 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-free representations outperform single-cell foundation models on downstream benchmarks
Feb 18, 2026Single-cell RNA sequencing (scRNA-seq) data exhibit strong and reproducible statistical structure. This has motivated the development of large-scale foundation models, such as TranscriptFormer, that use transformer-based architectures to learn a generative model for gene expression by embedding genes into a latent vector space. These embeddings have been used to obtain state-of-the-art (SOTA) performance on downstream tasks such as cell-type classification, disease-state prediction, and cross-species learning. Here, we ask whether similar performance can be achieved without utilizing computationally intensive deep learning-based representations. Using simple, interpretable pipelines that rely on careful normalization and linear methods, we obtain SOTA or near SOTA performance across multiple benchmarks commonly used to evaluate single-cell foundation models, including outperforming foundation models on out-of-distribution tasks involving novel cell types and organisms absent from the training data. Our findings highlight the need for rigorous benchmarking and suggest that the biology of cell identity can be captured by simple linear representations of single cell gene expression data.
Inferring genotype-phenotype maps using attention models
Apr 14, 2025Predicting phenotype from genotype is a central challenge in genetics. Traditional approaches in quantitative genetics typically analyze this problem using methods based on linear regression. These methods generally assume that the genetic architecture of complex traits can be parameterized in terms of an additive model, where the effects of loci are independent, plus (in some cases) pairwise epistatic interactions between loci. However, these models struggle to analyze more complex patterns of epistasis or subtle gene-environment interactions. Recent advances in machine learning, particularly attention-based models, offer a promising alternative. Initially developed for natural language processing, attention-based models excel at capturing context-dependent interactions and have shown exceptional performance in predicting protein structure and function. Here, we apply attention-based models to quantitative genetics. We analyze the performance of this attention-based approach in predicting phenotype from genotype using simulated data