 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding LLM Agent Boundaries with Strategy-Guided Exploration
Mar 02, 2026Reinforcement learning (RL) has demonstrated notable success in post-training large language models (LLMs) as agents for tasks such as computer use, tool calling, and coding. However, exploration remains a central challenge in RL for LLM agents, especially as they operate in language-action spaces with complex observations and sparse outcome rewards. In this work, we address exploration for LLM agents by leveraging the ability of LLMs to plan and reason in language about the environment to shift exploration from low-level actions to higher-level language strategies. We thus propose Strategy-Guided Exploration (SGE), which first generates a concise natural-language strategy that describes what to do to make progress toward the goal, and then generates environment actions conditioned on that strategy. By exploring in the space of strategies rather than the space of actions, SGE induces structured and diverse exploration that targets different environment outcomes. To increase strategy diversity during RL, SGE introduces mixed-temperature sampling, which explores diverse strategies in parallel, along with a strategy reflection process that grounds strategy generation on the outcomes of previous strategies in the environment. Across UI interaction, tool-calling, coding, and embodied agent environments, SGE consistently outperforms exploration-focused RL baselines, improving both learning efficiency and final performance. We show that SGE enables the agent to learn to solve tasks too difficult for the base model.
GRACE: A Language Model Framework for Explainable Inverse Reinforcement Learning
Oct 02, 2025Inverse Reinforcement Learning aims to recover reward models from expert demonstrations, but traditional methods yield "black-box" models that are difficult to interpret and debug. In this work, we introduce GRACE (Generating Rewards As CodE), a method for using Large Language Models within an evolutionary search to reverse-engineer an interpretable, code-based reward function directly from expert trajectories. The resulting reward function is executable code that can be inspected and verified. We empirically validate GRACE on the BabyAI and AndroidWorld benchmarks, where it efficiently learns highly accurate rewards, even in complex, multi-task settings. Further, we demonstrate that the resulting reward leads to strong policies, compared to both competitive Imitation Learning and online RL approaches with ground-truth rewards. Finally, we show that GRACE is able to build complex reward APIs in multi-task setups.
Ferret-UI Lite: Lessons from Building Small On-Device GUI Agents
Sep 30, 2025
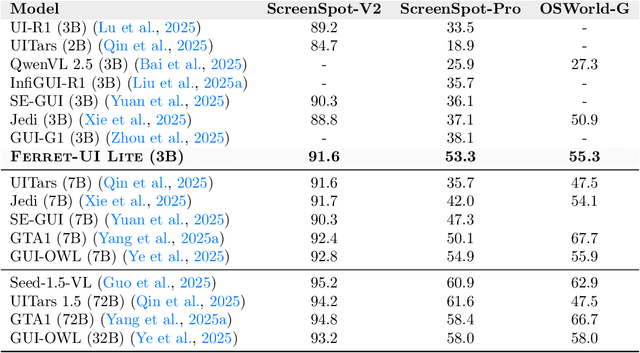
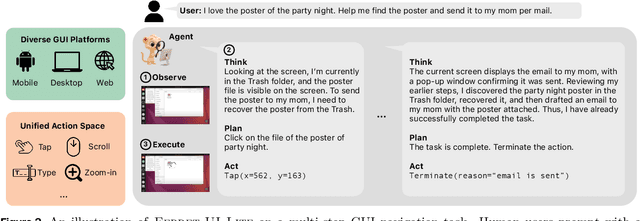
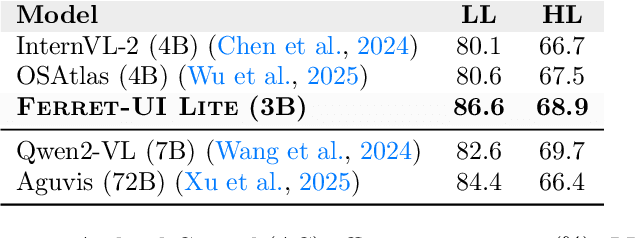
Developing autonomous agents that effectively interact with Graphic User Interfaces (GUIs) remains a challenging open problem, especially for small on-device models. In this paper, we present Ferret-UI Lite, a compact, end-to-end GUI agent that operates across diverse platforms, including mobile, web, and desktop. Utilizing techniques optimized for developing small models, we build our 3B Ferret-UI Lite agent through curating a diverse GUI data mixture from real and synthetic sources, strengthening inference-time performance through chain-of-thought reasoning and visual tool-use, and reinforcement learning with designed rewards. Ferret-UI Lite achieves competitive performance with other small-scale GUI agents. In GUI grounding, Ferret-UI Lite attains scores of $91.6\%$, $53.3\%$, and $61.2\%$ on the ScreenSpot-V2, ScreenSpot-Pro, and OSWorld-G benchmarks, respectively. For GUI navigation, Ferret-UI Lite achieves success rates of $28.0\%$ on AndroidWorld and $19.8\%$ on OSWorld. We share our methods and lessons learned from developing compact, on-device GUI agents.
