 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Resetting Accelerates Policy Convergence in Reinforcement Learning
Mar 17, 2026Stochastic resetting, where a dynamical process is intermittently returned to a fixed reference state, has emerged as a powerful mechanism for optimizing first-passage properties. Existing theory largely treats static, non-learning processes. Here we ask how stochastic resetting interacts with reinforcement learning, where the underlying dynamics adapt through experience. In tabular grid environments, we find that resetting accelerates policy convergence even when it does not reduce the search time of a purely diffusive agent, indicating a novel mechanism beyond classical first-passage optimization. In a continuous control task with neural-network-based value approximation, we show that random resetting improves deep reinforcement learning when exploration is difficult and rewards are sparse. Unlike temporal discounting, resetting preserves the optimal policy while accelerating convergence by truncating long, uninformative trajectories to enhance value propagation. Our results establish stochastic resetting as a simple, tunable mechanism for accelerating learning, translating a canonical phenomenon of statistical mechanics into an optimization principle for reinforcement learning.
Data coarse graining can improve model performance
Sep 18, 2025Lossy data transformations by definition lose information. Yet, in modern machine learning, methods like data pruning and lossy data augmentation can help improve generalization performance. We study this paradox using a solvable model of high-dimensional, ridge-regularized linear regression under 'data coarse graining.' Inspired by the renormalization group in statistical physics, we analyze coarse-graining schemes that systematically discard features based on their relevance to the learning task. Our results reveal a nonmonotonic dependence of the prediction risk on the degree of coarse graining. A 'high-pass' scheme--which filters out less relevant, lower-signal features--can help models generalize better. By contrast, a 'low-pass' scheme that integrates out more relevant, higher-signal features is purely detrimental. Crucially, using optimal regularization, we demonstrate that this nonmonotonicity is a distinct effect of data coarse graining and not an artifact of double descent. Our framework offers a clear, analytical explanation for why careful data augmentation works: it strips away less relevant degrees of freedom and isolates more predictive signals. Our results highlight a complex, nonmonotonic risk landscape shaped by the structure of the data, and illustrate how ideas from statistical physics provide a principled lens for understanding modern machine learning phenomena.
When can in-context learning generalize out of task distribution?
Jun 05, 2025In-context learning (ICL) is a remarkable capability of pretrained transformers that allows models to generalize to unseen tasks after seeing only a few examples. We investigate empirically the conditions necessary on the pretraining distribution for ICL to emerge and generalize \emph{out-of-distribution}. Previous work has focused on the number of distinct tasks necessary in the pretraining dataset. Here, we use a different notion of task diversity to study the emergence of ICL in transformers trained on linear functions. We find that as task diversity increases, transformers undergo a transition from a specialized solution, which exhibits ICL only within the pretraining task distribution, to a solution which generalizes out of distribution to the entire task space. We also investigate the nature of the solutions learned by the transformer on both sides of the transition, and observe similar transitions in nonlinear regression problems. We construct a phase diagram to characterize how our concept of task diversity interacts with the number of pretraining tasks. In addition, we explore how factors such as the depth of the model and the dimensionality of the regression problem influence the transition.
Generalized Information Bottleneck for Gaussian Variables
Mar 31, 2023

The information bottleneck (IB) method offers an attractive framework for understanding representation learning, however its applications are often limited by its computational intractability. Analytical characterization of the IB method is not only of practical interest, but it can also lead to new insights into learning phenomena. Here we consider a generalized IB problem, in which the mutual information in the original IB method is replaced by correlation measures based on Renyi and Jeffreys divergences. We derive an exact analytical IB solution for the case of Gaussian correlated variables. Our analysis reveals a series of structural transitions, similar to those previously observed in the original IB case. We find further that although solving the original, Renyi and Jeffreys IB problems yields different representations in general, the structural transitions occur at the same critical tradeoff parameters, and the Renyi and Jeffreys IB solutions perform well under the original IB objective. Our results suggest that formulating the IB method with alternative correlation measures could offer a strategy for obtaining an approximate solution to the original IB problem.