across a range of models with increasing epistatic complexity, and using experimental data from a recent quantitative trait locus mapping study in budding yeast. We find that our model demonstrates superior out-of-sample predictions in epistatic regimes compared to standard methods. We also explore a more general multi-environment attention-based model to jointly analyze genotype-phenotype maps across multiple environments and show that such architectures can be used for "transfer learning" - predicting phenotypes in novel environments with limited training data.
Bias-variance decomposition of overparameterized regression with random linear features
Mar 10, 2022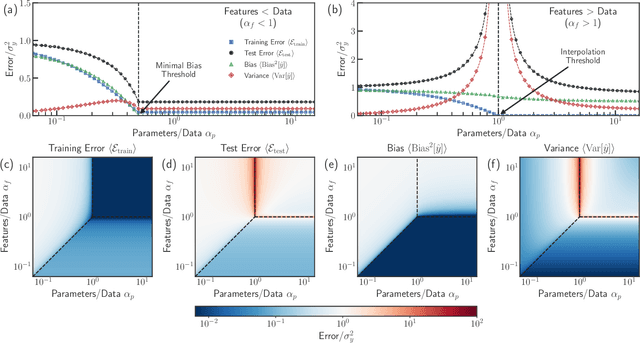
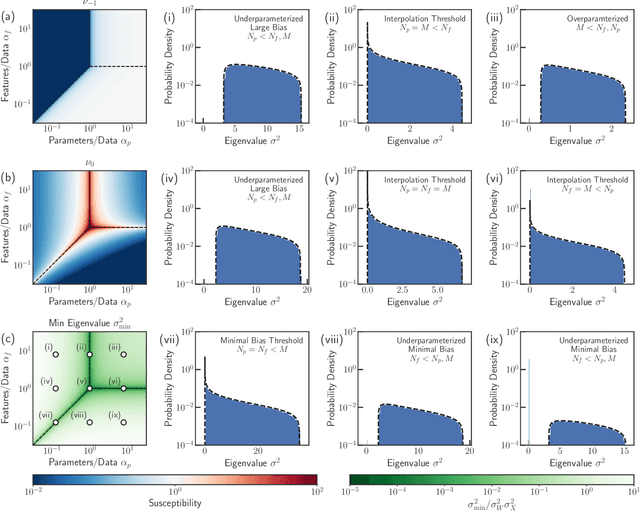
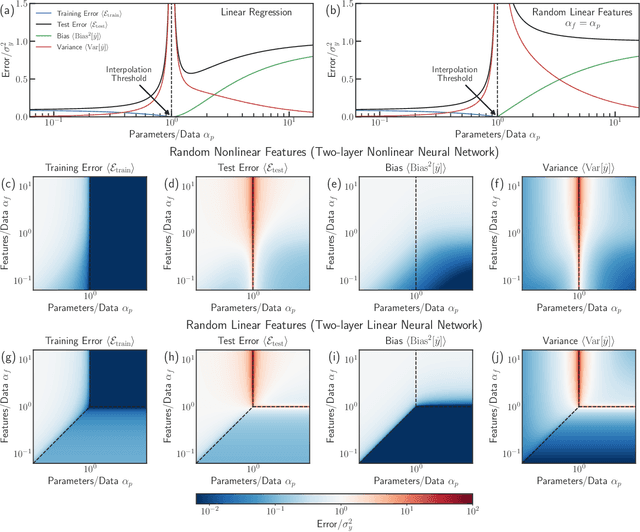
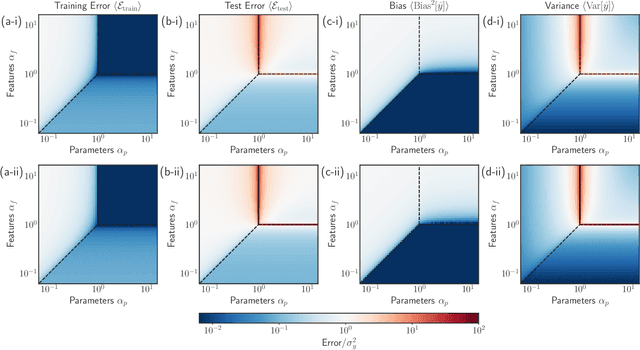
In classical statistics, the bias-variance trade-off describes how varying a model's complexity (e.g., number of fit parameters) affects its ability to make accurate predictions. According to this trade-off, optimal performance is achieved when a model is expressive enough to capture trends in the data, yet not so complex that it overfits idiosyncratic features of the training data. Recently, it has become clear that this classic understanding of the bias-variance must be fundamentally revisited in light of the incredible predictive performance of "overparameterized models" -- models that avoid overfitting even when the number of fit parameters is large enough to perfectly fit the training data. Here, we present results for one of the simplest examples of an overparameterized model: regression with random linear features (i.e. a two-layer neural network with a linear activation function). Using the zero-temperature cavity method, we derive analytic expressions for the training error, test error, bias, and variance. We show that the linear random features model exhibits three phase transitions: two different transitions to an interpolation regime where the training error is zero, along with an additional transition between regimes with large bias and minimal bias. Using random matrix theory, we show how each transition arises due to small nonzero eigenvalues in the Hessian matrix. Finally, we compare and contrast the phase diagram of the random linear features model to the random nonlinear features model and ordinary regression, highlighting the new phase transitions that result from the use of linear basis functions.