MobileCLIP2: Improving Multi-Modal Reinforced Training
Aug 28, 2025Foundation image-text models such as CLIP with zero-shot capabilities enable a wide array of applications. MobileCLIP is a recent family of image-text models at 3-15ms latency and 50-150M parameters with state-of-the-art zero-shot accuracy. The main ingredients in MobileCLIP were its low-latency and light architectures and a novel multi-modal reinforced training that made knowledge distillation from multiple caption-generators and CLIP teachers efficient, scalable, and reproducible. In this paper, we improve the multi-modal reinforced training of MobileCLIP through: 1) better CLIP teacher ensembles trained on the DFN dataset, 2) improved captioner teachers trained on the DFN dataset and fine-tuned on a diverse selection of high-quality image-caption datasets. We discover new insights through ablations such as the importance of temperature tuning in contrastive knowledge distillation, the effectiveness of caption-generator fine-tuning for caption diversity, and the additive improvement from combining synthetic captions generated by multiple models. We train a new family of models called MobileCLIP2 and achieve state-of-the-art ImageNet-1k zero-shot accuracies at low latencies. In particular, we observe 2.2% improvement in ImageNet-1k accuracy for MobileCLIP2-B compared with MobileCLIP-B architecture. Notably, MobileCLIP2-S4 matches the zero-shot accuracy of SigLIP-SO400M/14 on ImageNet-1k while being 2$\times$ smaller and improves on DFN ViT-L/14 at 2.5$\times$ lower latency. We release our pretrained models (https://github.com/apple/ml-mobileclip) and the data generation code (https://github.com/apple/ml-mobileclip-dr). The data generation code makes it easy to create new reinforced datasets with arbitrary teachers using distributed scalable processing.
Datasets, Documents, and Repetitions: The Practicalities of Unequal Data Quality
Mar 10, 2025Data filtering has become a powerful tool for improving model performance while reducing computational cost. However, as large language model compute budgets continue to grow, the limited data volume provided by heavily filtered and deduplicated datasets will become a practical constraint. In efforts to better understand how to proceed, we study model performance at various compute budgets and across multiple pre-training datasets created through data filtering and deduplication. We find that, given appropriate modifications to the training recipe, repeating existing aggressively filtered datasets for up to ten epochs can outperform training on the ten times larger superset for a single epoch across multiple compute budget orders of magnitude. While this finding relies on repeating the dataset for many epochs, we also investigate repeats within these datasets at the document level. We find that not all documents within a dataset are equal, and we can create better datasets relative to a token budget by explicitly manipulating the counts of individual documents. We conclude by arguing that even as large language models scale, data filtering remains an important direction of research.
From Multimodal LLMs to Generalist Embodied Agents: Methods and Lessons
Dec 11, 2024We examine the capability of Multimodal Large Language Models (MLLMs) to tackle diverse domains that extend beyond the traditional language and vision tasks these models are typically trained on. Specifically, our focus lies in areas such as Embodied AI, Games, UI Control, and Planning. To this end, we introduce a process of adapting an MLLM to a Generalist Embodied Agent (GEA). GEA is a single unified model capable of grounding itself across these varied domains through a multi-embodiment action tokenizer. GEA is trained with supervised learning on a large dataset of embodied experiences and with online RL in interactive simulators. We explore the data and algorithmic choices necessary to develop such a model. Our findings reveal the importance of training with cross-domain data and online RL for building generalist agents. The final GEA model achieves strong generalization performance to unseen tasks across diverse benchmarks compared to other generalist models and benchmark-specific approaches.
DSplats: 3D Generation by Denoising Splats-Based Multiview Diffusion Models
Dec 11, 2024



Generating high-quality 3D content requires models capable of learning robust distributions of complex scenes and the real-world objects within them. Recent Gaussian-based 3D reconstruction techniques have achieved impressive results in recovering high-fidelity 3D assets from sparse input images by predicting 3D Gaussians in a feed-forward manner. However, these techniques often lack the extensive priors and expressiveness offered by Diffusion Models. On the other hand, 2D Diffusion Models, which have been successfully applied to denoise multiview images, show potential for generating a wide range of photorealistic 3D outputs but still fall short on explicit 3D priors and consistency. In this work, we aim to bridge these two approaches by introducing DSplats, a novel method that directly denoises multiview images using Gaussian Splat-based Reconstructors to produce a diverse array of realistic 3D assets. To harness the extensive priors of 2D Diffusion Models, we incorporate a pretrained Latent Diffusion Model into the reconstructor backbone to predict a set of 3D Gaussians. Additionally, the explicit 3D representation embedded in the denoising network provides a strong inductive bias, ensuring geometrically consistent novel view generation. Our qualitative and quantitative experiments demonstrate that DSplats not only produces high-quality, spatially consistent outputs, but also sets a new standard in single-image to 3D reconstruction. When evaluated on the Google Scanned Objects dataset, DSplats achieves a PSNR of 20.38, an SSIM of 0.842, and an LPIPS of 0.109.
