 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShennong: a Python toolbox for audio speech features extraction
Dec 10, 2021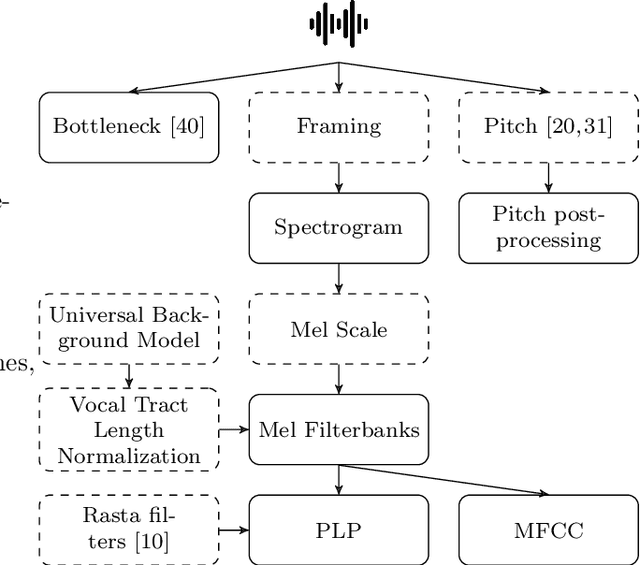
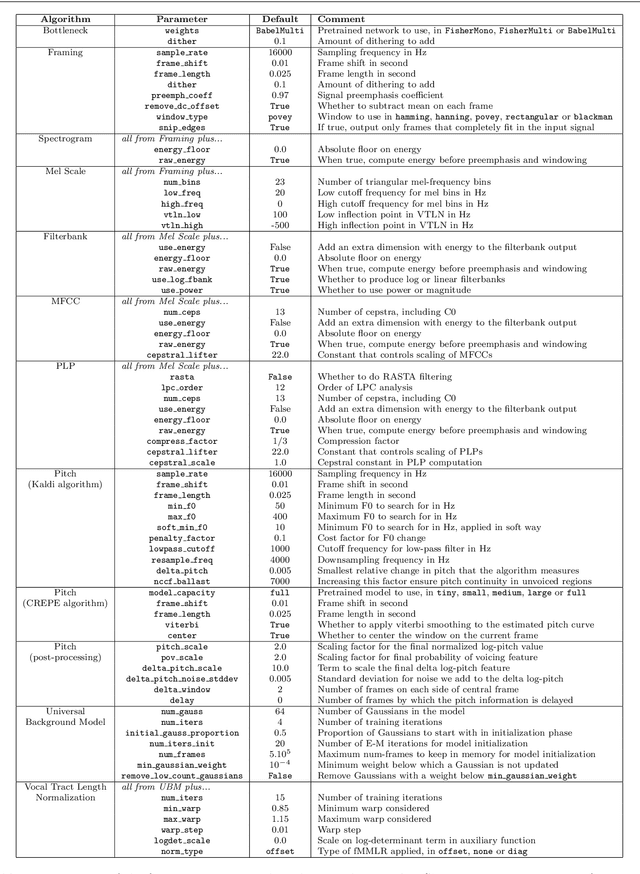
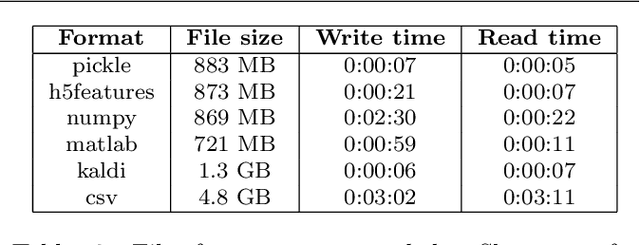
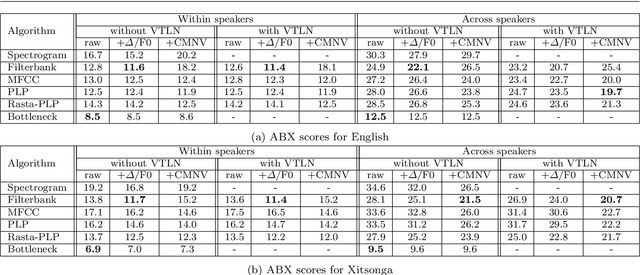
We introduce Shennong, a Python toolbox and command-line utility for speech features extraction. It implements a wide range of well-established state of art algorithms including spectro-temporal filters such as Mel-Frequency Cepstral Filterbanks or Predictive Linear Filters, pre-trained neural networks, pitch estimators as well as speaker normalization methods and post-processing algorithms. Shennong is an open source, easy-to-use, reliable and extensible framework. The use of Python makes the integration to others speech modeling and machine learning tools easy. It aims to replace or complement several heterogeneous software, such as Kaldi or Praat. After describing the Shennong software architecture, its core components and implemented algorithms, this paper illustrates its use on three applications: a comparison of speech features