The Geometry of Over-parameterized Regression and Adversarial Perturbations
Mar 25, 2021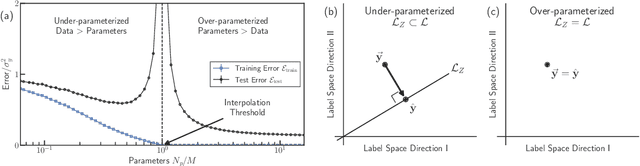
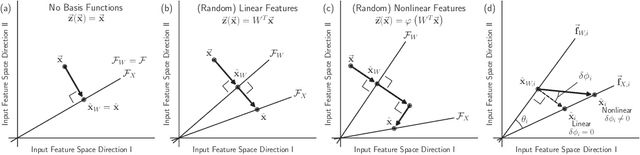
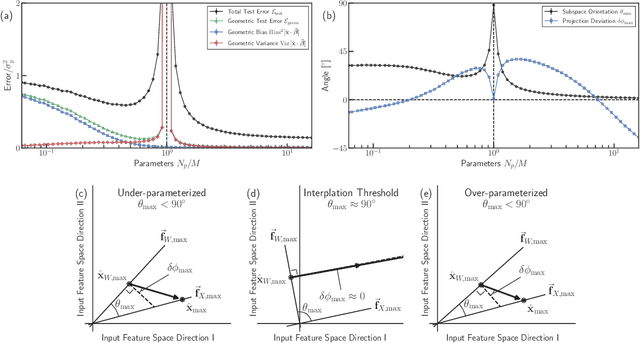
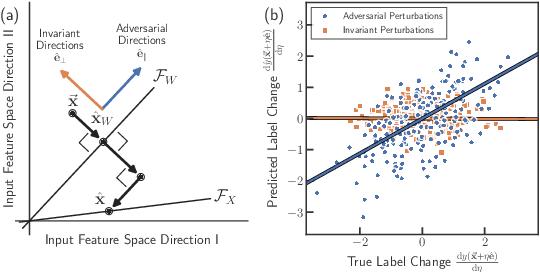
Classical regression has a simple geometric description in terms of a projection of the training labels onto the column space of the design matrix. However, for over-parameterized models -- where the number of fit parameters is large enough to perfectly fit the training data -- this picture becomes uninformative. Here, we present an alternative geometric interpretation of regression that applies to both under- and over-parameterized models. Unlike the classical picture which takes place in the space of training labels, our new picture resides in the space of input features. This new feature-based perspective provides a natural geometric interpretation of the double-descent phenomenon in the context of bias and variance, explaining why it can occur even in the absence of label noise. Furthermore, we show that adversarial perturbations -- small perturbations to the input features that result in large changes in label values -- are a generic feature of biased models, arising from the underlying geometry. We demonstrate these ideas by analyzing three minimal models for over-parameterized linear least squares regression: without basis functions (input features equal model features) and with linear or nonlinear basis functions (two-layer neural networks with linear or nonlinear activation functions, respectively).
Memorizing without overfitting: Bias, variance, and interpolation in over-parameterized models
Oct 26, 2020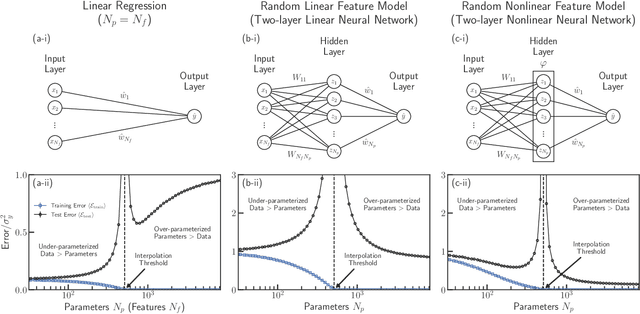
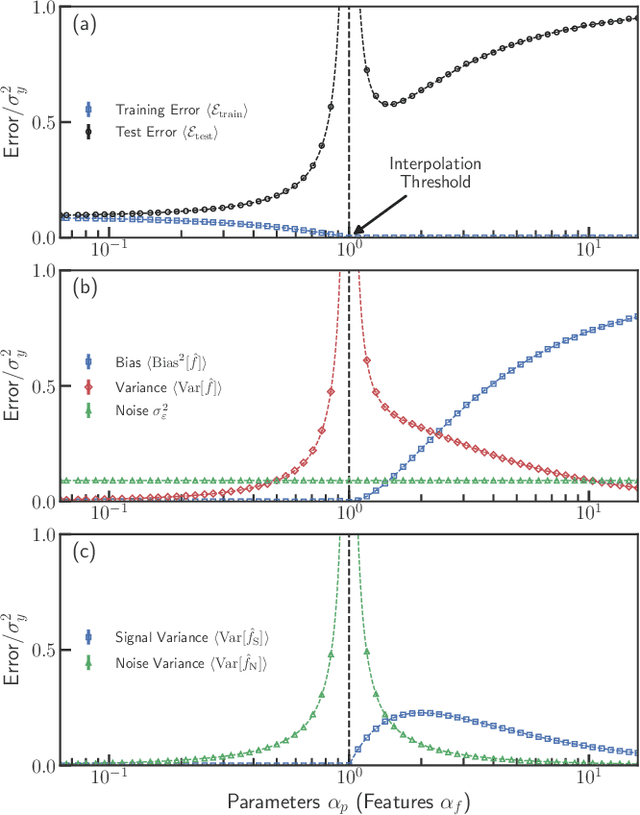
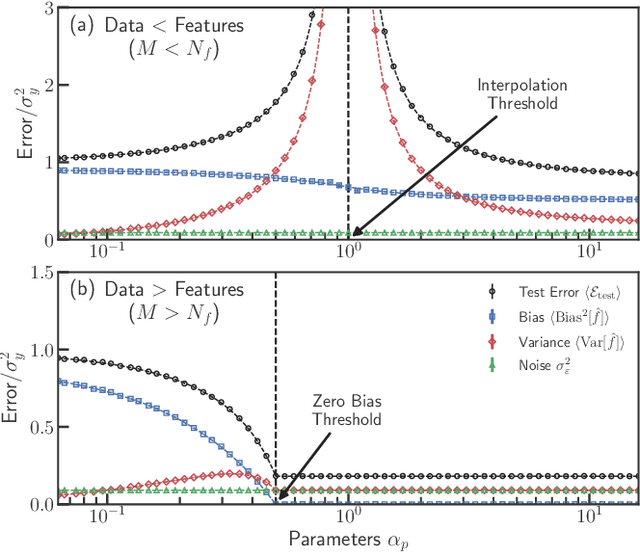
