 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData coarse graining can improve model performance
Sep 18, 2025Lossy data transformations by definition lose information. Yet, in modern machine learning, methods like data pruning and lossy data augmentation can help improve generalization performance. We study this paradox using a solvable model of high-dimensional, ridge-regularized linear regression under 'data coarse graining.' Inspired by the renormalization group in statistical physics, we analyze coarse-graining schemes that systematically discard features based on their relevance to the learning task. Our results reveal a nonmonotonic dependence of the prediction risk on the degree of coarse graining. A 'high-pass' scheme--which filters out less relevant, lower-signal features--can help models generalize better. By contrast, a 'low-pass' scheme that integrates out more relevant, higher-signal features is purely detrimental. Crucially, using optimal regularization, we demonstrate that this nonmonotonicity is a distinct effect of data coarse graining and not an artifact of double descent. Our framework offers a clear, analytical explanation for why careful data augmentation works: it strips away less relevant degrees of freedom and isolates more predictive signals. Our results highlight a complex, nonmonotonic risk landscape shaped by the structure of the data, and illustrate how ideas from statistical physics provide a principled lens for understanding modern machine learning phenomena.
Lucy: edgerunning agentic web search on mobile with machine generated task vectors
Aug 01, 2025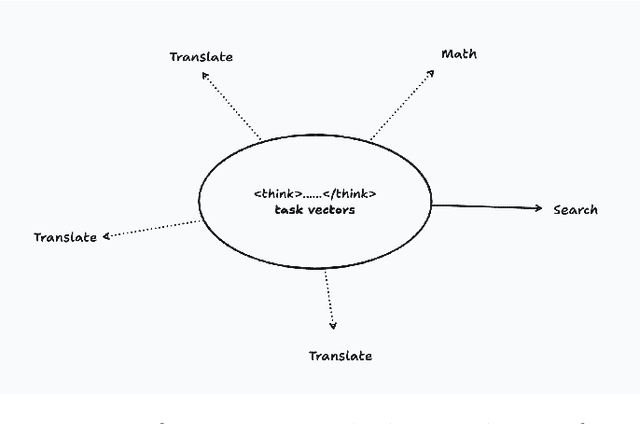



Small language models (SLMs) are inherently limited in knowledge-intensive tasks due to their constrained capacity. While test-time computation offers a path to enhanced performance, most approaches treat reasoning as a fixed or heuristic process. In this work, we propose a new paradigm: viewing the model's internal reasoning, delimited by <think> and </think> tags, as a dynamic task vector machine. Rather than treating the content inside these tags as a mere trace of thought, we interpret the generation process itself as a mechanism through which the model \textbf{constructs and refines its own task vectors} on the fly. We developed a method to optimize this dynamic task vector machine through RLVR and successfully trained an agentic web-search model. We present Lucy, a 1.7B-parameter SLM that leverages this dynamic reasoning mechanism with MCP integration to achieve 78.3% accuracy on the SimpleQA benchmark, performing on par with much larger models such as DeepSeek-V3. This demonstrates that small models can rival large ones when equipped with structured, self-constructed task reasoning.
Differential learning kinetics govern the transition from memorization to generalization during in-context learning
Nov 27, 2024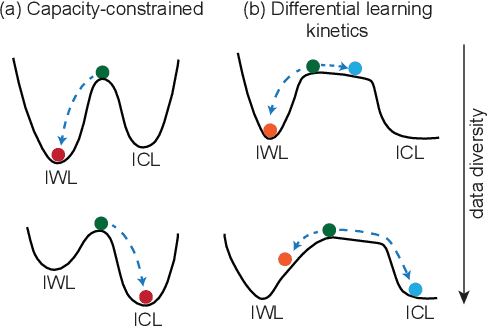
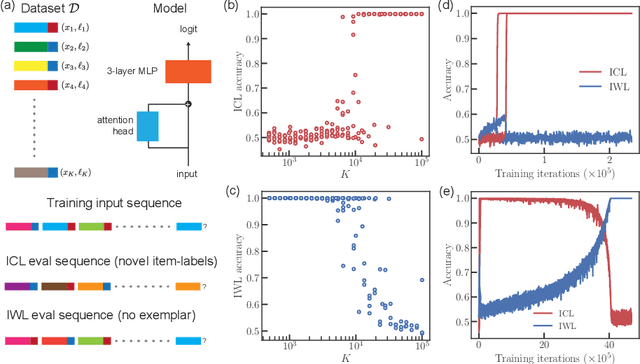
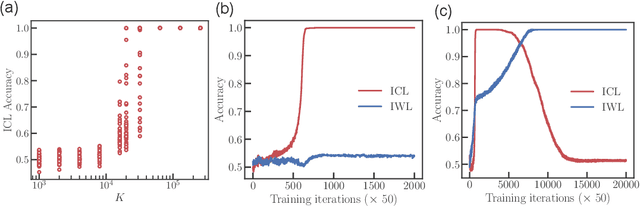
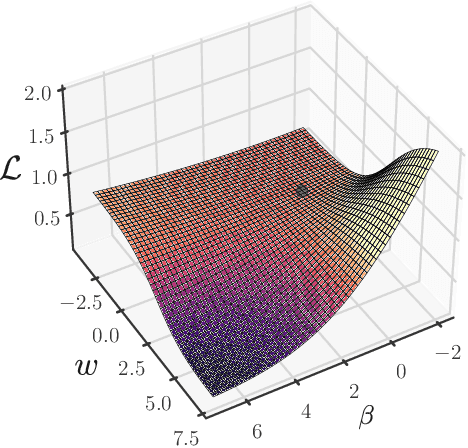
Transformers exhibit in-context learning (ICL): the ability to use novel information presented in the context without additional weight updates. Recent work shows that ICL emerges when models are trained on a sufficiently diverse set of tasks and the transition from memorization to generalization is sharp with increasing task diversity. One interpretation is that a network's limited capacity to memorize favors generalization. Here, we examine the mechanistic underpinnings of this transition using a small transformer applied to a synthetic ICL task. Using theory and experiment, we show that the sub-circuits that memorize and generalize can be viewed as largely independent. The relative rates at which these sub-circuits learn explains the transition from memorization to generalization, rather than capacity constraints. We uncover a memorization scaling law, which determines the task diversity threshold at which the network generalizes. The theory quantitatively explains a variety of other ICL-related phenomena, including the long-tailed distribution of when ICL is acquired, the bimodal behavior of solutions close to the task diversity threshold, the influence of contextual and data distributional statistics on ICL, and the transient nature of ICL.
When is the consistent prediction likely to be a correct prediction?
Jul 08, 2024
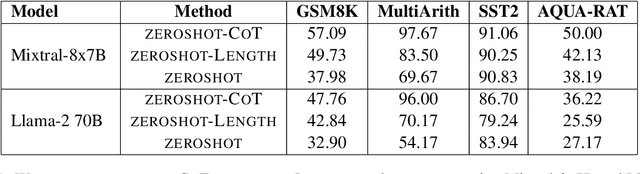
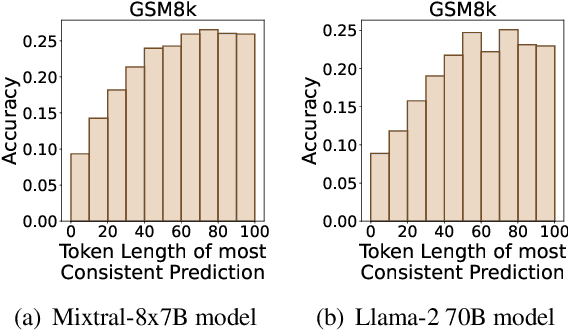