World-consistent Video Diffusion with Explicit 3D Modeling
Dec 02, 2024



Recent advancements in diffusion models have set new benchmarks in image and video generation, enabling realistic visual synthesis across single- and multi-frame contexts. However, these models still struggle with efficiently and explicitly generating 3D-consistent content. To address this, we propose World-consistent Video Diffusion (WVD), a novel framework that incorporates explicit 3D supervision using XYZ images, which encode global 3D coordinates for each image pixel. More specifically, we train a diffusion transformer to learn the joint distribution of RGB and XYZ frames. This approach supports multi-task adaptability via a flexible inpainting strategy. For example, WVD can estimate XYZ frames from ground-truth RGB or generate novel RGB frames using XYZ projections along a specified camera trajectory. In doing so, WVD unifies tasks like single-image-to-3D generation, multi-view stereo, and camera-controlled video generation. Our approach demonstrates competitive performance across multiple benchmarks, providing a scalable solution for 3D-consistent video and image generation with a single pretrained model.
On the Modeling Capabilities of Large Language Models for Sequential Decision Making
Oct 08, 2024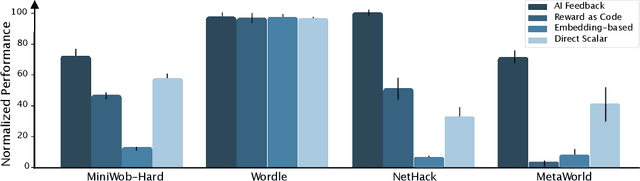
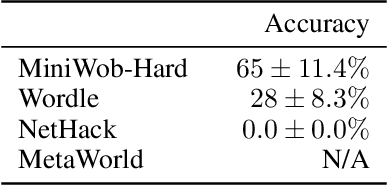
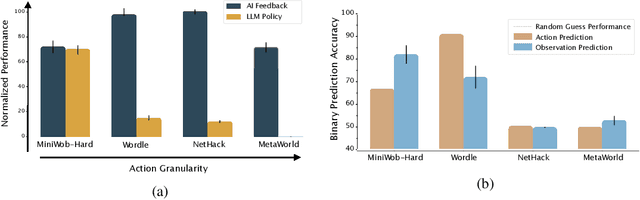
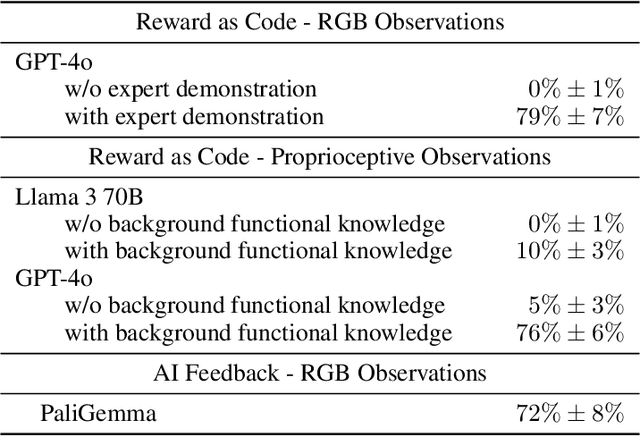
Large pretrained models are showing increasingly better performance in reasoning and planning tasks across different modalities, opening the possibility to leverage them for complex sequential decision making problems. In this paper, we investigate the capabilities of Large Language Models (LLMs) for reinforcement learning (RL) across a diversity of interactive domains. We evaluate their ability to produce decision-making policies, either directly, by generating actions, or indirectly, by first generating reward models to train an agent with RL. Our results show that, even without task-specific fine-tuning, LLMs excel at reward modeling. In particular, crafting rewards through artificial intelligence (AI) feedback yields the most generally applicable approach and can enhance performance by improving credit assignment and exploration. Finally, in environments with unfamiliar dynamics, we explore how fine-tuning LLMs with synthetic data can significantly improve their reward modeling capabilities while mitigating catastrophic forgetting, further broadening their utility in sequential decision-making tasks.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.