 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Apr 11, 2024



We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Brouhaha: multi-task training for voice activity detection, speech-to-noise ratio, and C50 room acoustics estimation
Oct 27, 2022



Most automatic speech processing systems are sensitive to the acoustic environment, with degraded performance when applied to noisy or reverberant speech. But how can one tell whether speech is noisy or reverberant? We propose Brouhaha, a pipeline to simulate audio segments recorded in noisy and reverberant conditions. We then use the simulated audio to jointly train the Brouhaha model for voice activity detection, signal-to-noise ratio estimation, and C50 room acoustics prediction. We show how the predicted SNR and C50 values can be used to investigate and help diagnose errors made by automatic speech processing tools (such as pyannote.audio for speaker diarization or OpenAI's Whisper for automatic speech recognition). Both our pipeline and a pretrained model are open source and shared with the speech community.
Textless Speech Emotion Conversion using Decomposed and Discrete Representations
Nov 14, 2021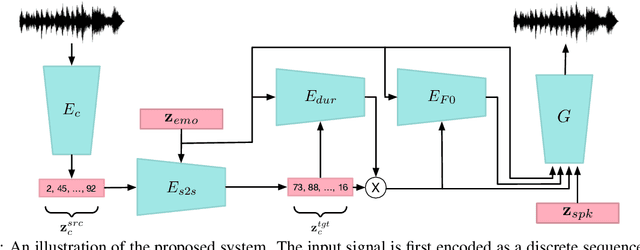
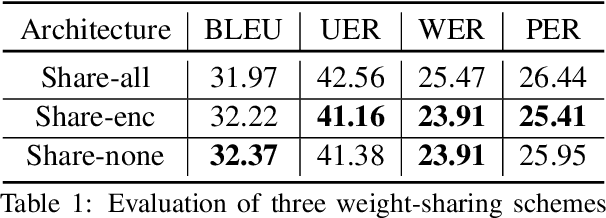
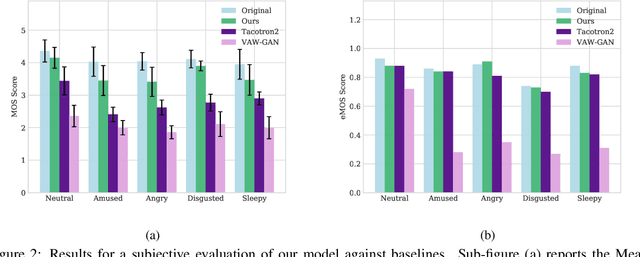
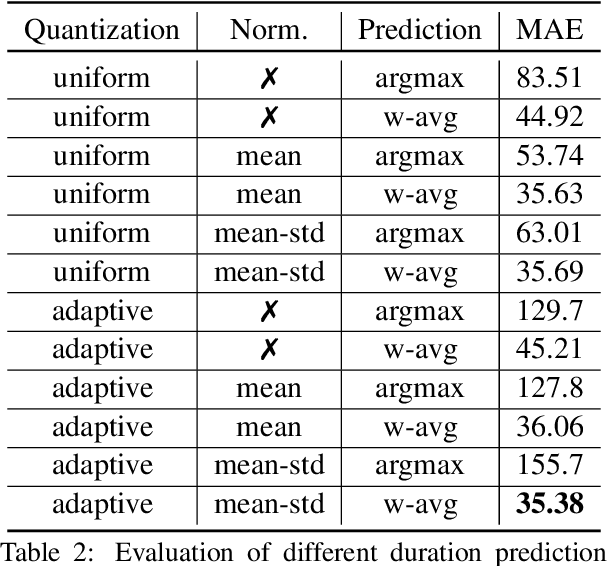
Speech emotion conversion is the task of modifying the perceived emotion of a speech utterance while preserving the lexical content and speaker identity. In this study, we cast the problem of emotion conversion as a spoken language translation task. We decompose speech into discrete and disentangled learned representations, consisting of content units, F0, speaker, and emotion. First, we modify the speech content by translating the content units to a target emotion, and then predict the prosodic features based on these units. Finally, the speech waveform is generated by feeding the predicted representations into a neural vocoder. Such a paradigm allows us to go beyond spectral and parametric changes of the signal, and model non-verbal vocalizations, such as laughter insertion, yawning removal, etc. We demonstrate objectively and subjectively that the proposed method is superior to the baselines in terms of perceived emotion and audio quality. We rigorously evaluate all components of such a complex system and conclude with an extensive model analysis and ablation study to better emphasize the architectural choices, strengths and weaknesses of the proposed method. Samples and code will be publicly available under the following link: https://speechbot.github.io/emotion.
