 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Yet AlphaFold for the Mind: Evaluating Centaur as a Synthetic Participant
Aug 11, 2025Simulators have revolutionized scientific practice across the natural sciences. By generating data that reliably approximate real-world phenomena, they enable scientists to accelerate hypothesis testing and optimize experimental designs. This is perhaps best illustrated by AlphaFold, a Nobel-prize winning simulator in chemistry that predicts protein structures from amino acid sequences, enabling rapid prototyping of molecular interactions, drug targets, and protein functions. In the behavioral sciences, a reliable participant simulator - a system capable of producing human-like behavior across cognitive tasks - would represent a similarly transformative advance. Recently, Binz et al. introduced Centaur, a large language model (LLM) fine-tuned on human data from 160 experiments, proposing its use not only as a model of cognition but also as a participant simulator for "in silico prototyping of experimental studies", e.g., to advance automated cognitive science. Here, we review the core criteria for a participant simulator and assess how well Centaur meets them. Although Centaur demonstrates strong predictive accuracy, its generative behavior - a critical criterion for a participant simulator - systematically diverges from human data. This suggests that, while Centaur is a significant step toward predicting human behavior, it does not yet meet the standards of a reliable participant simulator or an accurate model of cognition.
Large language models surpass human experts in predicting neuroscience results
Mar 14, 2024Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
GFN-SR: Symbolic Regression with Generative Flow Networks
Dec 01, 2023



Symbolic regression (SR) is an area of interpretable machine learning that aims to identify mathematical expressions, often composed of simple functions, that best fit in a given set of covariates $X$ and response $y$. In recent years, deep symbolic regression (DSR) has emerged as a popular method in the field by leveraging deep reinforcement learning to solve the complicated combinatorial search problem. In this work, we propose an alternative framework (GFN-SR) to approach SR with deep learning. We model the construction of an expression tree as traversing through a directed acyclic graph (DAG) so that GFlowNet can learn a stochastic policy to generate such trees sequentially. Enhanced with an adaptive reward baseline, our method is capable of generating a diverse set of best-fitting expressions. Notably, we observe that GFN-SR outperforms other SR algorithms in noisy data regimes, owing to its ability to learn a distribution of rewards over a space of candidate solutions.
A Quantitative Approach to Predicting Representational Learning and Performance in Neural Networks
Jul 14, 2023



A key property of neural networks (both biological and artificial) is how they learn to represent and manipulate input information in order to solve a task. Different types of representations may be suited to different types of tasks, making identifying and understanding learned representations a critical part of understanding and designing useful networks. In this paper, we introduce a new pseudo-kernel based tool for analyzing and predicting learned representations, based only on the initial conditions of the network and the training curriculum. We validate the method on a simple test case, before demonstrating its use on a question about the effects of representational learning on sequential single versus concurrent multitask performance. We show that our method can be used to predict the effects of the scale of weight initialization and training curriculum on representational learning and downstream concurrent multitasking performance.