performances on a phones discrimination task, an analysis of a Vocal Tract Length Normalization model as a function of the speech duration used for training and a comparison of pitch estimation algorithms under various noise conditions.
The Interspeech Zero Resource Speech Challenge 2021: Spoken language modelling
Apr 29, 2021
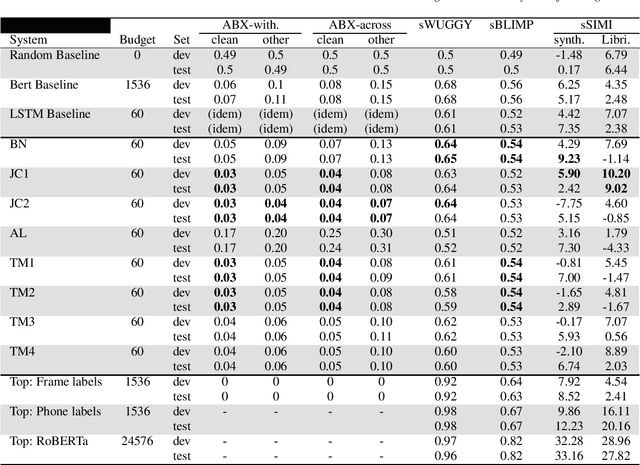
We present the Zero Resource Speech Challenge 2021, which asks participants to learn a language model directly from audio, without any text or labels. The challenge is based on the Libri-light dataset, which provides up to 60k hours of audio from English audio books without any associated text. We provide a pipeline baseline system consisting on an encoder based on contrastive predictive coding (CPC), a quantizer ($k$-means) and a standard language model (BERT or LSTM). The metrics evaluate the learned representations at the acoustic (ABX discrimination), lexical (spot-the-word), syntactic (acceptability judgment) and semantic levels (similarity judgment). We present an overview of the eight submitted systems from four groups and discuss the main results.
