 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoder-Decoder or Decoder-Only? Revisiting Encoder-Decoder Large Language Model
Oct 30, 2025Recent large language model (LLM) research has undergone an architectural shift from encoder-decoder modeling to nowadays the dominant decoder-only modeling. This rapid transition, however, comes without a rigorous comparative analysis especially \textit{from the scaling perspective}, raising concerns that the potential of encoder-decoder models may have been overlooked. To fill this gap, we revisit encoder-decoder LLM (RedLLM), enhancing it with recent recipes from decoder-only LLM (DecLLM). We conduct a comprehensive comparison between RedLLM, pretrained with prefix language modeling (LM), and DecLLM, pretrained with causal LM, at different model scales, ranging from $\sim$150M to $\sim$8B. Using RedPajama V1 (1.6T tokens) for pretraining and FLAN for instruction tuning, our experiments show that RedLLM produces compelling scaling properties and surprisingly strong performance. While DecLLM is overall more compute-optimal during pretraining, RedLLM demonstrates comparable scaling and context length extrapolation capabilities. After instruction tuning, RedLLM achieves comparable and even better results on various downstream tasks while enjoying substantially better inference efficiency. We hope our findings could inspire more efforts on re-examining RedLLM, unlocking its potential for developing powerful and efficient LLMs.
mSTEB: Massively Multilingual Evaluation of LLMs on Speech and Text Tasks
Jun 10, 2025Large Language models (LLMs) have demonstrated impressive performance on a wide range of tasks, including in multimodal settings such as speech. However, their evaluation is often limited to English and a few high-resource languages. For low-resource languages, there is no standardized evaluation benchmark. In this paper, we address this gap by introducing mSTEB, a new benchmark to evaluate the performance of LLMs on a wide range of tasks covering language identification, text classification, question answering, and translation tasks on both speech and text modalities. We evaluated the performance of leading LLMs such as Gemini 2.0 Flash and GPT-4o (Audio) and state-of-the-art open models such as Qwen 2 Audio and Gemma 3 27B. Our evaluation shows a wide gap in performance between high-resource and low-resource languages, especially for languages spoken in Africa and Americas/Oceania. Our findings show that more investment is needed to address their under-representation in LLMs coverage.
Encoder-Decoder Gemma: Improving the Quality-Efficiency Trade-Off via Adaptation
Apr 08, 2025While decoder-only large language models (LLMs) have shown impressive results, encoder-decoder models are still widely adopted in real-world applications for their inference efficiency and richer encoder representation. In this paper, we study a novel problem: adapting pretrained decoder-only LLMs to encoder-decoder, with the goal of leveraging the strengths of both approaches to achieve a more favorable quality-efficiency trade-off. We argue that adaptation not only enables inheriting the capability of decoder-only LLMs but also reduces the demand for computation compared to pretraining from scratch. We rigorously explore different pretraining objectives and parameter initialization/optimization techniques. Through extensive experiments based on Gemma 2 (2B and 9B) and a suite of newly pretrained mT5-sized models (up to 1.6B), we demonstrate the effectiveness of adaptation and the advantage of encoder-decoder LLMs. Under similar inference budget, encoder-decoder LLMs achieve comparable (often better) pretraining performance but substantially better finetuning performance than their decoder-only counterpart. For example, Gemma 2B-2B outperforms Gemma 2B by $\sim$7\% after instruction tuning. Encoder-decoder adaptation also allows for flexible combination of different-sized models, where Gemma 9B-2B significantly surpasses Gemma 2B-2B by $>$3\%. The adapted encoder representation also yields better results on SuperGLUE. We will release our checkpoints to facilitate future research.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
