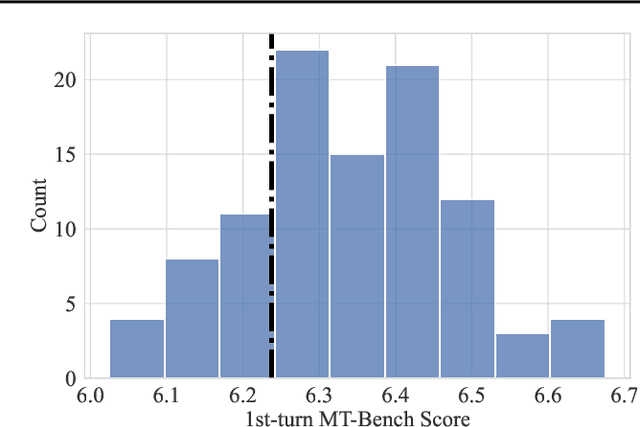
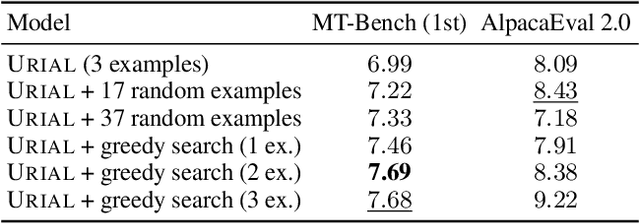
In-context learning (ICL) allows LLMs to learn from examples without changing their weights, which is a particularly promising capability for long-context LLMs that can potentially learn from many examples. Recently, Lin et al. (2024) proposed URIAL, a method using only three in-context examples to align base LLMs, achieving non-trivial instruction following performance. In this work, we show that, while effective, ICL alignment with URIAL still underperforms compared to instruction fine-tuning on established benchmarks such as MT-Bench and AlpacaEval 2.0 (LC), especially with more capable base LMs. Unlike for tasks such as classification, translation, or summarization, adding more ICL demonstrations for long-context LLMs does not systematically improve instruction following performance. To address this limitation, we derive a greedy selection approach for ICL examples that noticeably improves performance, yet without bridging the gap to instruction fine-tuning. Finally, we provide a series of ablation studies to better understand the reasons behind the remaining gap, and we show how some aspects of ICL depart from the existing knowledge and are specific to the instruction tuning setting. Overall, our work advances the understanding of ICL as an alignment technique. We provide our code at https://github.com/tml-epfl/icl-alignment.
Competition Report: Finding Universal Jailbreak Backdoors in Aligned LLMs
Apr 22, 2024



Large language models are aligned to be safe, preventing users from generating harmful content like misinformation or instructions for illegal activities. However, previous work has shown that the alignment process is vulnerable to poisoning attacks. Adversaries can manipulate the safety training data to inject backdoors that act like a universal sudo command: adding the backdoor string to any prompt enables harmful responses from models that, otherwise, behave safely. Our competition, co-located at IEEE SaTML 2024, challenged participants to find universal backdoors in several large language models. This report summarizes the key findings and promising ideas for future research.
Jailbreaking Leading Safety-Aligned LLMs with Simple Adaptive Attacks
Apr 02, 2024We show that even the most recent safety-aligned LLMs are not robust to simple adaptive jailbreaking attacks. First, we demonstrate how to successfully leverage access to logprobs for jailbreaking: we initially design an adversarial prompt template (sometimes adapted to the target LLM), and then we apply random search on a suffix to maximize the target logprob (e.g., of the token "Sure"), potentially with multiple restarts. In this way, we achieve nearly 100\% attack success rate -- according to GPT-4 as a judge -- on GPT-3.5/4, Llama-2-Chat-7B/13B/70B, Gemma-7B, and R2D2 from HarmBench that was adversarially trained against the GCG attack. We also show how to jailbreak all Claude models -- that do not expose logprobs -- via either a transfer or prefilling attack with 100\% success rate. In addition, we show how to use random search on a restricted set of tokens for finding trojan strings in poisoned models -- a task that shares many similarities with jailbreaking -- which is the algorithm that brought us the first place in the SaTML'24 Trojan Detection Competition. The common theme behind these attacks is that adaptivity is crucial: different models are vulnerable to different prompting templates (e.g., R2D2 is very sensitive to in-context learning prompts), some models have unique vulnerabilities based on their APIs (e.g., prefilling for Claude), and in some settings it is crucial to restrict the token search space based on prior knowledge (e.g., for trojan detection). We provide the code, prompts, and logs of the attacks at https://github.com/tml-epfl/llm-adaptive-attacks.
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Mar 28, 2024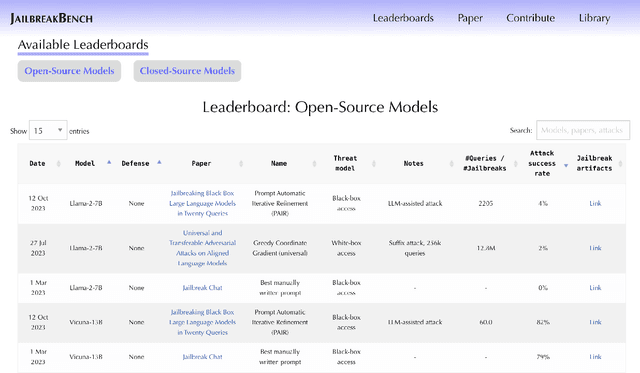


