 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT5Gemma 2: Seeing, Reading, and Understanding Longer
Dec 23, 2025We introduce T5Gemma 2, the next generation of the T5Gemma family of lightweight open encoder-decoder models, featuring strong multilingual, multimodal and long-context capabilities. T5Gemma 2 follows the adaptation recipe (via UL2) in T5Gemma -- adapting a pretrained decoder-only model into an encoder-decoder model, and extends it from text-only regime to multimodal based on the Gemma 3 models. We further propose two methods to improve the efficiency: tied word embedding that shares all embeddings across encoder and decoder, and merged attention that unifies decoder self- and cross-attention into a single joint module. Experiments demonstrate the generality of the adaptation strategy over architectures and modalities as well as the unique strength of the encoder-decoder architecture on long context modeling. Similar to T5Gemma, T5Gemma 2 yields comparable or better pretraining performance and significantly improved post-training performance than its Gemma 3 counterpart. We release the pretrained models (270M-270M, 1B-1B and 4B-4B) to the community for future research.
Encoder-Decoder Gemma: Improving the Quality-Efficiency Trade-Off via Adaptation
Apr 08, 2025While decoder-only large language models (LLMs) have shown impressive results, encoder-decoder models are still widely adopted in real-world applications for their inference efficiency and richer encoder representation. In this paper, we study a novel problem: adapting pretrained decoder-only LLMs to encoder-decoder, with the goal of leveraging the strengths of both approaches to achieve a more favorable quality-efficiency trade-off. We argue that adaptation not only enables inheriting the capability of decoder-only LLMs but also reduces the demand for computation compared to pretraining from scratch. We rigorously explore different pretraining objectives and parameter initialization/optimization techniques. Through extensive experiments based on Gemma 2 (2B and 9B) and a suite of newly pretrained mT5-sized models (up to 1.6B), we demonstrate the effectiveness of adaptation and the advantage of encoder-decoder LLMs. Under similar inference budget, encoder-decoder LLMs achieve comparable (often better) pretraining performance but substantially better finetuning performance than their decoder-only counterpart. For example, Gemma 2B-2B outperforms Gemma 2B by $\sim$7\% after instruction tuning. Encoder-decoder adaptation also allows for flexible combination of different-sized models, where Gemma 9B-2B significantly surpasses Gemma 2B-2B by $>$3\%. The adapted encoder representation also yields better results on SuperGLUE. We will release our checkpoints to facilitate future research.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Time Sensitive Knowledge Editing through Efficient Finetuning
Jun 06, 2024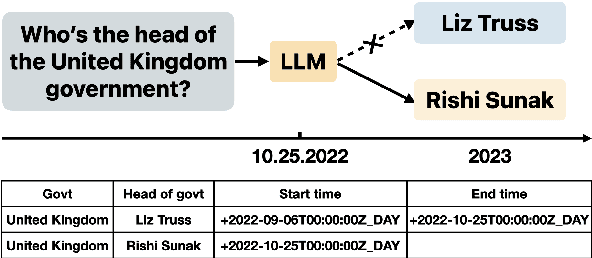