FLEURS-R: A Restored Multilingual Speech Corpus for Generation Tasks
Aug 12, 2024
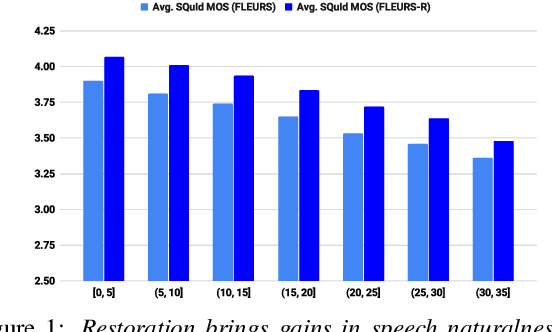
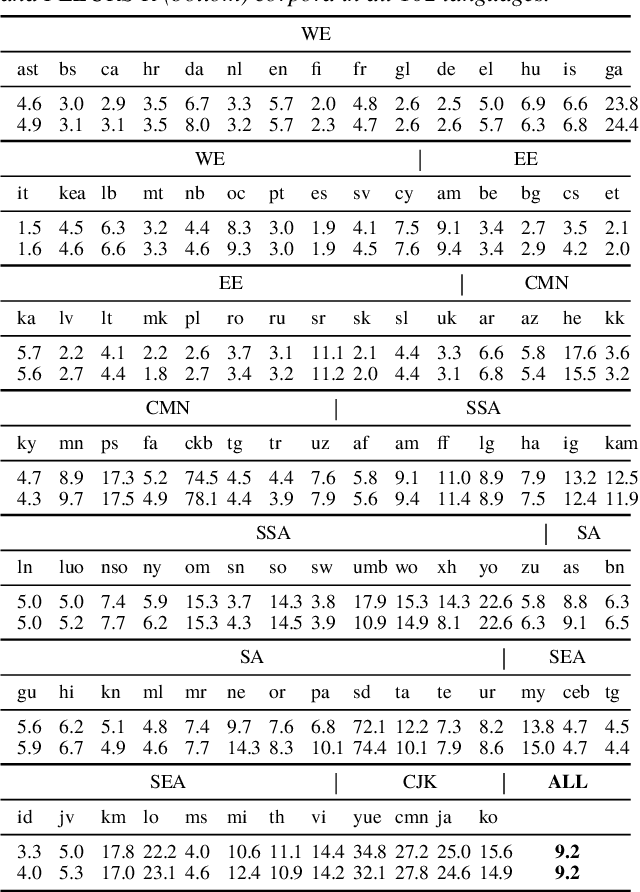
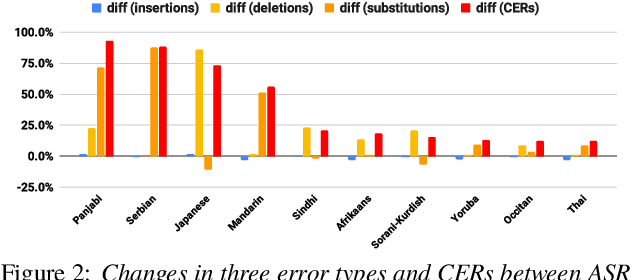
This paper introduces FLEURS-R, a speech restoration applied version of the Few-shot Learning Evaluation of Universal Representations of Speech (FLEURS) corpus. FLEURS-R maintains an N-way parallel speech corpus in 102 languages as FLEURS, with improved audio quality and fidelity by applying the speech restoration model Miipher. The aim of FLEURS-R is to advance speech technology in more languages and catalyze research including text-to-speech (TTS) and other speech generation tasks in low-resource languages. Comprehensive evaluations with the restored speech and TTS baseline models trained from the new corpus show that the new corpus obtained significantly improved speech quality while maintaining the semantic contents of the speech. The corpus is publicly released via Hugging Face.
Finite-Time Adaptive Fuzzy Tracking Control for Nonlinear State Constrained Pure-Feedback Systems
Oct 23, 2023



This paper investigates the finite-time adaptive fuzzy tracking control problem for a class of pure-feedback system with full-state constraints. With the help of Mean-Value Theorem, the pure-feedback nonlinear system is transformed into strict-feedback case. By employing finite-time-stable like function and state transformation for output tracking error, the output tracking error converges to a predefined set in a fixed finite interval. To tackle the problem of state constraints, integral Barrier Lyapunov functions are utilized to guarantee that the state variables remain within the prescribed constraints with feasibility check. Fuzzy logic systems are utilized to approximate the unknown nonlinear functions. In addition, all the signals in the closed-loop system are guaranteed to be semi-global ultimately uniformly bounded. Finally, two simulation examples are given to show the effectiveness of the proposed control strategy.
Multimodal Modeling For Spoken Language Identification
Sep 19, 2023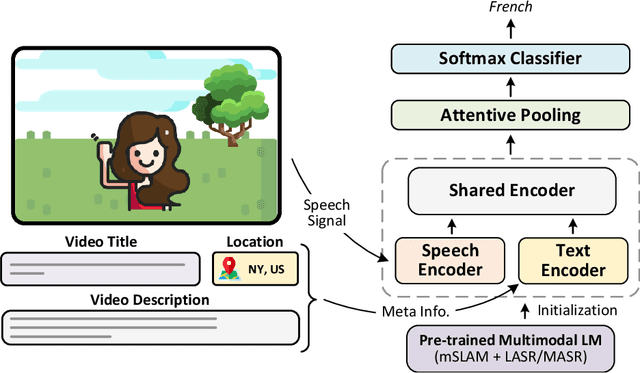
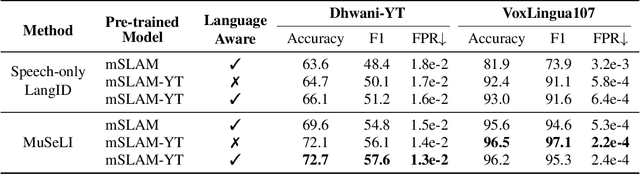
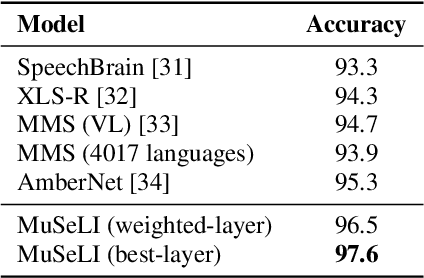
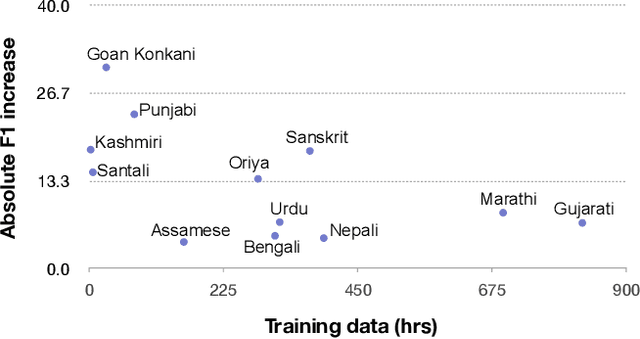
Spoken language identification refers to the task of automatically predicting the spoken language in a given utterance. Conventionally, it is modeled as a speech-based language identification task. Prior techniques have been constrained to a single modality; however in the case of video data there is a wealth of other metadata that may be beneficial for this task. In this work, we propose MuSeLI, a Multimodal Spoken Language Identification method, which delves into the use of various metadata sources to enhance language identification. Our study reveals that metadata such as video title, description and geographic location provide substantial information to identify the spoken language of the multimedia recording. We conduct experiments using two diverse public datasets of YouTube videos, and obtain state-of-the-art results on the language identification task. We additionally conduct an ablation study that describes the distinct contribution of each modality for language recognition.
MASR: Metadata Aware Speech Representation