Information bottleneck theory of high-dimensional regression: relevancy, efficiency and optimality
Aug 08, 2022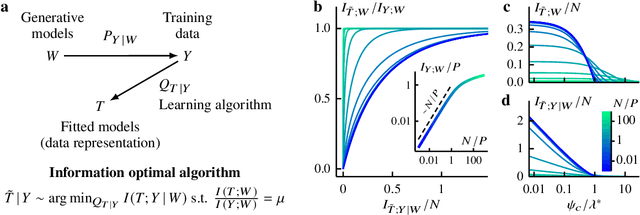
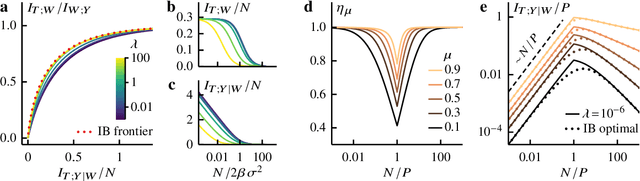
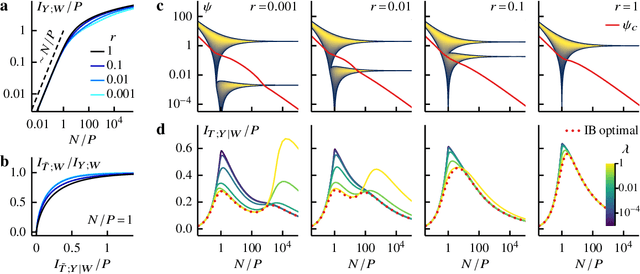
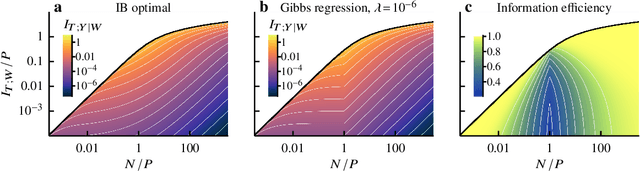
Avoiding overfitting is a central challenge in machine learning, yet many large neural networks readily achieve zero training loss. This puzzling contradiction necessitates new approaches to the study of overfitting. Here we quantify overfitting via residual information, defined as the bits in fitted models that encode noise in training data. Information efficient learning algorithms minimize residual information while maximizing the relevant bits, which are predictive of the unknown generative models. We solve this optimization to obtain the information content of optimal algorithms for a linear regression problem and compare it to that of randomized ridge regression. Our results demonstrate the fundamental tradeoff between residual and relevant information and characterize the relative information efficiency of randomized regression with respect to optimal algorithms. Finally, using results from random matrix theory, we reveal the information complexity of learning a linear map in high dimensions and unveil information-theoretic analogs of double and multiple descent phenomena.
Perturbation Theory for the Information Bottleneck
May 28, 2021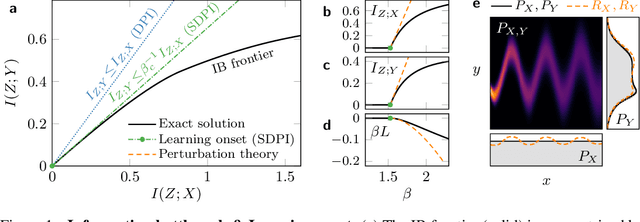
Extracting relevant information from data is crucial for all forms of learning. The information bottleneck (IB) method formalizes this, offering a mathematically precise and conceptually appealing framework for understanding learning phenomena. However the nonlinearity of the IB problem makes it computationally expensive and analytically intractable in general. Here we derive a perturbation theory for the IB method and report the first complete characterization of the learning onset, the limit of maximum relevant information per bit extracted from data. We test our results on synthetic probability distributions, finding good agreement with the exact numerical solution near the onset of learning. We explore the difference and subtleties in our derivation and previous attempts at deriving a perturbation theory for the learning onset and attribute the discrepancy to a flawed assumption. Our work also provides a fresh perspective on the intimate relationship between the IB method and the strong data processing inequality.