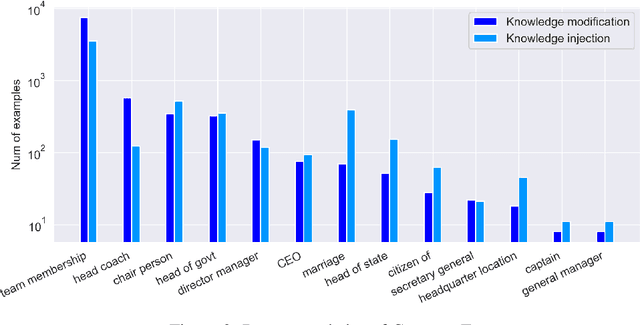
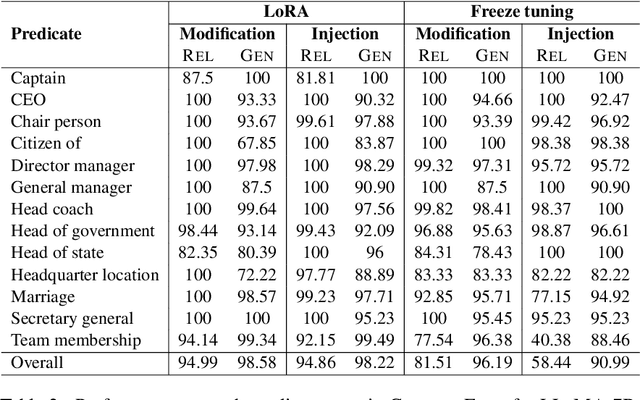
Large Language Models (LLMs) have demonstrated impressive capability in different tasks and are bringing transformative changes to many domains. However, keeping the knowledge in LLMs up-to-date remains a challenge once pretraining is complete. It is thus essential to design effective methods to both update obsolete knowledge and induce new knowledge into LLMs. Existing locate-and-edit knowledge editing (KE) method suffers from two limitations. First, the post-edit LLMs by such methods generally have poor capability in answering complex queries that require multi-hop reasoning. Second, the long run-time of such locate-and-edit methods to perform knowledge edits make it infeasible for large scale KE in practice. In this paper, we explore Parameter-Efficient Fine-Tuning (PEFT) techniques as an alternative for KE. We curate a more comprehensive temporal KE dataset with both knowledge update and knowledge injection examples for KE performance benchmarking. We further probe the effect of fine-tuning on a range of layers in an LLM for the multi-hop QA task. We find that PEFT performs better than locate-and-edit techniques for time-sensitive knowledge edits.
Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach
May 24, 2024Self-supervised features are the cornerstone of modern machine learning systems. They are typically pre-trained on data collections whose construction and curation typically require extensive human effort. This manual process has some limitations similar to those encountered in supervised learning, e.g., the crowd-sourced selection of data is costly and time-consuming, preventing scaling the dataset size. In this work, we consider the problem of automatic curation of high-quality datasets for self-supervised pre-training. We posit that such datasets should be large, diverse and balanced, and propose a clustering-based approach for building ones satisfying all these criteria. Our method involves successive and hierarchical applications of $k$-means on a large and diverse data repository to obtain clusters that distribute uniformly among data concepts, followed by a hierarchical, balanced sampling step from these clusters. Extensive experiments on three different data domains including web-based images, satellite images and text show that features trained on our automatically curated datasets outperform those trained on uncurated data while being on par or better than ones trained on manually curated data.
Advancing human-centric AI for robust X-ray analysis through holistic self-supervised learning
May 02, 2024



AI Foundation models are gaining traction in various applications, including medical fields like radiology. However, medical foundation models are often tested on limited tasks, leaving their generalisability and biases unexplored. We present RayDINO, a large visual encoder trained by self-supervision on 873k chest X-rays. We compare RayDINO to previous state-of-the-art models across nine radiology tasks, from classification and dense segmentation to text generation, and provide an in depth analysis of population, age and sex biases of our model. Our findings suggest that self-supervision allows patient-centric AI proving useful in clinical workflows and interpreting X-rays holistically. With RayDINO and small task-specific adapters, we reach state-of-the-art results and improve generalization to unseen populations while mitigating bias, illustrating the true promise of foundation models: versatility and robustness.
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Apr 11, 2024



We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Scalable Pre-training of Large Autoregressive Image Models
Jan 16, 2024



This paper introduces AIM, a collection of vision models pre-trained with an autoregressive objective. These models are inspired by their textual counterparts, i.e., Large Language Models (LLMs), and exhibit similar scaling properties. Specifically, we highlight two key findings: (1) the performance of the visual features scale with both the model capacity and the quantity of data, (2) the value of the objective function correlates with the performance of the model on downstream tasks. We illustrate the practical implication of these findings by pre-training a 7 billion parameter AIM on 2 billion images, that achieves 84.0% on ImageNet-1k with a frozen trunk. Interestingly, even at this scale, we observe no sign of saturation in performance, suggesting that AIM potentially represents a new frontier for training large-scale vision models. The pre-training of AIM is similar to the pre-training of LLMs, and does not require any image-specific strategy to stabilize the training at scale.