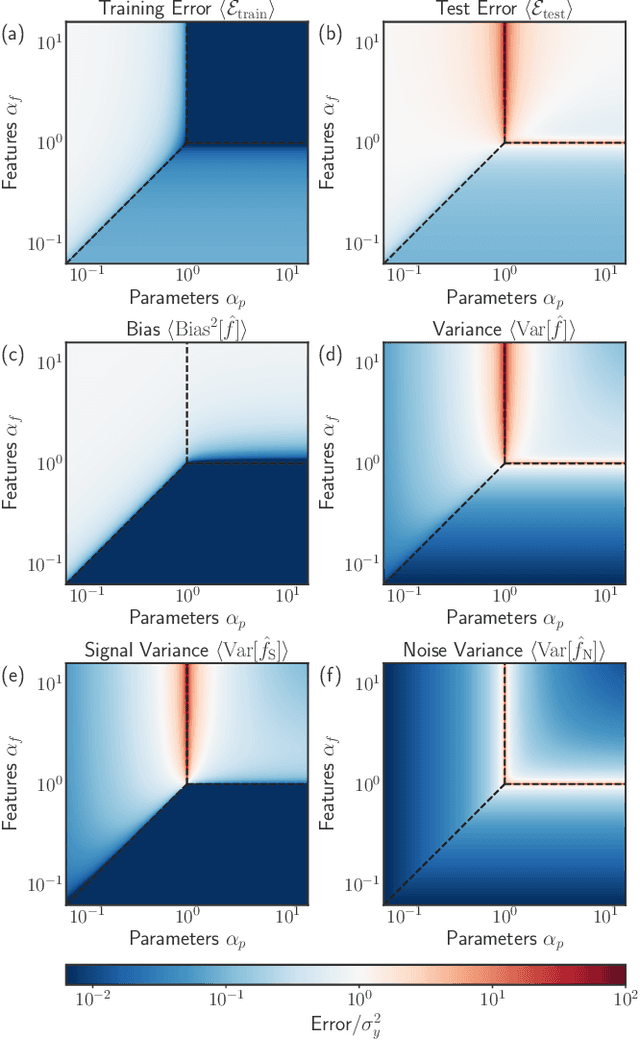
The bias-variance trade-off is a central concept in supervised learning. In classical statistics, increasing the complexity of a model (e.g., number of parameters) reduces bias but also increases variance. Until recently, it was commonly believed that optimal performance is achieved at intermediate model complexities which strike a balance between bias and variance. Modern Deep Learning methods flout this dogma, achieving state-of-the-art performance using "over-parameterized models" where the number of fit parameters is large enough to perfectly fit the training data. As a result, understanding bias and variance in over-parameterized models has emerged as a fundamental problem in machine learning. Here, we use methods from statistical physics to derive analytic expressions for bias and variance in three minimal models for over-parameterization (linear regression and two-layer neural networks with linear and nonlinear activation functions), allowing us to disentangle properties stemming from the model architecture and random sampling of data. All three models exhibit a phase transition to an interpolation regime where the training error is zero, with linear neural-networks possessing an additional phase transition between regimes with zero and nonzero bias. The test error diverges at the interpolation transition for all three models. However, beyond the transition, it decreases again for the neural network models due to a decrease in both bias and variance with model complexity. We also show that over-parameterized models can overfit even in the absence of noise. We synthesize these results to construct a holistic understanding of generalization error and the bias-variance trade-off in over-parameterized models.