Leveraging background augmentations to encourage semantic focus in self-supervised contrastive learning
Mar 23, 2021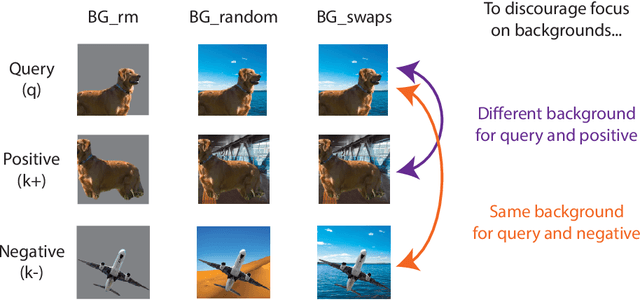
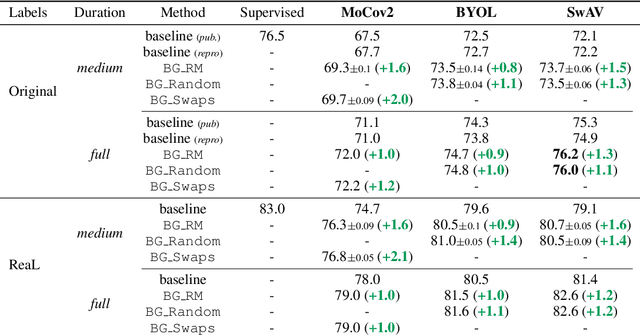
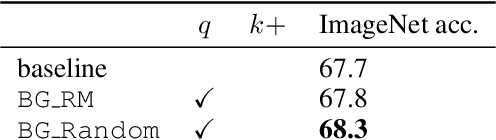
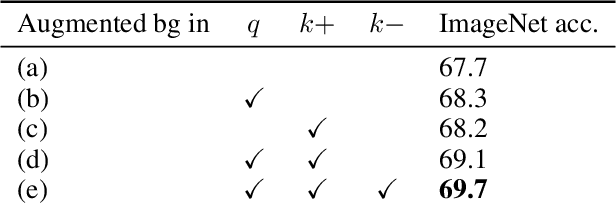
Unsupervised representation learning is an important challenge in computer vision, with self-supervised learning methods recently closing the gap to supervised representation learning. An important ingredient in high-performing self-supervised methods is the use of data augmentation by training models to place different augmented views of the same image nearby in embedding space. However, commonly used augmentation pipelines treat images holistically, disregarding the semantic relevance of parts of an image-e.g. a subject vs. a background-which can lead to the learning of spurious correlations. Our work addresses this problem by investigating a class of simple, yet highly effective "background augmentations", which encourage models to focus on semantically-relevant content by discouraging them from focusing on image backgrounds. Background augmentations lead to substantial improvements (+1-2% on ImageNet-1k) in performance across a spectrum of state-of-the art self-supervised methods (MoCov2, BYOL, SwAV) on a variety of tasks, allowing us to reach within 0.3% of supervised performance. We also demonstrate that background augmentations improve robustness to a number of out of distribution settings, including natural adversarial examples, the backgrounds challenge, adversarial attacks, and ReaL ImageNet.
Are all negatives created equal in contrastive instance discrimination?
Oct 25, 2020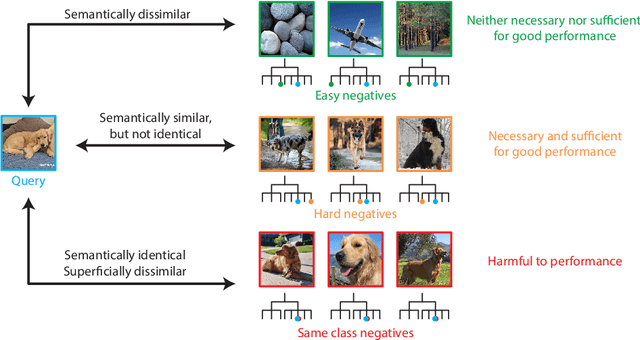
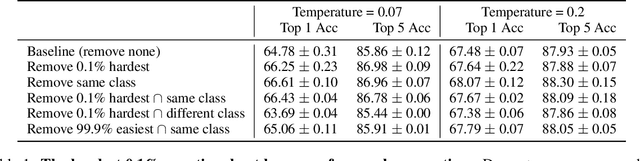
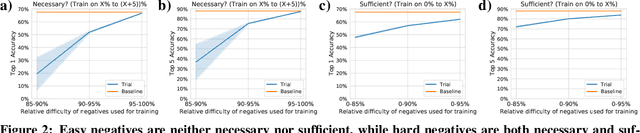
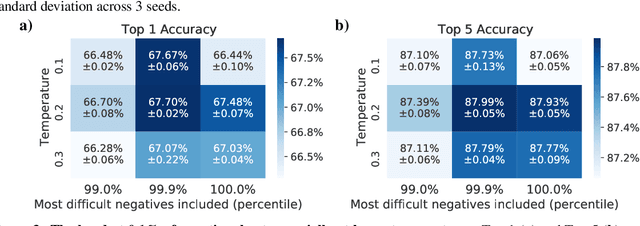
Self-supervised learning has recently begun to rival supervised learning on computer vision tasks. Many of the recent approaches have been based on contrastive instance discrimination (CID), in which the network is trained to recognize two augmented versions of the same instance (a query and positive) while discriminating against a pool of other instances (negatives). The learned representation is then used on downstream tasks such as image classification. Using methodology from MoCo v2 (Chen et al., 2020), we divided negatives by their difficulty for a given query and studied which difficulty ranges were most important for learning useful representations. We found a minority of negatives -- the hardest 5% -- were both necessary and sufficient for the downstream task to reach nearly full accuracy. Conversely, the easiest 95% of negatives were unnecessary and insufficient. Moreover, the very hardest 0.1% of negatives were unnecessary and sometimes detrimental. Finally, we studied the properties of negatives that affect their hardness, and found that hard negatives were more semantically similar to the query, and that some negatives were more consistently easy or hard than we would expect by chance. Together, our results indicate that negatives vary in importance and that CID may benefit from more intelligent negative treatment.
