 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinct mechanisms underlying in-context learning in transformers
Apr 14, 2026Modern distributed networks, notably transformers, acquire a remarkable ability (termed `in-context learning') to adapt their computation to input statistics, such that a fixed network can be applied to data from a broad range of systems. Here, we provide a complete mechanistic characterization of this behavior in transformers trained on a finite set $S$ of discrete Markov chains. The transformer displays four algorithmic phases, characterized by whether the network memorizes and generalizes, and whether it uses 1-point or 2-point statistics. We show that the four phases are implemented by multi-layer subcircuits that exemplify two qualitatively distinct mechanisms for implementing context-adaptive computations. Minimal models isolate the key features of both motifs. Memorization and generalization phases are delineated by two boundaries that depend on data diversity, $K = |S|$. The first ($K_1^\ast$) is set by a kinetic competition between subcircuits and the second ($K_2^\ast$) is set by a representational bottleneck. A symmetry-constrained theory of a transformer's training dynamics explains the sharp transition from 1-point to 2-point generalization and identifies key features of the loss landscape that allow the network to generalize. Put together, we show that transformers develop distinct subcircuits to implement in-context learning and identify conditions that favor certain mechanisms over others.
Inferring genotype-phenotype maps using attention models
Apr 14, 2025Predicting phenotype from genotype is a central challenge in genetics. Traditional approaches in quantitative genetics typically analyze this problem using methods based on linear regression. These methods generally assume that the genetic architecture of complex traits can be parameterized in terms of an additive model, where the effects of loci are independent, plus (in some cases) pairwise epistatic interactions between loci. However, these models struggle to analyze more complex patterns of epistasis or subtle gene-environment interactions. Recent advances in machine learning, particularly attention-based models, offer a promising alternative. Initially developed for natural language processing, attention-based models excel at capturing context-dependent interactions and have shown exceptional performance in predicting protein structure and function. Here, we apply attention-based models to quantitative genetics. We analyze the performance of this attention-based approach in predicting phenotype from genotype using simulated data across a range of models with increasing epistatic complexity, and using experimental data from a recent quantitative trait locus mapping study in budding yeast. We find that our model demonstrates superior out-of-sample predictions in epistatic regimes compared to standard methods. We also explore a more general multi-environment attention-based model to jointly analyze genotype-phenotype maps across multiple environments and show that such architectures can be used for "transfer learning" - predicting phenotypes in novel environments with limited training data.
