 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Grouping in Vision-Language Models
Oct 18, 2022
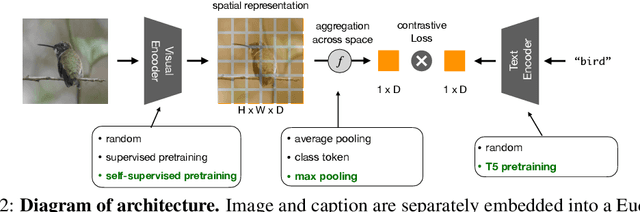
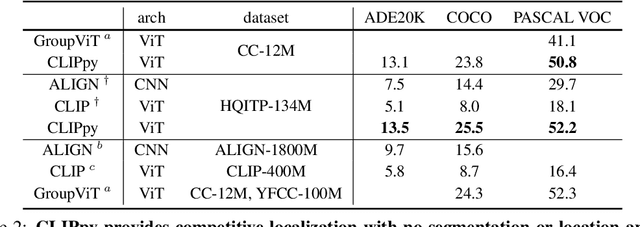
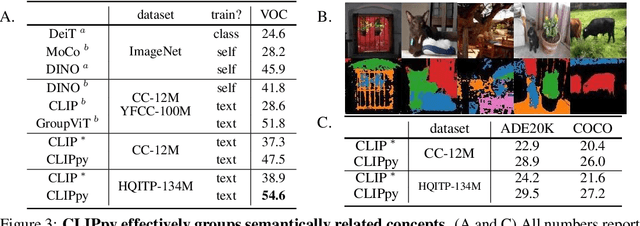
Recent advances in zero-shot image recognition suggest that vision-language models learn generic visual representations with a high degree of semantic information that may be arbitrarily probed with natural language phrases. Understanding an image, however, is not just about understanding what content resides within an image, but importantly, where that content resides. In this work we examine how well vision-language models are able to understand where objects reside within an image and group together visually related parts of the imagery. We demonstrate how contemporary vision and language representation learning models based on contrastive losses and large web-based data capture limited object localization information. We propose a minimal set of modifications that results in models that uniquely learn both semantic and spatial information. We measure this performance in terms of zero-shot image recognition, unsupervised bottom-up and top-down semantic segmentations, as well as robustness analyses. We find that the resulting model achieves state-of-the-art results in terms of unsupervised segmentation, and demonstrate that the learned representations are uniquely robust to spurious correlations in datasets designed to probe the causal behavior of vision models.
Navigating the Trade-Off between Multi-Task Learning and Learning to Multitask in Deep Neural Networks
Jul 20, 2020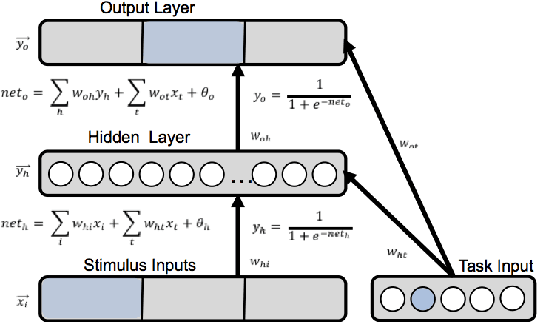
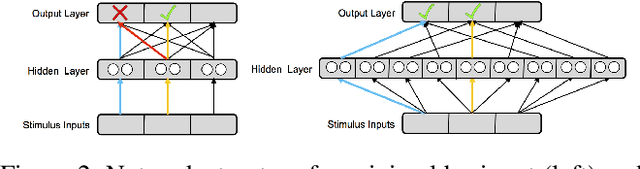
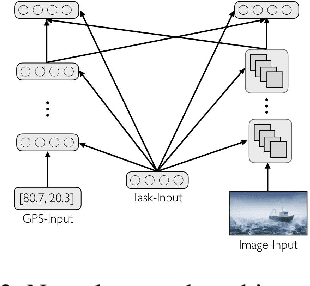
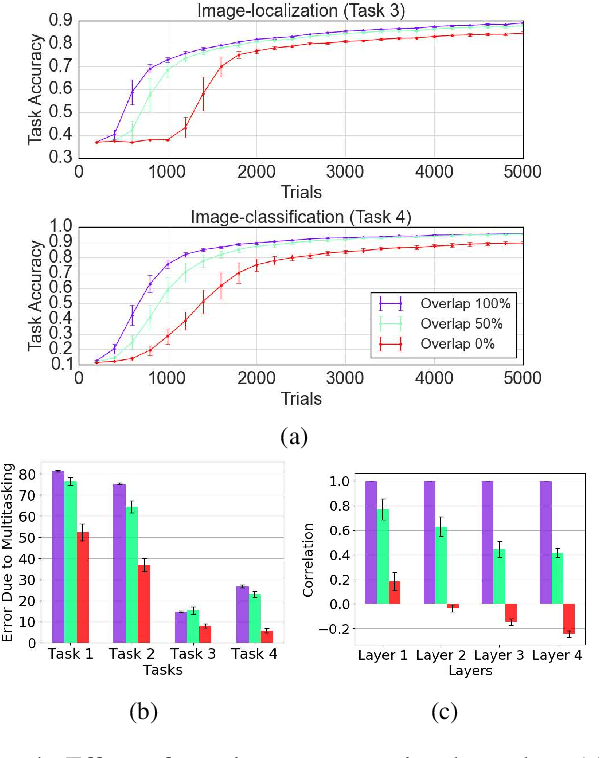
The terms multi-task learning and multitasking are easily confused. Multi-task learning refers to a paradigm in machine learning in which a network is trained on various related tasks to facilitate the acquisition of tasks. In contrast, multitasking is used to indicate, especially in the cognitive science literature, the ability to execute multiple tasks simultaneously. While multi-task learning exploits the discovery of common structure between tasks in the form of shared representations, multitasking is promoted by separating representations between tasks to avoid processing interference. Here, we build on previous work involving shallow networks and simple task settings suggesting that there is a trade-off between multi-task learning and multitasking, mediated by the use of shared versus separated representations. We show that the same tension arises in deep networks and discuss a meta-learning algorithm for an agent to manage this trade-off in an unfamiliar environment. We display through different experiments that the agent is able to successfully optimize its training strategy as a function of the environment.