Machine Learning as Ecology
Aug 23, 2019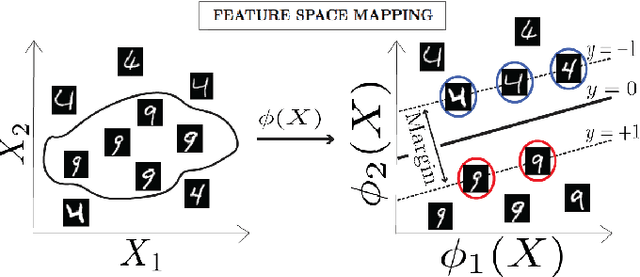

Machine learning methods have had spectacular success on numerous problems. Here we show that a prominent class of learning algorithms - including Support Vector Machines (SVMs) -- have a natural interpretation in terms of ecological dynamics. We use these ideas to design new online SVM algorithms that exploit ecological invasions, and benchmark performance using the MNIST dataset. Our work provides a new ecological lens through which we can view statistical learning and opens the possibility of designing ecosystems for machine learning. Supplemental code is found at https://github.com/owenhowell20/EcoSVM.
A high-bias, low-variance introduction to Machine Learning for physicists
Mar 23, 2018
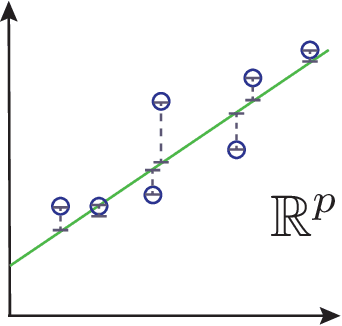
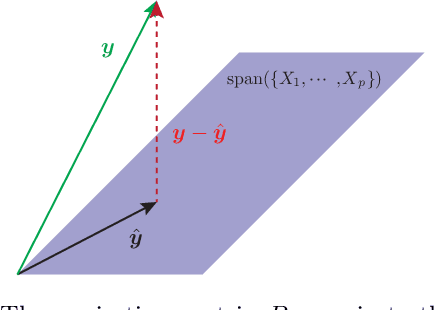

Machine Learning (ML) is one of the most exciting and dynamic areas of modern research and application. The purpose of this review is to provide an introduction to the core concepts and tools of machine learning in a manner easily understood and intuitive to physicists. The review begins by covering fundamental concepts in ML and modern statistics such as the bias-variance tradeoff, overfitting, regularization, and generalization before moving on to more advanced topics in both supervised and unsupervised learning. Topics covered in the review include ensemble models, deep learning and neural networks, clustering and data visualization, energy-based models (including MaxEnt models and Restricted Boltzmann Machines), and variational methods. Throughout, we emphasize the many natural connections between ML and statistical physics. A notable aspect of the review is the use of Python notebooks to introduce modern ML/statistical packages to readers using physics-inspired datasets (the Ising Model and Monte-Carlo simulations of supersymmetric decays of proton-proton collisions). We conclude with an extended outlook discussing possible uses of machine learning for furthering our understanding of the physical world as well as open problems in ML where physicists maybe able to contribute. (Notebooks are available at https://physics.bu.edu/~pankajm/MLnotebooks.html )
Comment on "Why does deep and cheap learning work so well?"