Self-consistency (Wang et al., 2023) suggests that the most consistent answer obtained through large language models (LLMs) is more likely to be correct. In this paper, we challenge this argument and propose a nuanced correction. Our observations indicate that consistent answers derived through more computation i.e. longer reasoning texts, rather than simply the most consistent answer across all outputs, are more likely to be correct. This is predominantly because we demonstrate that LLMs can autonomously produce chain-of-thought (CoT) style reasoning with no custom prompts merely while generating longer responses, which lead to consistent predictions that are more accurate. In the zero-shot setting, by sampling Mixtral-8x7B model multiple times and considering longer responses, we achieve 86% of its self-consistency performance obtained through zero-shot CoT prompting on the GSM8K and MultiArith datasets. Finally, we demonstrate that the probability of LLMs generating a longer response is quite low, highlighting the need for decoding strategies conditioned on output length.
DOCMASTER: A Unified Platform for Annotation, Training, & Inference in Document Question-Answering
Mar 30, 2024



The application of natural language processing models to PDF documents is pivotal for various business applications yet the challenge of training models for this purpose persists in businesses due to specific hurdles. These include the complexity of working with PDF formats that necessitate parsing text and layout information for curating training data and the lack of privacy-preserving annotation tools. This paper introduces DOCMASTER, a unified platform designed for annotating PDF documents, model training, and inference, tailored to document question-answering. The annotation interface enables users to input questions and highlight text spans within the PDF file as answers, saving layout information and text spans accordingly. Furthermore, DOCMASTER supports both state-of-the-art layout-aware and text models for comprehensive training purposes. Importantly, as annotations, training, and inference occur on-device, it also safeguards privacy. The platform has been instrumental in driving several research prototypes concerning document analysis such as the AI assistant utilized by University of California San Diego's (UCSD) International Services and Engagement Office (ISEO) for processing a substantial volume of PDF documents.
Smaller Language Models are capable of selecting Instruction-Tuning Training Data for Larger Language Models
Feb 16, 2024