Text-Free Prosody-Aware Generative Spoken Language Modeling
Sep 07, 2021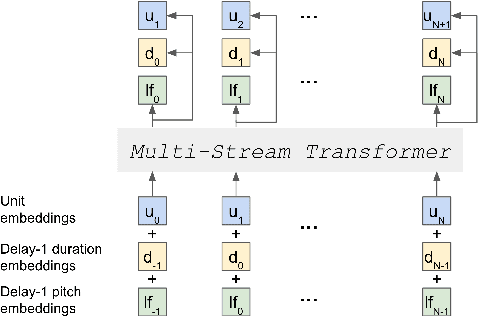
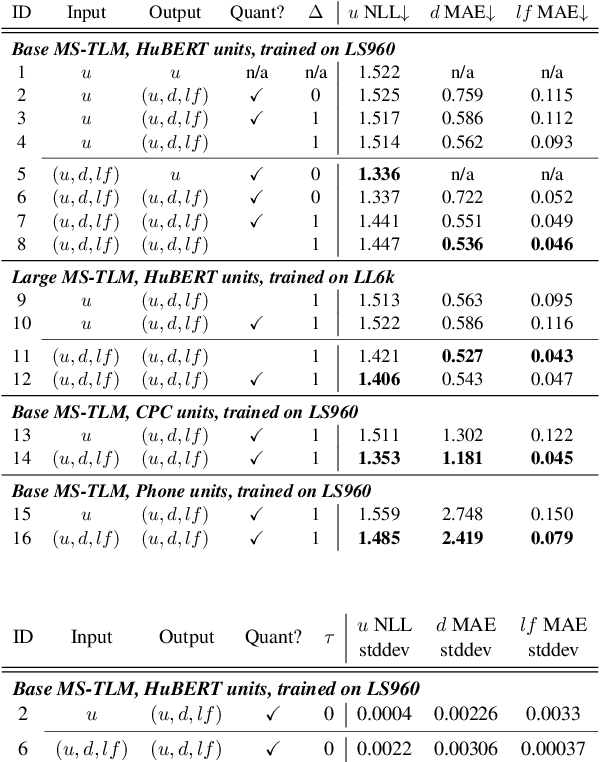
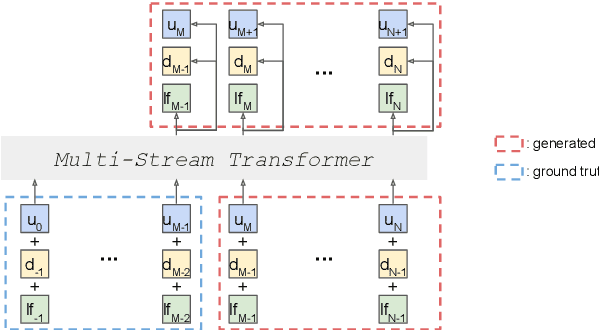
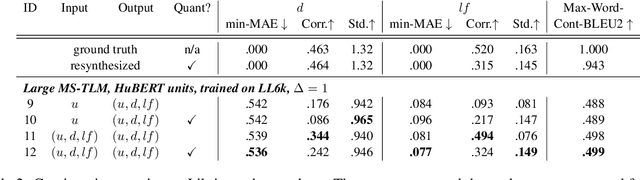
Speech pre-training has primarily demonstrated efficacy on classification tasks, while its capability of generating novel speech, similar to how GPT-2 can generate coherent paragraphs, has barely been explored. Generative Spoken Language Modeling (GSLM) (Lakhotia et al., 2021) is the only prior work addressing the generative aspects of speech pre-training, which replaces text with discovered phone-like units for language modeling and shows the ability to generate meaningful novel sentences. Unfortunately, despite eliminating the need of text, the units used in GSLM discard most of the prosodic information. Hence, GSLM fails to leverage prosody for better comprehension, and does not generate expressive speech. In this work, we present a prosody-aware generative spoken language model (pGSLM). It is composed of a multi-stream transformer language model (MS-TLM) of speech, represented as discovered unit and prosodic feature streams, and an adapted HiFi-GAN model converting MS-TLM outputs to waveforms. We devise a series of metrics for prosody modeling and generation, and re-use metrics from GSLM for content modeling. Experimental results show that the pGSLM can utilize prosody to improve both prosody and content modeling, and also generate natural, meaningful, and coherent speech given a spoken prompt. Audio samples can be found at https://speechbot.github.io/pgslm.
