 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Relational Bottleneck as an Inductive Bias for Efficient Abstraction
Sep 12, 2023

A central challenge for cognitive science is to explain how abstract concepts are acquired from limited experience. This effort has often been framed in terms of a dichotomy between empiricist and nativist approaches, most recently embodied by debates concerning deep neural networks and symbolic cognitive models. Here, we highlight a recently emerging line of work that suggests a novel reconciliation of these approaches, by exploiting an inductive bias that we term the relational bottleneck. We review a family of models that employ this approach to induce abstractions in a data-efficient manner, emphasizing their potential as candidate models for the acquisition of abstract concepts in the human mind and brain.
Trainability, Expressivity and Interpretability in Gated Neural ODEs
Jul 12, 2023


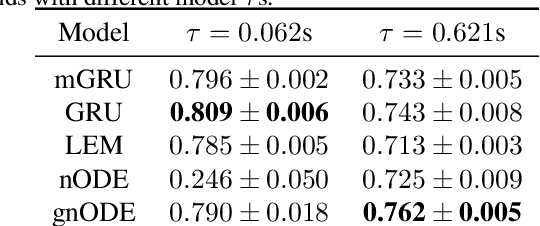
Understanding how the dynamics in biological and artificial neural networks implement the computations required for a task is a salient open question in machine learning and neuroscience. In particular, computations requiring complex memory storage and retrieval pose a significant challenge for these networks to implement or learn. Recently, a family of models described by neural ordinary differential equations (nODEs) has emerged as powerful dynamical neural network models capable of capturing complex dynamics. Here, we extend nODEs by endowing them with adaptive timescales using gating interactions. We refer to these as gated neural ODEs (gnODEs). Using a task that requires memory of continuous quantities, we demonstrate the inductive bias of the gnODEs to learn (approximate) continuous attractors. We further show how reduced-dimensional gnODEs retain their modeling power while greatly improving interpretability, even allowing explicit visualization of the structure of learned attractors. We introduce a novel measure of expressivity which probes the capacity of a neural network to generate complex trajectories. Using this measure, we explore how the phase-space dimension of the nODEs and the complexity of the function modeling the flow field contribute to expressivity. We see that a more complex function for modeling the flow field allows a lower-dimensional nODE to capture a given target dynamics. Finally, we demonstrate the benefit of gating in nODEs on several real-world tasks.
Theory of gating in recurrent neural networks
Aug 29, 2020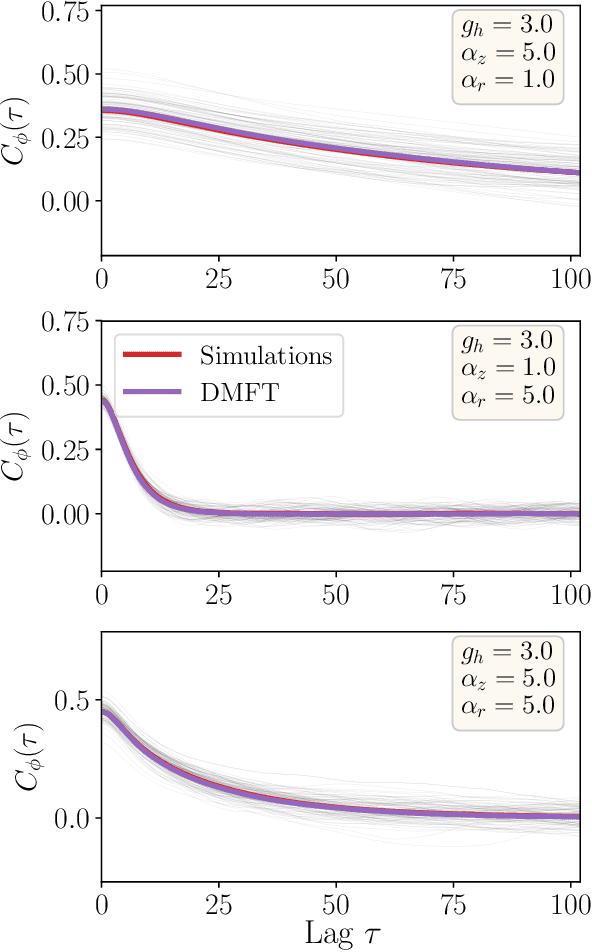