Jul 20, 2023In the recent years, speech representation learning is constructed primarily as a self-supervised learning (SSL) task, using the raw audio signal alone, while ignoring the side-information that is often available for a given speech recording. In this paper, we propose MASR, a Metadata Aware Speech Representation learning framework, which addresses the aforementioned limitations. MASR enables the inclusion of multiple external knowledge sources to enhance the utilization of meta-data information. The external knowledge sources are incorporated in the form of sample-level pair-wise similarity matrices that are useful in a hard-mining loss. A key advantage of the MASR framework is that it can be combined with any choice of SSL method. Using MASR representations, we perform evaluations on several downstream tasks such as language identification, speech recognition and other non-semantic tasks such as speaker and emotion recognition. In these experiments, we illustrate significant performance improvements for the MASR over other established benchmarks. We perform a detailed analysis on the language identification task to provide insights on how the proposed loss function enables the representations to separate closely related languages.
Label Aware Speech Representation Learning For Language Identification
Jun 07, 2023

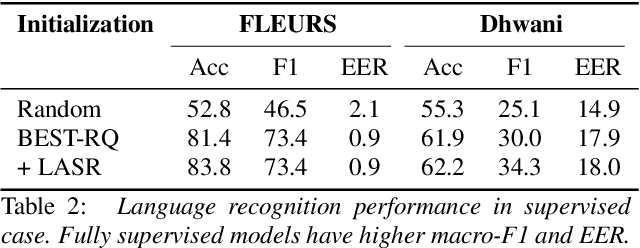

Speech representation learning approaches for non-semantic tasks such as language recognition have either explored supervised embedding extraction methods using a classifier model or self-supervised representation learning approaches using raw data. In this paper, we propose a novel framework of combining self-supervised representation learning with the language label information for the pre-training task. This framework, termed as Label Aware Speech Representation (LASR) learning, uses a triplet based objective function to incorporate language labels along with the self-supervised loss function. The speech representations are further fine-tuned for the downstream task. The language recognition experiments are performed on two public datasets - FLEURS and Dhwani. In these experiments, we illustrate that the proposed LASR framework improves over the state-of-the-art systems on language identification. We also report an analysis of the robustness of LASR approach to noisy/missing labels as well as its application to multi-lingual speech recognition tasks.
XTREME-UP: A User-Centric Scarce-Data Benchmark for Under-Represented Languages
May 24, 2023



Data scarcity is a crucial issue for the development of highly multilingual NLP systems. Yet for many under-represented languages (ULs) -- languages for which NLP re-search is particularly far behind in meeting user needs -- it is feasible to annotate small amounts of data. Motivated by this, we propose XTREME-UP, a benchmark defined by: its focus on the scarce-data scenario rather than zero-shot; its focus on user-centric tasks -- tasks with broad adoption by speakers of high-resource languages; and its focus on under-represented languages where this scarce-data scenario tends to be most realistic. XTREME-UP evaluates the capabilities of language models across 88 under-represented languages over 9 key user-centric technologies including ASR, OCR, MT, and information access tasks that are of general utility. We create new datasets for OCR, autocomplete, semantic parsing, and transliteration, and build on and refine existing datasets for other tasks. XTREME-UP provides methodology for evaluating many modeling scenarios including text-only, multi-modal (vision, audio, and text),supervised parameter tuning, and in-context learning. We evaluate commonly used models on the benchmark. We release all code and scripts to train and evaluate models