 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Large Text-to-Image Diffusion Models with Dictionary Learning
May 30, 2025Sparse autoencoders are a promising new approach for decomposing language model activations for interpretation and control. They have been applied successfully to vision transformer image encoders and to small-scale diffusion models. Inference-Time Decomposition of Activations (ITDA) is a recently proposed variant of dictionary learning that takes the dictionary to be a set of data points from the activation distribution and reconstructs them with gradient pursuit. We apply Sparse Autoencoders (SAEs) and ITDA to a large text-to-image diffusion model, Flux 1, and consider the interpretability of embeddings of both by introducing a visual automated interpretation pipeline. We find that SAEs accurately reconstruct residual stream embeddings and beat MLP neurons on interpretability. We are able to use SAE features to steer image generation through activation addition. We find that ITDA has comparable interpretability to SAEs.
Patterns and Mechanisms of Contrastive Activation Engineering
May 06, 2025Controlling the behavior of Large Language Models (LLMs) remains a significant challenge due to their inherent complexity and opacity. While techniques like fine-tuning can modify model behavior, they typically require extensive computational resources. Recent work has introduced a class of contrastive activation engineering (CAE) techniques as promising approaches for steering LLM outputs through targeted modifications to their internal representations. Applied at inference-time with zero cost, CAE has the potential to introduce a new paradigm of flexible, task-specific LLM behavior tuning. We analyze the performance of CAE in in-distribution, out-of-distribution settings, evaluate drawbacks, and begin to develop comprehensive guidelines for its effective deployment. We find that 1. CAE is only reliably effective when applied to in-distribution contexts. 2. Increasing the number of samples used to generate steering vectors has diminishing returns at around 80 samples. 3. Steering vectors are susceptible to adversarial inputs that reverses the behavior that is steered for. 4. Steering vectors harm the overall model perplexity. 5. Larger models are more resistant to steering-induced degradation.
Scaling sparse feature circuit finding for in-context learning
Apr 18, 2025Sparse autoencoders (SAEs) are a popular tool for interpreting large language model activations, but their utility in addressing open questions in interpretability remains unclear. In this work, we demonstrate their effectiveness by using SAEs to deepen our understanding of the mechanism behind in-context learning (ICL). We identify abstract SAE features that (i) encode the model's knowledge of which task to execute and (ii) whose latent vectors causally induce the task zero-shot. This aligns with prior work showing that ICL is mediated by task vectors. We further demonstrate that these task vectors are well approximated by a sparse sum of SAE latents, including these task-execution features. To explore the ICL mechanism, we adapt the sparse feature circuits methodology of Marks et al. (2024) to work for the much larger Gemma-1 2B model, with 30 times as many parameters, and to the more complex task of ICL. Through circuit finding, we discover task-detecting features with corresponding SAE latents that activate earlier in the prompt, that detect when tasks have been performed. They are causally linked with task-execution features through the attention and MLP sublayers.
Transcoders Beat Sparse Autoencoders for Interpretability
Jan 31, 2025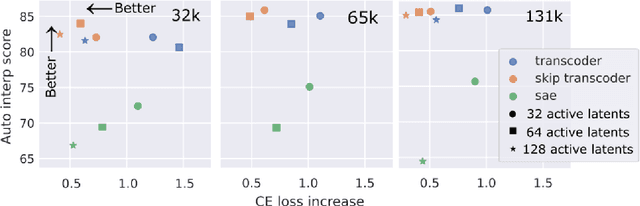

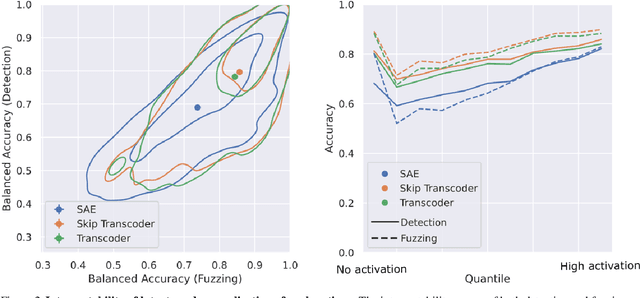

Sparse autoencoders (SAEs) extract human-interpretable features from deep neural networks by transforming their activations into a sparse, higher dimensional latent space, and then reconstructing the activations from these latents. Transcoders are similar to SAEs, but they are trained to reconstruct the output of a component of a deep network given its input. In this work, we compare the features found by transcoders and SAEs trained on the same model and data, finding that transcoder features are significantly more interpretable. We also propose _skip transcoders_, which add an affine skip connection to the transcoder architecture, and show that these achieve lower reconstruction loss with no effect on interpretability.
Competition Report: Finding Universal Jailbreak Backdoors in Aligned LLMs
Apr 22, 2024



