 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinding Visual Features Point by Point
May 25, 2026Despite success on standard benchmarks, vision language models display persistent failures on tasks involving processing of multi-object scenes, including many tasks that are relatively easy for humans. Recent work has found that these failures may stem from a basic inability to accurately bind object features in-context, a challenge that is referred to as the "binding problem" in cognitive science and neuroscience. The human visual system is thought to solve this binding problem via serial processing, attending to individual objects one at a time so as to avoid interference from other objects. Recent work has proposed "pointing" -- the use of explicit spatial coordinates to refer to objects -- as an analogous solution for vision language models, and found that it improves performance on challenging multi-object tasks. However, it is unclear $\textit{why}$ (i.e., on a mechanistic or representational level) this approach improves performance, and how directly this relates to serial processing in human vision. Here, we investigate this question. We find that learning to point-via-text induces an internal visual search routine, and we characterize the mechanisms that support this procedure. We also find that pointing behavior can be generalized to new tasks via fine-tuning, and that doing so eliminates binding errors and enables compositional generalization. These results provide a proof-of-principle that serial processing can solve the binding problem for vision language models just as it does for biological vision.
Learning is Forgetting: LLM Training As Lossy Compression
Apr 08, 2026Despite the increasing prevalence of large language models (LLMs), we still have a limited understanding of how their representational spaces are structured. This limits our ability to interpret how and what they learn or relate them to learning in humans. We argue LLMs are best seen as an instance of lossy compression, where over training they learn by retaining only information in their training data relevant to their objective(s). We show pre-training results in models that are optimally compressed for next-sequence prediction, approaching the Information Bottleneck bound on compression. Across an array of open weights models, each compresses differently, likely due to differences in the data and training recipes used. However even across different families of LLMs the optimality of a model's compression, and the information present in it, can predict downstream performance on across a wide array of benchmarks, letting us directly link representational structure to actionable insights about model performance. In the general case the work presented here offers a unified Information-Theoretic framing for how these models learn that is deployable at scale.
The Geometry of Representational Failures in Vision Language Models
Feb 02, 2026Vision-Language Models (VLMs) exhibit puzzling failures in multi-object visual tasks, such as hallucinating non-existent elements or failing to identify the most similar objects among distractions. While these errors mirror human cognitive constraints, such as the "Binding Problem", the internal mechanisms driving them in artificial systems remain poorly understood. Here, we propose a mechanistic insight by analyzing the representational geometry of open-weight VLMs (Qwen, InternVL, Gemma), comparing methodologies to distill "concept vectors" - latent directions encoding visual concepts. We validate our concept vectors via steering interventions that reliably manipulate model behavior in both simplified and naturalistic vision tasks (e.g., forcing the model to perceive a red flower as blue). We observe that the geometric overlap between these vectors strongly correlates with specific error patterns, offering a grounded quantitative framework to understand how internal representations shape model behavior and drive visual failures.
Thematic Working Group 5 -- Artificial Intelligence (AI) literacy for teaching and learning: design and implementation
Jan 13, 2026TWG 5 focused on developing and implementing effective strategies for enhancing AI literacy and agency of teachers, equipping them with the knowledge and skills necessary to integrate AI into their teaching practices. Explorations covered curriculum design, professional development programs, practical classroom applications, and policy guidelines aiming to empower educators to confidently utilize AI tools and foster a deeper understanding of AI concepts among students.
AI-enhanced semantic feature norms for 786 concepts
May 15, 2025Semantic feature norms have been foundational in the study of human conceptual knowledge, yet traditional methods face trade-offs between concept/feature coverage and verifiability of quality due to the labor-intensive nature of norming studies. Here, we introduce a novel approach that augments a dataset of human-generated feature norms with responses from large language models (LLMs) while verifying the quality of norms against reliable human judgments. We find that our AI-enhanced feature norm dataset, NOVA: Norms Optimized Via AI, shows much higher feature density and overlap among concepts while outperforming a comparable human-only norm dataset and word-embedding models in predicting people's semantic similarity judgments. Taken together, we demonstrate that human conceptual knowledge is richer than captured in previous norm datasets and show that, with proper validation, LLMs can serve as powerful tools for cognitive science research.