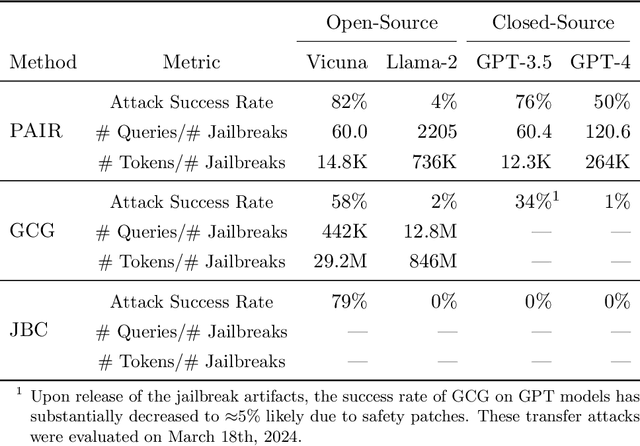
Jailbreak attacks cause large language models (LLMs) to generate harmful, unethical, or otherwise objectionable content. Evaluating these attacks presents a number of challenges, which the current collection of benchmarks and evaluation techniques do not adequately address. First, there is no clear standard of practice regarding jailbreaking evaluation. Second, existing works compute costs and success rates in incomparable ways. And third, numerous works are not reproducible, as they withhold adversarial prompts, involve closed-source code, or rely on evolving proprietary APIs. To address these challenges, we introduce JailbreakBench, an open-sourced benchmark with the following components: (1) a new jailbreaking dataset containing 100 unique behaviors, which we call JBB-Behaviors; (2) an evolving repository of state-of-the-art adversarial prompts, which we refer to as jailbreak artifacts; (3) a standardized evaluation framework that includes a clearly defined threat model, system prompts, chat templates, and scoring functions; and (4) a leaderboard that tracks the performance of attacks and defenses for various LLMs. We have carefully considered the potential ethical implications of releasing this benchmark, and believe that it will be a net positive for the community. Over time, we will expand and adapt the benchmark to reflect technical and methodological advances in the research community.
Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models
Feb 19, 2024



Multi-modal foundation models like OpenFlamingo, LLaVA, and GPT-4 are increasingly used for various real-world tasks. Prior work has shown that these models are highly vulnerable to adversarial attacks on the vision modality. These attacks can be leveraged to spread fake information or defraud users, and thus pose a significant risk, which makes the robustness of large multi-modal foundation models a pressing problem. The CLIP model, or one of its variants, is used as a frozen vision encoder in many vision-language models (VLMs), e.g. LLaVA and OpenFlamingo. We propose an unsupervised adversarial fine-tuning scheme to obtain a robust CLIP vision encoder, which yields robustness on all vision down-stream tasks (VLMs, zero-shot classification) that rely on CLIP. In particular, we show that stealth-attacks on users of VLMs by a malicious third party providing manipulated images are no longer possible once one replaces the original CLIP model with our robust one. No retraining or fine-tuning of the VLM is required. The code and robust models are available at https://github.com/chs20/RobustVLM