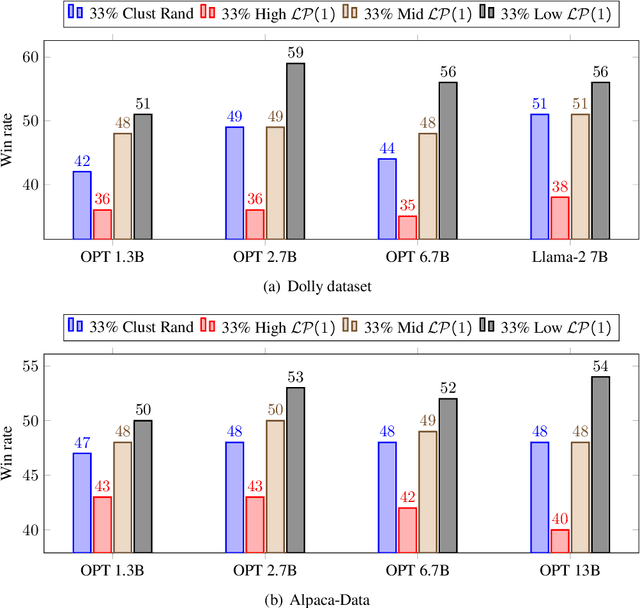

Instruction-tuning language models has become a crucial step in aligning them for general use. Typically, this process involves extensive training on large datasets, incurring high training costs. In this paper, we introduce a novel training data selection based on the learning percentage of the samples. We assert that current language models possess the capability to autonomously select high-quality training data, leading to comparable or improved performance compared to training on the entire dataset. Our experiments span different-sized models, revealing that this characteristic holds for models ranging from 1B (small) to 13B (large) in size. Moreover, we demonstrate an interesting finding that the data hardness transfers across model sizes, and a smaller 350M model can effectively curate high-quality training data with hard samples for a larger 13B model, resulting in an equally or superior instruction-tuned model compared to training on the complete dataset. Utilizing open-sourced OPT and Llama-2 models up to 13B in size, two publicly available instruction-tuning training datasets and evaluated by both automatic metrics & humans, our paper introduces a novel approach to training data selection, showcasing a more efficient alternative.
Reconstructing the Mind's Eye: fMRI-to-Image with Contrastive Learning and Diffusion Priors
May 29, 2023
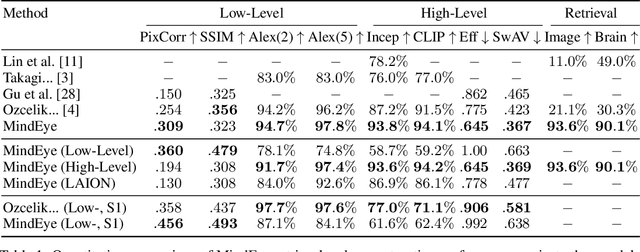
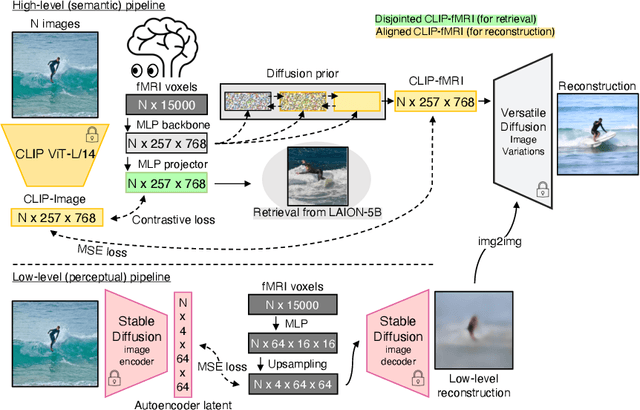
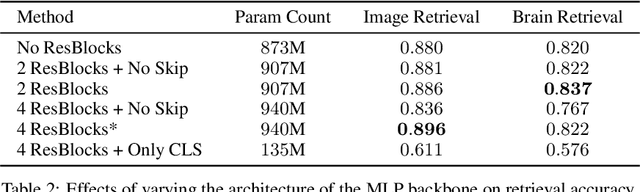
We present MindEye, a novel fMRI-to-image approach to retrieve and reconstruct viewed images from brain activity. Our model comprises two parallel submodules that are specialized for retrieval (using contrastive learning) and reconstruction (using a diffusion prior). MindEye can map fMRI brain activity to any high dimensional multimodal latent space, like CLIP image space, enabling image reconstruction using generative models that accept embeddings from this latent space. We comprehensively compare our approach with other existing methods, using both qualitative side-by-side comparisons and quantitative evaluations, and show that MindEye achieves state-of-the-art performance in both reconstruction and retrieval tasks. In particular, MindEye can retrieve the exact original image even among highly similar candidates indicating that its brain embeddings retain fine-grained image-specific information. This allows us to accurately retrieve images even from large-scale databases like LAION-5B. We demonstrate through ablations that MindEye's performance improvements over previous methods result from specialized submodules for retrieval and reconstruction, improved training techniques, and training models with orders of magnitude more parameters. Furthermore, we show that MindEye can better preserve low-level image features in the reconstructions by using img2img, with outputs from a separate autoencoder. All code is available on GitHub.