Understanding the Limits of Vision Language Models Through the Lens of the Binding Problem
Oct 31, 2024



Recent work has documented striking heterogeneity in the performance of state-of-the-art vision language models (VLMs), including both multimodal language models and text-to-image models. These models are able to describe and generate a diverse array of complex, naturalistic images, yet they exhibit surprising failures on basic multi-object reasoning tasks -- such as counting, localization, and simple forms of visual analogy -- that humans perform with near perfect accuracy. To better understand this puzzling pattern of successes and failures, we turn to theoretical accounts of the binding problem in cognitive science and neuroscience, a fundamental problem that arises when a shared set of representational resources must be used to represent distinct entities (e.g., to represent multiple objects in an image), necessitating the use of serial processing to avoid interference. We find that many of the puzzling failures of state-of-the-art VLMs can be explained as arising due to the binding problem, and that these failure modes are strikingly similar to the limitations exhibited by rapid, feedforward processing in the human brain.
Slot Abstractors: Toward Scalable Abstract Visual Reasoning
Mar 06, 2024



Abstract visual reasoning is a characteristically human ability, allowing the identification of relational patterns that are abstracted away from object features, and the systematic generalization of those patterns to unseen problems. Recent work has demonstrated strong systematic generalization in visual reasoning tasks involving multi-object inputs, through the integration of slot-based methods used for extracting object-centric representations coupled with strong inductive biases for relational abstraction. However, this approach was limited to problems containing a single rule, and was not scalable to visual reasoning problems containing a large number of objects. Other recent work proposed Abstractors, an extension of Transformers that incorporates strong relational inductive biases, thereby inheriting the Transformer's scalability and multi-head architecture, but it has yet to be demonstrated how this approach might be applied to multi-object visual inputs. Here we combine the strengths of the above approaches and propose Slot Abstractors, an approach to abstract visual reasoning that can be scaled to problems involving a large number of objects and multiple relations among them. The approach displays state-of-the-art performance across four abstract visual reasoning tasks.
A Relational Inductive Bias for Dimensional Abstraction in Neural Networks
Feb 28, 2024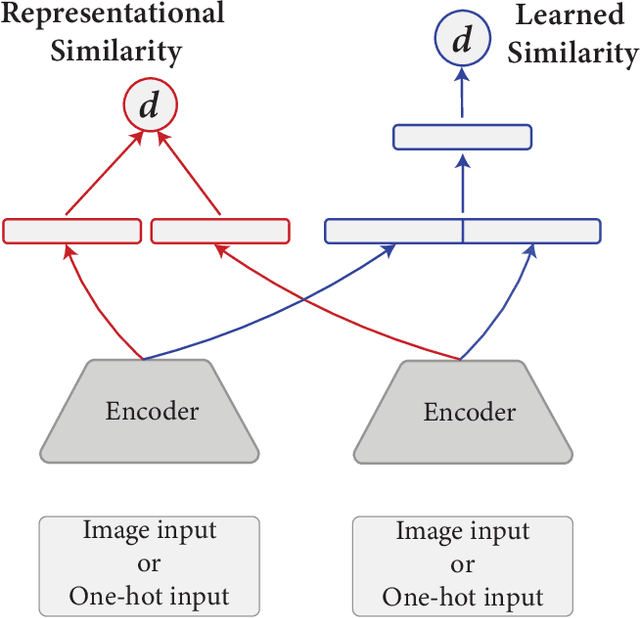
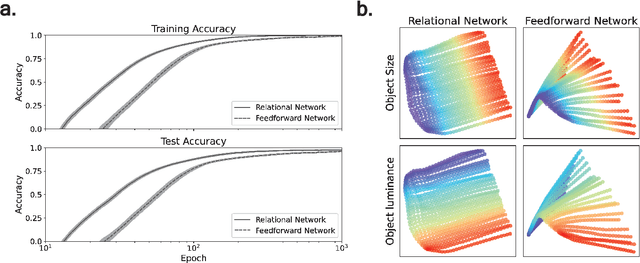
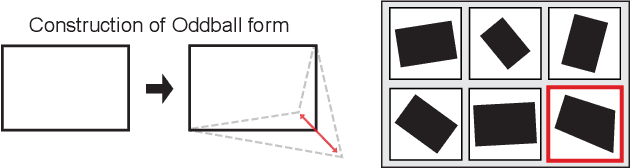
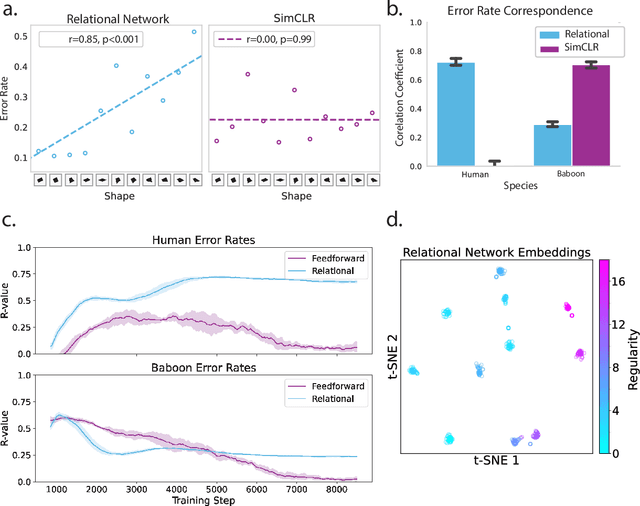