Privacy-preserving Learning via Deep Net Pruning
Mar 04, 2020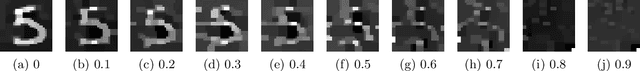



This paper attempts to answer the question whether neural network pruning can be used as a tool to achieve differential privacy without losing much data utility. As a first step towards understanding the relationship between neural network pruning and differential privacy, this paper proves that pruning a given layer of the neural network is equivalent to adding a certain amount of differentially private noise to its hidden-layer activations. The paper also presents experimental results to show the practical implications of the theoretical finding and the key parameter values in a simple practical setting. These results show that neural network pruning can be a more effective alternative to adding differentially private noise for neural networks.
Meta-Learning for Semi-Supervised Few-Shot Classification
Mar 02, 2018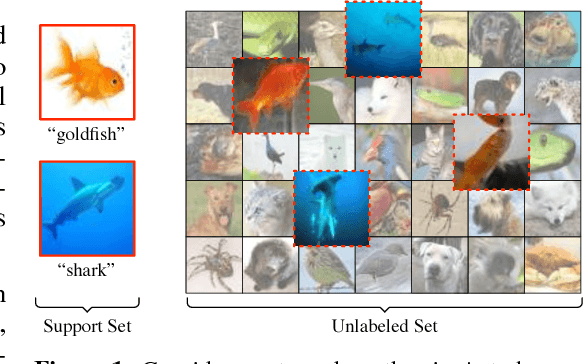

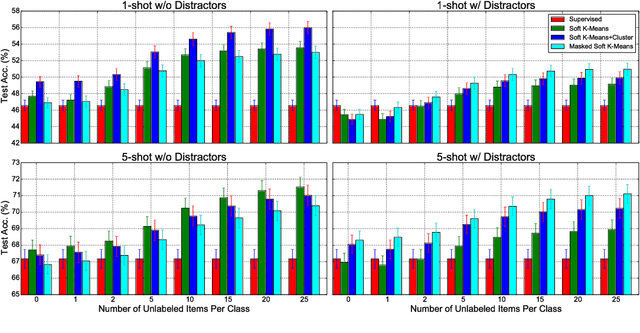
In few-shot classification, we are interested in learning algorithms that train a classifier from only a handful of labeled examples. Recent progress in few-shot classification has featured meta-learning, in which a parameterized model for a learning algorithm is defined and trained on episodes representing different classification problems, each with a small labeled training set and its corresponding test set. In this work, we advance this few-shot classification paradigm towards a scenario where unlabeled examples are also available within each episode. We consider two situations: one where all unlabeled examples are assumed to belong to the same set of classes as the labeled examples of the episode, as well as the more challenging situation where examples from other distractor classes are also provided. To address this paradigm, we propose novel extensions of Prototypical Networks (Snell et al., 2017) that are augmented with the ability to use unlabeled examples when producing prototypes. These models are trained in an end-to-end way on episodes, to learn to leverage the unlabeled examples successfully. We evaluate these methods on versions of the Omniglot and miniImageNet benchmarks, adapted to this new framework augmented with unlabeled examples. We also propose a new split of ImageNet, consisting of a large set of classes, with a hierarchical structure. Our experiments confirm that our Prototypical Networks can learn to improve their predictions due to unlabeled examples, much like a semi-supervised algorithm would.
Learning the Dimensionality of Word Embeddings
Apr 13, 2017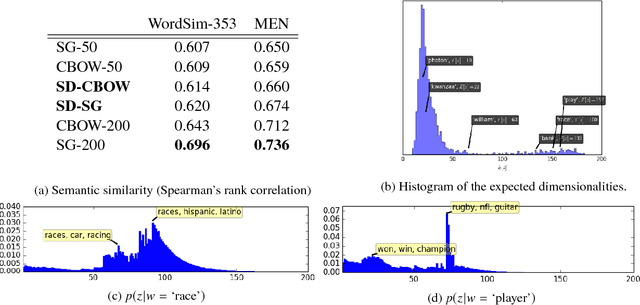
We describe a method for learning word embeddings with data-dependent dimensionality. Our Stochastic Dimensionality Skip-Gram (SD-SG) and Stochastic Dimensionality Continuous Bag-of-Words (SD-CBOW) are nonparametric analogs of Mikolov et al.'s (2013) well-known 'word2vec' models. Vector dimensionality is made dynamic by employing techniques used by Cote & Larochelle (2016) to define an RBM with an infinite number of hidden units. We show qualitatively and quantitatively that SD-SG and SD-CBOW are competitive with their fixed-dimension counterparts while providing a distribution over embedding dimensionalities, which offers a window into how semantics distribute across dimensions.