Learning Optimal Representations with the Decodable Information Bottleneck
Sep 27, 2020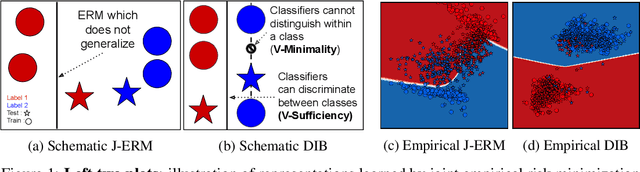
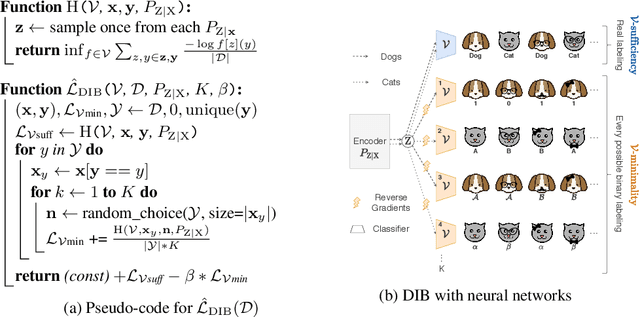

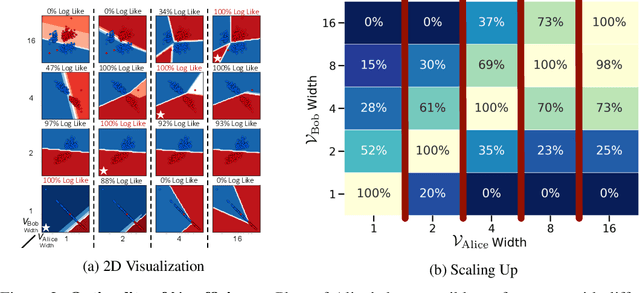
We address the question of characterizing and finding optimal representations for supervised learning. Traditionally, this question has been tackled using the Information Bottleneck, which compresses the inputs while retaining information about the targets, in a decoder-agnostic fashion. In machine learning, however, our goal is not compression but rather generalization, which is intimately linked to the predictive family or decoder of interest (e.g. linear classifier). We propose the Decodable Information Bottleneck (DIB) that considers information retention and compression from the perspective of the desired predictive family. As a result, DIB gives rise to representations that are optimal in terms of expected test performance and can be estimated with guarantees. Empirically, we show that the framework can be used to enforce a small generalization gap on downstream classifiers and to predict the generalization ability of neural networks.