The Zero Resource Speech Challenge 2020: Discovering discrete subword and word units
Oct 12, 2020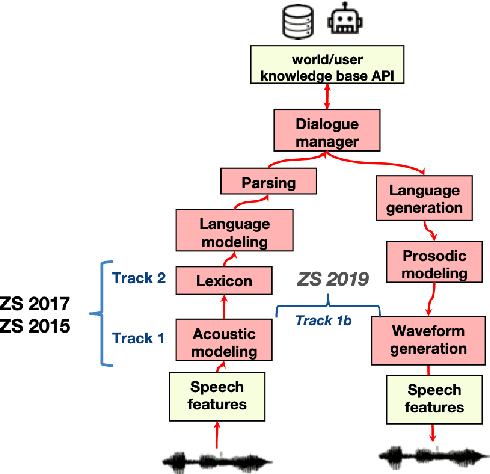

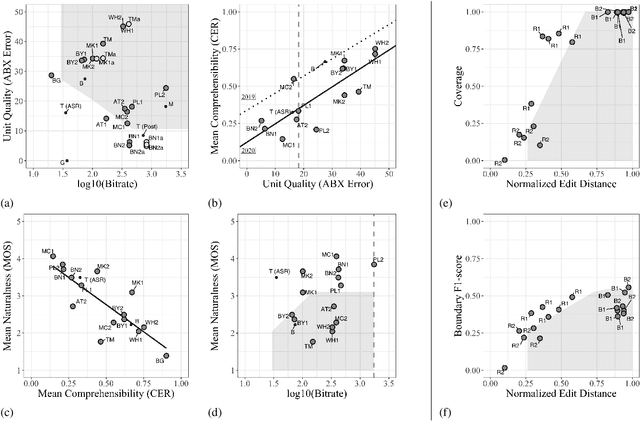
We present the Zero Resource Speech Challenge 2020, which aims at learning speech representations from raw audio signals without any labels. It combines the data sets and metrics from two previous benchmarks (2017 and 2019) and features two tasks which tap into two levels of speech representation. The first task is to discover low bit-rate subword representations that optimize the quality of speech synthesis; the second one is to discover word-like units from unsegmented raw speech. We present the results of the twenty submitted models and discuss the implications of the main findings for unsupervised speech learning.
The Zero Resource Speech Challenge 2019: TTS without T
Apr 25, 2019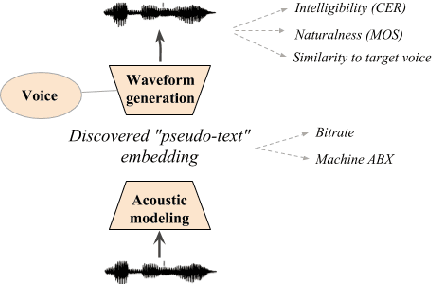
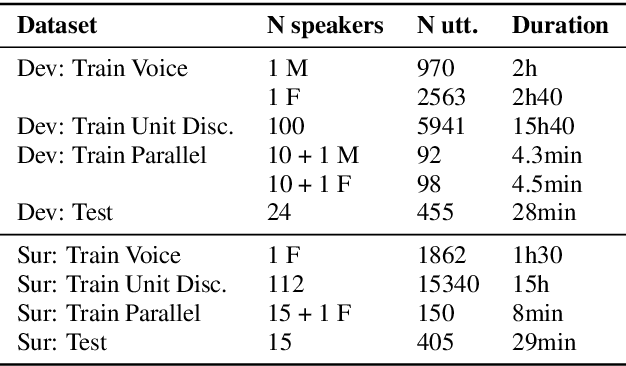
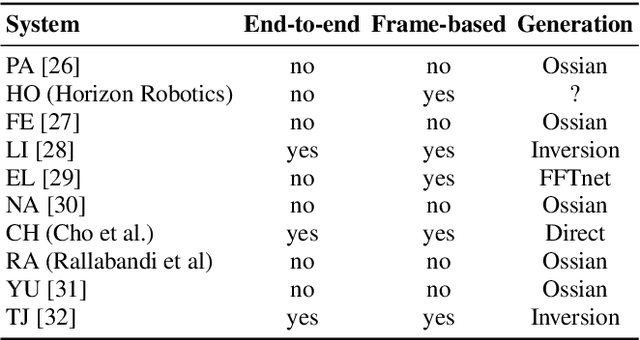
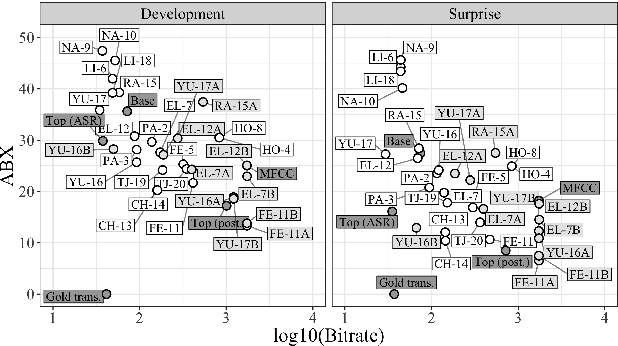
We present the Zero Resource Speech Challenge 2019, which proposes to build a speech synthesizer without any text or phonetic labels: hence, TTS without T (text-to-speech without text). We provide raw audio for a target voice in an unknown language (the Voice dataset), but no alignment, text or labels. Participants must discover subword units in an unsupervised way (using the Unit Discovery dataset) and align them to the voice recordings in a way that works best for the purpose of synthesizing novel utterances from novel speakers, similar to the target speaker's voice. We describe the metrics used for evaluation, a baseline system consisting of unsupervised subword unit discovery plus a standard TTS system, and a topline TTS using gold phoneme transcriptions. We present an overview of the 19 submitted systems from 11 teams and discuss the main results.