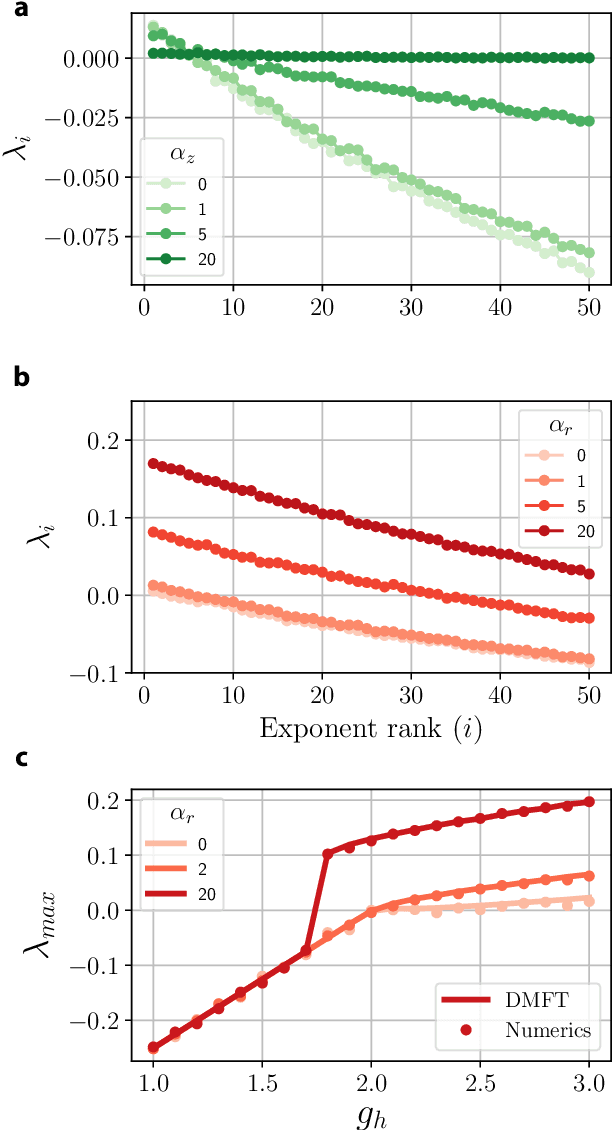
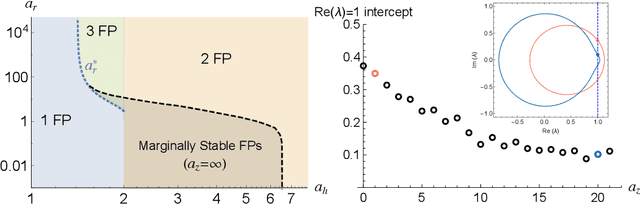
RNNs are popular dynamical models, used for processing sequential data. Prior theoretical work in understanding the properties of RNNs has focused on models with additive interactions, where the input to a unit is a weighted sum of the output of the remaining units in network. However, there is ample evidence that neurons can have gating - i.e. multiplicative - interactions. Such gating interactions have significant effects on the collective dynamics of the network. Furthermore, the best performing RNNs in machine learning have gating interactions. Thus, gating interactions are beneficial for information processing and learning tasks. We develop a dynamical mean-field theory (DMFT) of gating to understand the dynamical regimes produced by gating. Our gated RNN reduces to the classical RNNs in certain limits and is closely related to popular gated models in machine learning. We use random matrix theory (RMT) to analytically characterize the spectrum of the Jacobian and show how gating produces slow modes and marginal stability. Thus, gating is a potential mechanism to implement computations involving line attractor dynamics. The long-time behavior of the gated network is studied using its Lyapunov spectrum, and the DMFT is used to provide an analytical prediction for the maximum Lyapunov exponent. We also show that gating gives rise to a novel, discontinuous transition to chaos, where the proliferation of critical points is decoupled with the appearance of chaotic dynamics; the nature of this chaotic state is characterized in detail. Using the DMFT and RMT, we produce phase diagrams for gated RNN. Finally, we address the gradients by leveraging the adjoint sensitivity framework to develop a DMFT for the gradients. The theory developed here sheds light on the rich dynamical behaviour produced by gating interactions and has implications for architectural choices and learning dynamics.
Gating creates slow modes and controls phase-space complexity in GRUs and LSTMs
Jan 31, 2020
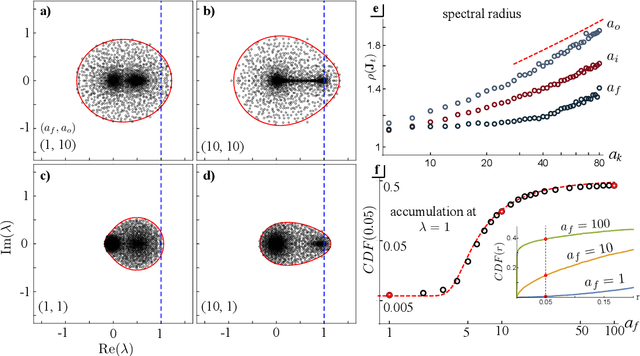

Recurrent neural networks (RNNs) are powerful dynamical models for data with complex temporal structure. However, training RNNs has traditionally proved challenging due to exploding or vanishing of gradients. RNN models such as LSTMs and GRUs (and their variants) significantly mitigate the issues associated with training RNNs by introducing various types of {\it gating} units into the architecture. While these gates empirically improve performance, how the addition of gates influences the dynamics and trainability of GRUs and LSTMs is not well understood. Here, we take the perspective of studying randomly-initialized LSTMs and GRUs as dynamical systems, and ask how the salient dynamical properties are shaped by the gates. We leverage tools from random matrix theory and mean-field theory to study the state-to-state Jacobians of GRUs and LSTMs. We show that the update gate in the GRU and the forget gate in the LSTM can lead to an accumulation of slow modes in the dynamics. Moreover, the GRU update gate can poise the system at a marginally stable point. The reset gate in the GRU and the output and input gates in the LSTM control the spectral radius of the Jacobian, and the GRU reset gate also modulates the complexity of the landscape of fixed-points. Furthermore, for the GRU we obtain a phase diagram describing the statistical properties of fixed-points. Finally, we provide some preliminary comparison of training performance to the various dynamical regimes, which will be investigated elsewhere. The techniques introduced here can be generalized to other RNN architectures to elucidate how various architectural choices influence the dynamics and potentially discover novel architectures.