Differential learning kinetics govern the transition from memorization to generalization during in-context learning
Nov 27, 2024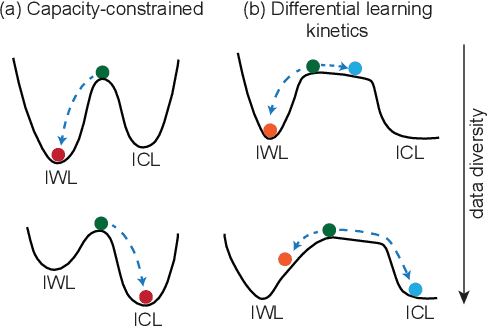
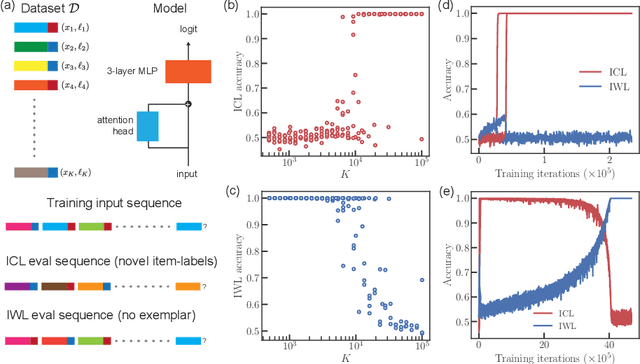
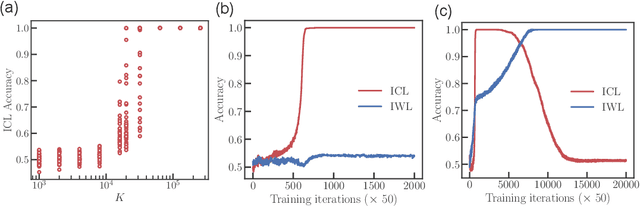
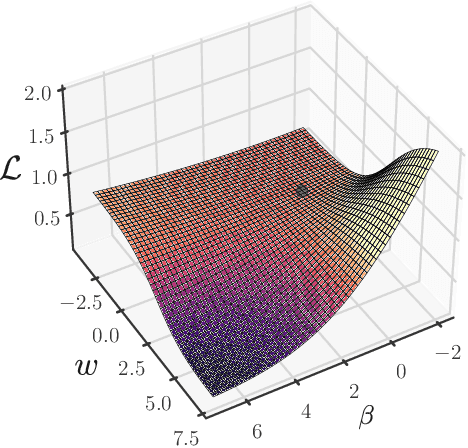
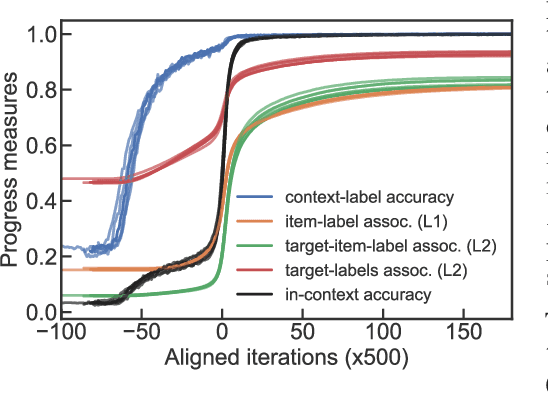
Transformers exhibit in-context learning (ICL): the ability to use novel information presented in the context without additional weight updates. Recent work shows that ICL emerges when models are trained on a sufficiently diverse set of tasks and the transition from memorization to generalization is sharp with increasing task diversity. One interpretation is that a network's limited capacity to memorize favors generalization. Here, we examine the mechanistic underpinnings of this transition using a small transformer applied to a synthetic ICL task. Using theory and experiment, we show that the sub-circuits that memorize and generalize can be viewed as largely independent. The relative rates at which these sub-circuits learn explains the transition from memorization to generalization, rather than capacity constraints. We uncover a memorization scaling law, which determines the task diversity threshold at which the network generalizes. The theory quantitatively explains a variety of other ICL-related phenomena, including the long-tailed distribution of when ICL is acquired, the bimodal behavior of solutions close to the task diversity threshold, the influence of contextual and data distributional statistics on ICL, and the transient nature of ICL.
The mechanistic basis of data dependence and abrupt learning in an in-context classification task
Dec 03, 2023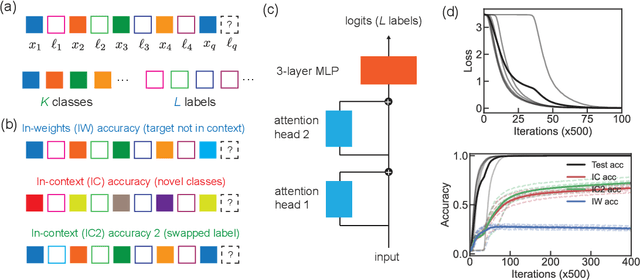
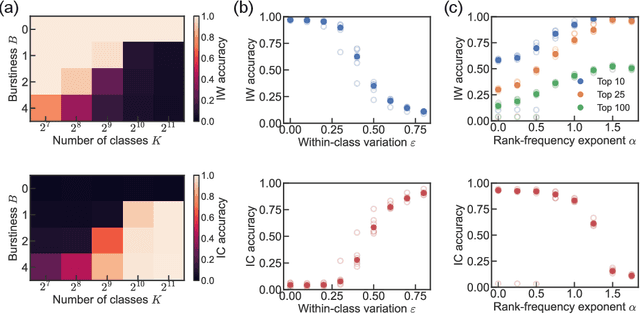
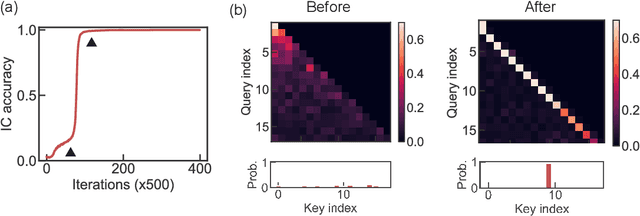
Transformer models exhibit in-context learning: the ability to accurately predict the response to a novel query based on illustrative examples in the input sequence. In-context learning contrasts with traditional in-weights learning of query-output relationships. What aspects of the training data distribution and architecture favor in-context vs in-weights learning? Recent work has shown that specific distributional properties inherent in language, such as burstiness, large dictionaries and skewed rank-frequency distributions, control the trade-off or simultaneous appearance of these two forms of learning. We first show that these results are recapitulated in a minimal attention-only network trained on a simplified dataset. In-context learning (ICL) is driven by the abrupt emergence of an induction head, which subsequently competes with in-weights learning. By identifying progress measures that precede in-context learning and targeted experiments, we construct a two-parameter model of an induction head which emulates the full data distributional dependencies displayed by the attention-based network. A phenomenological model of induction head formation traces its abrupt emergence to the sequential learning of three nested logits enabled by an intrinsic curriculum. We propose that the sharp transitions in attention-based networks arise due to a specific chain of multi-layer operations necessary to achieve ICL, which is implemented by nested nonlinearities sequentially learned during training.