The human cognitive system exhibits remarkable flexibility and generalization capabilities, partly due to its ability to form low-dimensional, compositional representations of the environment. In contrast, standard neural network architectures often struggle with abstract reasoning tasks, overfitting, and requiring extensive data for training. This paper investigates the impact of the relational bottleneck -- a mechanism that focuses processing on relations among inputs -- on the learning of factorized representations conducive to compositional coding and the attendant flexibility of processing. We demonstrate that such a bottleneck not only improves generalization and learning efficiency, but also aligns network performance with human-like behavioral biases. Networks trained with the relational bottleneck developed orthogonal representations of feature dimensions latent in the dataset, reflecting the factorized structure thought to underlie human cognitive flexibility. Moreover, the relational network mimics human biases towards regularity without pre-specified symbolic primitives, suggesting that the bottleneck fosters the emergence of abstract representations that confer flexibility akin to symbols.
Human-Like Geometric Abstraction in Large Pre-trained Neural Networks
Feb 06, 2024


Humans possess a remarkable capacity to recognize and manipulate abstract structure, which is especially apparent in the domain of geometry. Recent research in cognitive science suggests neural networks do not share this capacity, concluding that human geometric abilities come from discrete symbolic structure in human mental representations. However, progress in artificial intelligence (AI) suggests that neural networks begin to demonstrate more human-like reasoning after scaling up standard architectures in both model size and amount of training data. In this study, we revisit empirical results in cognitive science on geometric visual processing and identify three key biases in geometric visual processing: a sensitivity towards complexity, regularity, and the perception of parts and relations. We test tasks from the literature that probe these biases in humans and find that large pre-trained neural network models used in AI demonstrate more human-like abstract geometric processing.
The Relational Bottleneck as an Inductive Bias for Efficient Abstraction
Sep 12, 2023

A central challenge for cognitive science is to explain how abstract concepts are acquired from limited experience. This effort has often been framed in terms of a dichotomy between empiricist and nativist approaches, most recently embodied by debates concerning deep neural networks and symbolic cognitive models. Here, we highlight a recently emerging line of work that suggests a novel reconciliation of these approaches, by exploiting an inductive bias that we term the relational bottleneck. We review a family of models that employ this approach to induce abstractions in a data-efficient manner, emphasizing their potential as candidate models for the acquisition of abstract concepts in the human mind and brain.