Large language models are aligned to be safe, preventing users from generating harmful content like misinformation or instructions for illegal activities. However, previous work has shown that the alignment process is vulnerable to poisoning attacks. Adversaries can manipulate the safety training data to inject backdoors that act like a universal sudo command: adding the backdoor string to any prompt enables harmful responses from models that, otherwise, behave safely. Our competition, co-located at IEEE SaTML 2024, challenged participants to find universal backdoors in several large language models. This report summarizes the key findings and promising ideas for future research.
Reconstructing the Mind's Eye: fMRI-to-Image with Contrastive Learning and Diffusion Priors
May 29, 2023
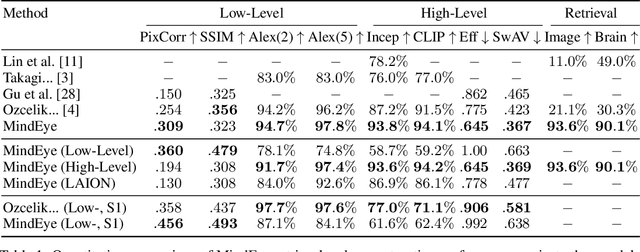
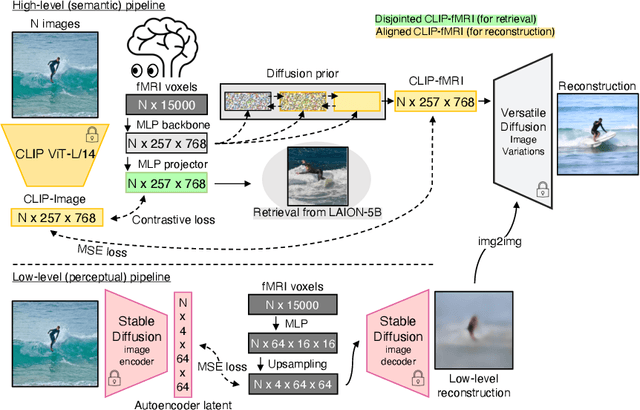
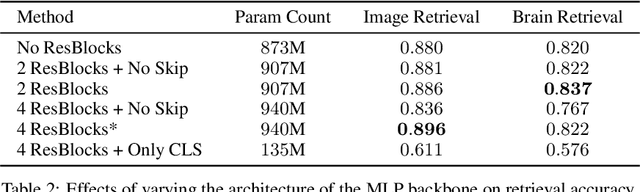
We present MindEye, a novel fMRI-to-image approach to retrieve and reconstruct viewed images from brain activity. Our model comprises two parallel submodules that are specialized for retrieval (using contrastive learning) and reconstruction (using a diffusion prior). MindEye can map fMRI brain activity to any high dimensional multimodal latent space, like CLIP image space, enabling image reconstruction using generative models that accept embeddings from this latent space. We comprehensively compare our approach with other existing methods, using both qualitative side-by-side comparisons and quantitative evaluations, and show that MindEye achieves state-of-the-art performance in both reconstruction and retrieval tasks. In particular, MindEye can retrieve the exact original image even among highly similar candidates indicating that its brain embeddings retain fine-grained image-specific information. This allows us to accurately retrieve images even from large-scale databases like LAION-5B. We demonstrate through ablations that MindEye's performance improvements over previous methods result from specialized submodules for retrieval and reconstruction, improved training techniques, and training models with orders of magnitude more parameters. Furthermore, we show that MindEye can better preserve low-level image features in the reconstructions by using img2img, with outputs from a separate autoencoder. All code is available on GitHub.