IntPhys: A Framework and Benchmark for Visual Intuitive Physics Reasoning
Jun 26, 2018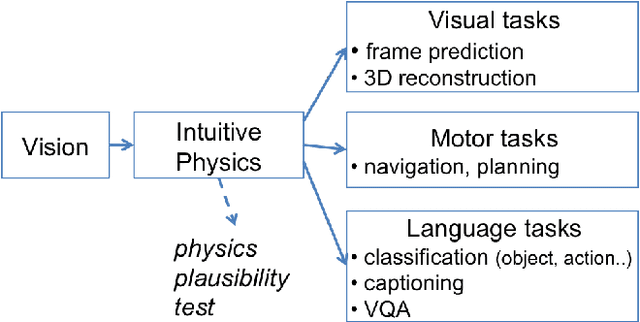

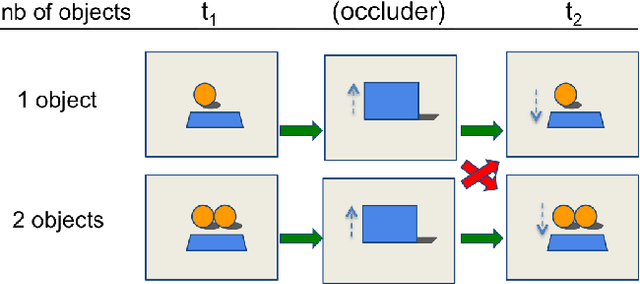
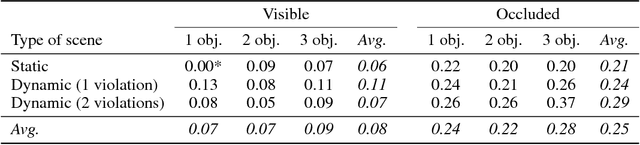
In order to reach human performance on complex visual tasks, artificial systems need to incorporate a significant amount of understanding of the world in terms of macroscopic objects, movements, forces, etc. Inspired by work on intuitive physics in infants, we propose an evaluation framework which diagnoses how much a given system understands about physics by testing whether it can tell apart well matched videos of possible versus impossible events. The test requires systems to compute a physical plausibility score over an entire video. It is free of bias and can test a range of specific physical reasoning skills. We then describe the first release of a benchmark dataset aimed at learning intuitive physics in an unsupervised way, using videos constructed with a game engine. We describe two Deep Neural Network baseline systems trained with a future frame prediction objective and tested on the possible versus impossible discrimination task. The analysis of their results compared to human data gives novel insights in the potentials and limitations of next frame prediction architectures.
The Zero Resource Speech Challenge 2017
Dec 12, 2017
We describe a new challenge aimed at discovering subword and word units from raw speech. This challenge is the followup to the Zero Resource Speech Challenge 2015. It aims at constructing systems that generalize across languages and adapt to new speakers. The design features and evaluation metrics of the challenge are presented and the results of seventeen models are discussed.