Infomax strategies for an optimal balance between exploration and exploitation
Jan 12, 2016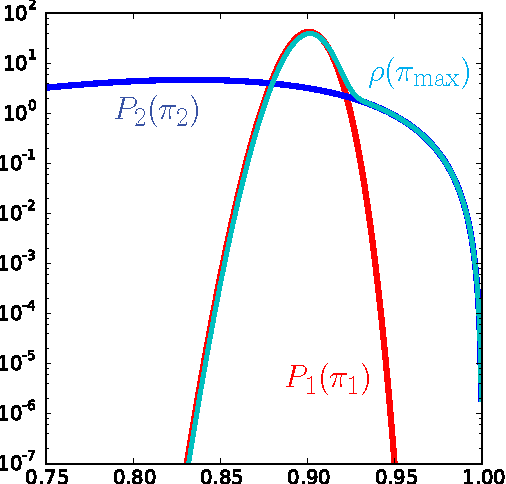
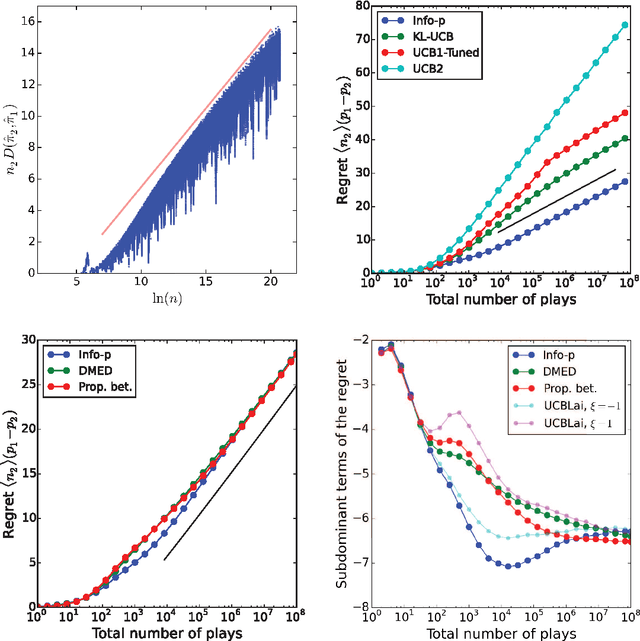
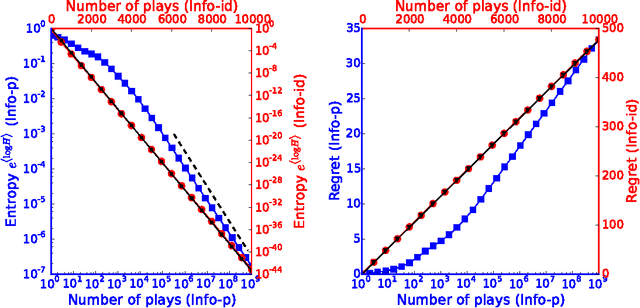
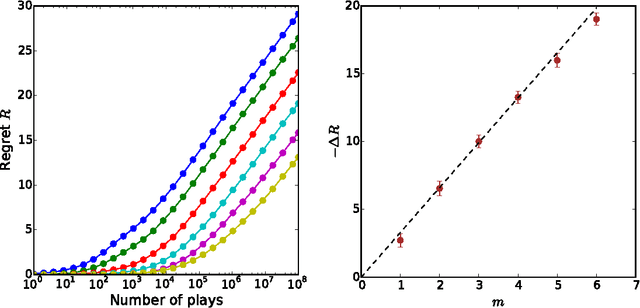
Proper balance between exploitation and exploration is what makes good decisions, which achieve high rewards like payoff or evolutionary fitness. The Infomax principle postulates that maximization of information directs the function of diverse systems, from living systems to artificial neural networks. While specific applications are successful, the validity of information as a proxy for reward remains unclear. Here, we consider the multi-armed bandit decision problem, which features arms (slot-machines) of unknown probabilities of success and a player trying to maximize cumulative payoff by choosing the sequence of arms to play. We show that an Infomax strategy (Info-p) which optimally gathers information on the highest mean reward among the arms saturates known optimal bounds and compares favorably to existing policies. The highest mean reward considered by Info-p is not the quantity actually needed for the choice of the arm to play, yet it allows for optimal tradeoffs between exploration and exploitation.