A Benchmark for Compositional Visual Reasoning
Jun 11, 2022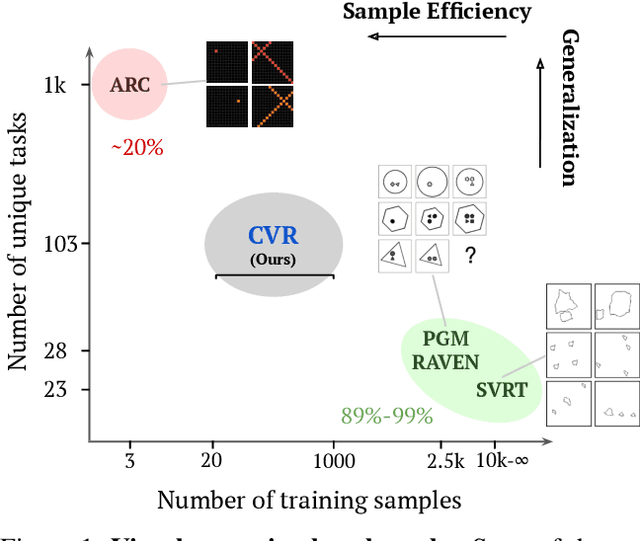
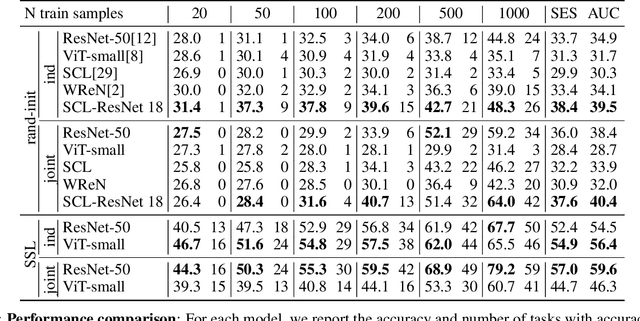
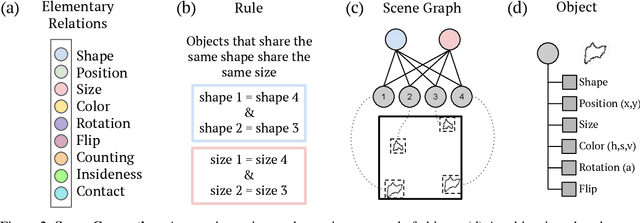
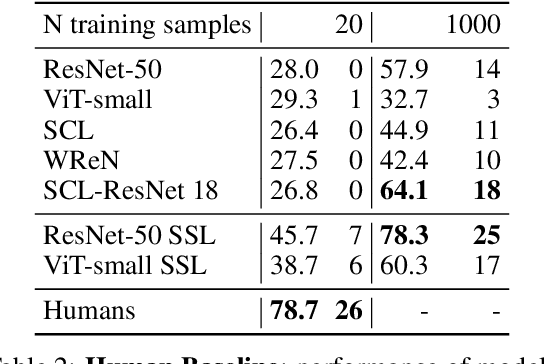
A fundamental component of human vision is our ability to parse complex visual scenes and judge the relations between their constituent objects. AI benchmarks for visual reasoning have driven rapid progress in recent years with state-of-the-art systems now reaching human accuracy on some of these benchmarks. Yet, a major gap remains in terms of the sample efficiency with which humans and AI systems learn new visual reasoning tasks. Humans' remarkable efficiency at learning has been at least partially attributed to their ability to harness compositionality -- such that they can efficiently take advantage of previously gained knowledge when learning new tasks. Here, we introduce a novel visual reasoning benchmark, Compositional Visual Relations (CVR), to drive progress towards the development of more data-efficient learning algorithms. We take inspiration from fluidic intelligence and non-verbal reasoning tests and describe a novel method for creating compositions of abstract rules and associated image datasets at scale. Our proposed benchmark includes measures of sample efficiency, generalization and transfer across task rules, as well as the ability to leverage compositionality. We systematically evaluate modern neural architectures and find that, surprisingly, convolutional architectures surpass transformer-based architectures across all performance measures in most data regimes. However, all computational models are a lot less data efficient compared to humans even after learning informative visual representations using self-supervision. Overall, we hope that our challenge will spur interest in the development of neural architectures that can learn to harness compositionality toward more efficient learning.
Recovering Quantitative Models of Human Information Processing with Differentiable Architecture Search
Mar 25, 2021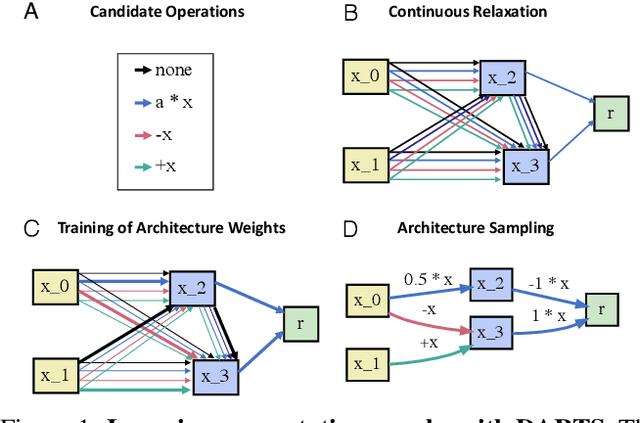


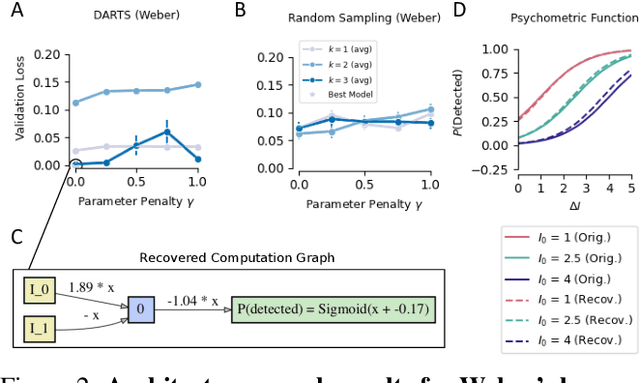
The integration of behavioral phenomena into mechanistic models of cognitive function is a fundamental staple of cognitive science. Yet, researchers are beginning to accumulate increasing amounts of data without having the temporal or monetary resources to integrate these data into scientific theories. We seek to overcome these limitations by incorporating existing machine learning techniques into an open-source pipeline for the automated construction of quantitative models. This pipeline leverages the use of neural architecture search to automate the discovery of interpretable model architectures, and automatic differentiation to automate the fitting of model parameters to data. We evaluate the utility of these methods based on their ability to recover quantitative models of human information processing from synthetic data. We find that these methods are capable of recovering basic quantitative motifs from models of psychophysics, learning and decision making. We also highlight weaknesses of this framework, and discuss future directions for their mitigation.