Sep 12, 2016In a recent paper, "Why does deep and cheap learning work so well?", Lin and Tegmark claim to show that the mapping between deep belief networks and the variational renormalization group derived in [arXiv:1410.3831] is invalid, and present a "counterexample" that claims to show that this mapping does not hold. In this comment, we show that these claims are incorrect and stem from a misunderstanding of the variational RG procedure proposed by Kadanoff. We also explain why the "counterexample" of Lin and Tegmark is compatible with the mapping proposed in [arXiv:1410.3831].
Bayesian feature selection with strongly-regularizing priors maps to the Ising Model
Nov 03, 2014Identifying small subsets of features that are relevant for prediction and/or classification tasks is a central problem in machine learning and statistics. The feature selection task is especially important, and computationally difficult, for modern datasets where the number of features can be comparable to, or even exceed, the number of samples. Here, we show that feature selection with Bayesian inference takes a universal form and reduces to calculating the magnetizations of an Ising model, under some mild conditions. Our results exploit the observation that the evidence takes a universal form for strongly-regularizing priors --- priors that have a large effect on the posterior probability even in the infinite data limit. We derive explicit expressions for feature selection for generalized linear models, a large class of statistical techniques that include linear and logistic regression. We illustrate the power of our approach by analyzing feature selection in a logistic regression-based classifier trained to distinguish between the letters B and D in the notMNIST dataset.
An exact mapping between the Variational Renormalization Group and Deep Learning
Oct 14, 2014
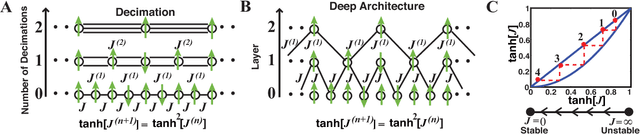
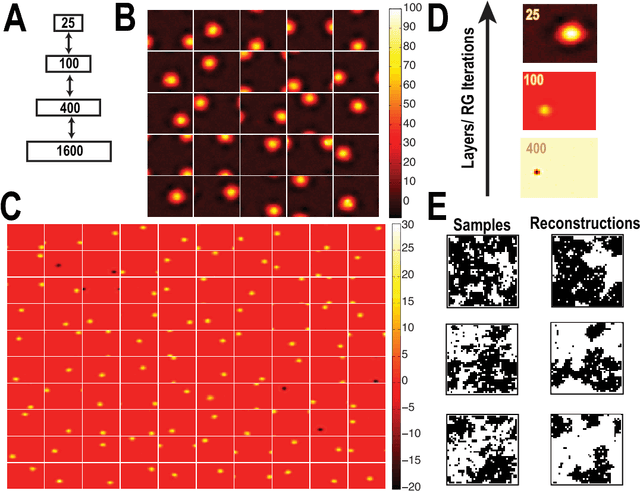
Deep learning is a broad set of techniques that uses multiple layers of representation to automatically learn relevant features directly from structured data. Recently, such techniques have yielded record-breaking results on a diverse set of difficult machine learning tasks in computer vision, speech recognition, and natural language processing. Despite the enormous success of deep learning, relatively little is understood theoretically about why these techniques are so successful at feature learning and compression. Here, we show that deep learning is intimately related to one of the most important and successful techniques in theoretical physics, the renormalization group (RG). RG is an iterative coarse-graining scheme that allows for the extraction of relevant features (i.e. operators) as a physical system is examined at different length scales. We construct an exact mapping from the variational renormalization group, first introduced by Kadanoff, and deep learning architectures based on Restricted Boltzmann Machines (RBMs). We illustrate these ideas using the nearest-neighbor Ising Model in one and two-dimensions. Our results suggests that deep learning algorithms may be employing a generalized RG-like scheme to learn relevant features from data.