The Interspeech Zero Resource Speech Challenge 2021: Spoken language modelling
Apr 29, 2021
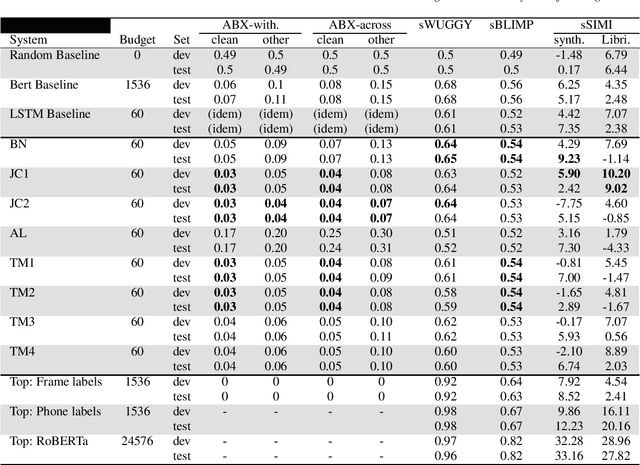
We present the Zero Resource Speech Challenge 2021, which asks participants to learn a language model directly from audio, without any text or labels. The challenge is based on the Libri-light dataset, which provides up to 60k hours of audio from English audio books without any associated text. We provide a pipeline baseline system consisting on an encoder based on contrastive predictive coding (CPC), a quantizer ($k$-means) and a standard language model (BERT or LSTM). The metrics evaluate the learned representations at the acoustic (ABX discrimination), lexical (spot-the-word), syntactic (acceptability judgment) and semantic levels (similarity judgment). We present an overview of the eight submitted systems from four groups and discuss the main results.
VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation
Jan 02, 2021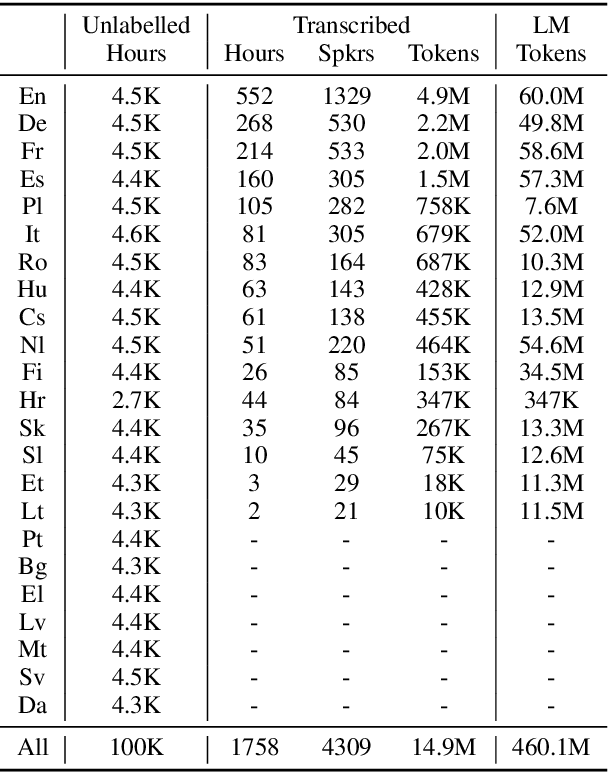
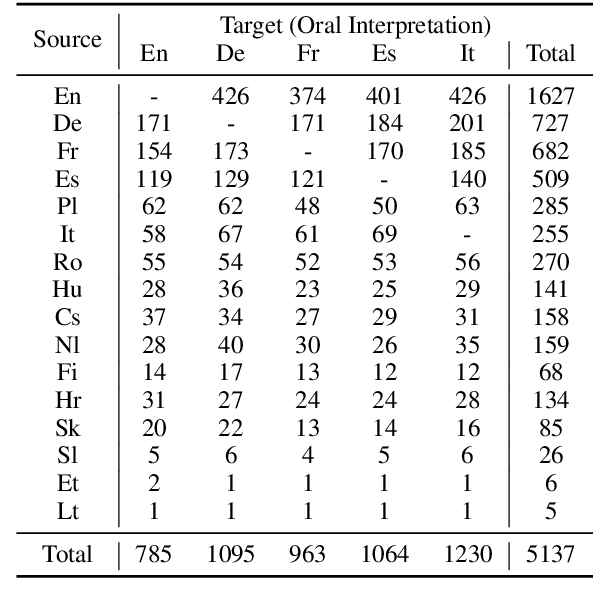

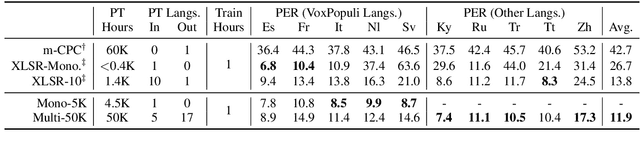
We introduce VoxPopuli, a large-scale multilingual corpus providing 100K hours of unlabelled speech data in 23 languages. It is the largest open data to date for unsupervised representation learning as well as semi-supervised learning. VoxPopuli also contains 1.8K hours of transcribed speeches in 16 languages and their aligned oral interpretations into 5 other languages totaling 5.1K hours. We provide speech recognition baselines and validate the versatility of VoxPopuli unlabelled data in semi-supervised learning under challenging out-of-domain settings. We will release the corpus at https://github.com/facebookresearch/voxpopuli under an open license.