Navigating the Trade-Off between Multi-Task Learning and Learning to Multitask in Deep Neural Networks
Jul 20, 2020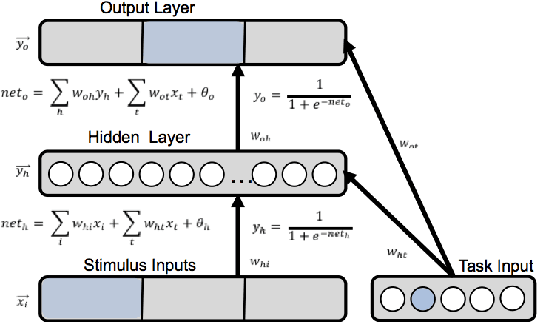
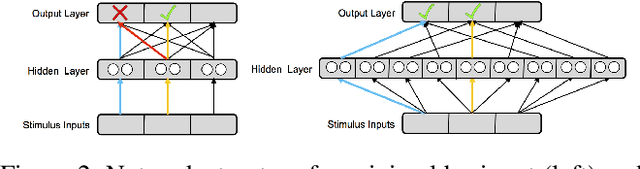
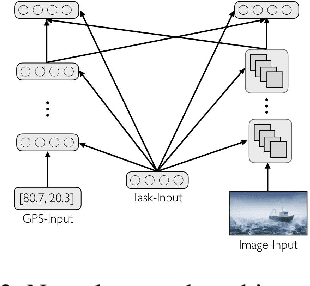
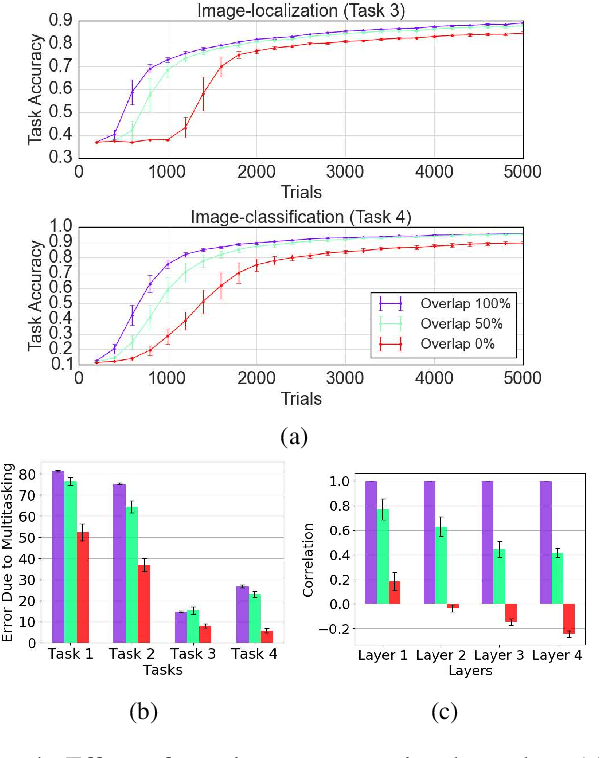
The terms multi-task learning and multitasking are easily confused. Multi-task learning refers to a paradigm in machine learning in which a network is trained on various related tasks to facilitate the acquisition of tasks. In contrast, multitasking is used to indicate, especially in the cognitive science literature, the ability to execute multiple tasks simultaneously. While multi-task learning exploits the discovery of common structure between tasks in the form of shared representations, multitasking is promoted by separating representations between tasks to avoid processing interference. Here, we build on previous work involving shallow networks and simple task settings suggesting that there is a trade-off between multi-task learning and multitasking, mediated by the use of shared versus separated representations. We show that the same tension arises in deep networks and discuss a meta-learning algorithm for an agent to manage this trade-off in an unfamiliar environment. We display through different experiments that the agent is able to successfully optimize its training strategy as a function of the environment.