Theory of gating in recurrent neural networks
Aug 29, 2020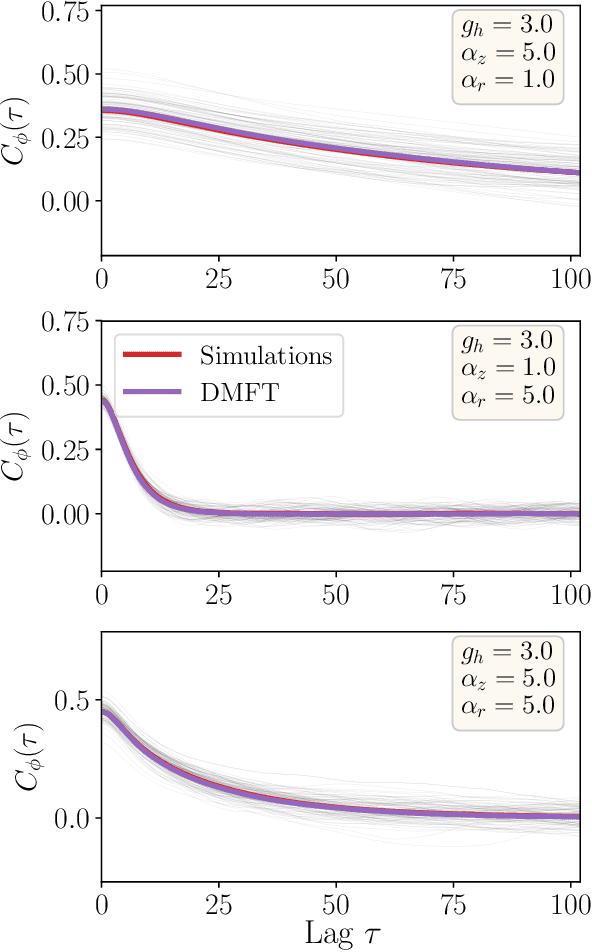


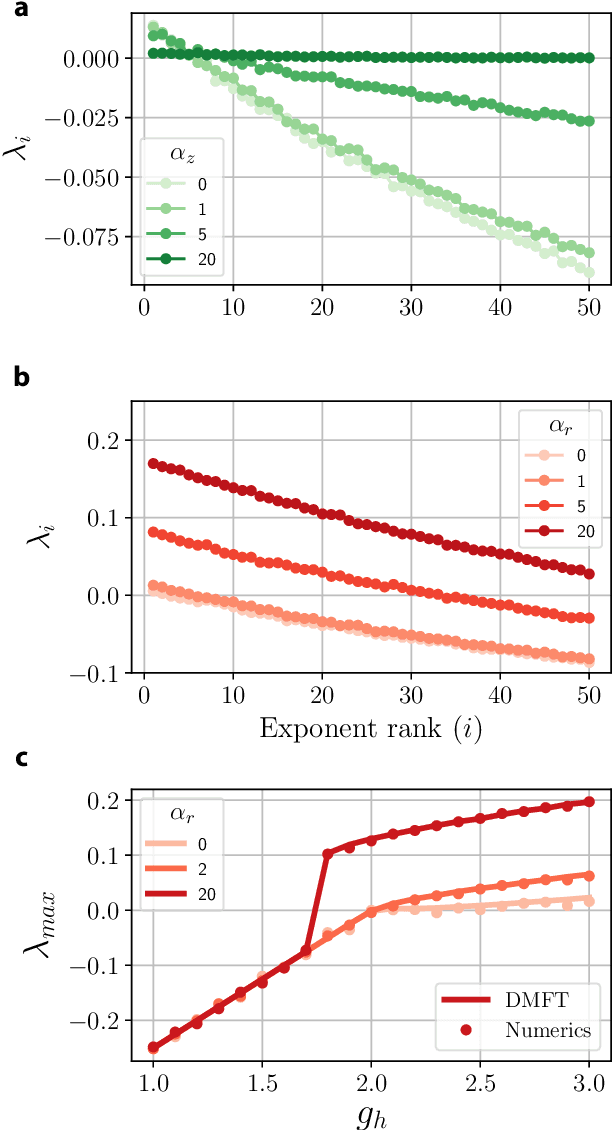
RNNs are popular dynamical models, used for processing sequential data. Prior theoretical work in understanding the properties of RNNs has focused on models with additive interactions, where the input to a unit is a weighted sum of the output of the remaining units in network. However, there is ample evidence that neurons can have gating - i.e. multiplicative - interactions. Such gating interactions have significant effects on the collective dynamics of the network. Furthermore, the best performing RNNs in machine learning have gating interactions. Thus, gating interactions are beneficial for information processing and learning tasks. We develop a dynamical mean-field theory (DMFT) of gating to understand the dynamical regimes produced by gating. Our gated RNN reduces to the classical RNNs in certain limits and is closely related to popular gated models in machine learning. We use random matrix theory (RMT) to analytically characterize the spectrum of the Jacobian and show how gating produces slow modes and marginal stability. Thus, gating is a potential mechanism to implement computations involving line attractor dynamics. The long-time behavior of the gated network is studied using its Lyapunov spectrum, and the DMFT is used to provide an analytical prediction for the maximum Lyapunov exponent. We also show that gating gives rise to a novel, discontinuous transition to chaos, where the proliferation of critical points is decoupled with the appearance of chaotic dynamics; the nature of this chaotic state is characterized in detail. Using the DMFT and RMT, we produce phase diagrams for gated RNN. Finally, we address the gradients by leveraging the adjoint sensitivity framework to develop a DMFT for the gradients. The theory developed here sheds light on the rich dynamical behaviour produced by gating interactions and has implications for architectural choices and learning dynamics.