 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpidR-Adapt: A Universal Speech Representation Model for Few-Shot Adaptation
Dec 24, 2025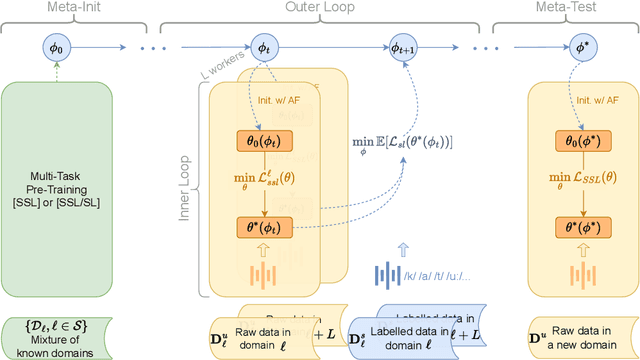

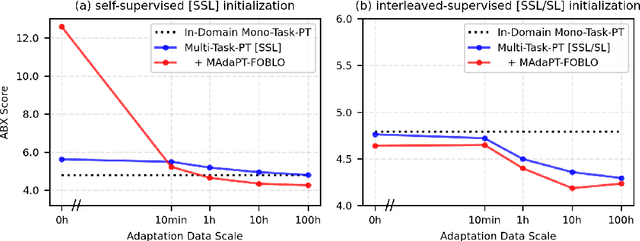
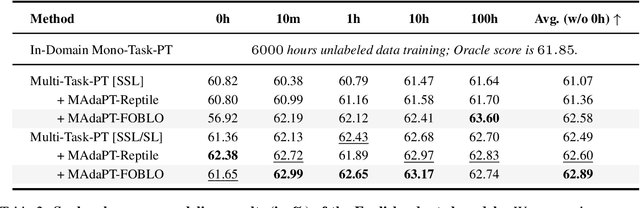
Human infants, with only a few hundred hours of speech exposure, acquire basic units of new languages, highlighting a striking efficiency gap compared to the data-hungry self-supervised speech models. To address this gap, this paper introduces SpidR-Adapt for rapid adaptation to new languages using minimal unlabeled data. We cast such low-resource speech representation learning as a meta-learning problem and construct a multi-task adaptive pre-training (MAdaPT) protocol which formulates the adaptation process as a bi-level optimization framework. To enable scalable meta-training under this framework, we propose a novel heuristic solution, first-order bi-level optimization (FOBLO), avoiding heavy computation costs. Finally, we stabilize meta-training by using a robust initialization through interleaved supervision which alternates self-supervised and supervised objectives. Empirically, SpidR-Adapt achieves rapid gains in phonemic discriminability (ABX) and spoken language modeling (sWUGGY, sBLIMP, tSC), improving over in-domain language models after training on less than 1h of target-language audio, over $100\times$ more data-efficient than standard training. These findings highlight a practical, architecture-agnostic path toward biologically inspired, data-efficient representations. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr-adapt.
SpidR: Learning Fast and Stable Linguistic Units for Spoken Language Models Without Supervision
Dec 23, 2025The parallel advances in language modeling and speech representation learning have raised the prospect of learning language directly from speech without textual intermediates. This requires extracting semantic representations directly from speech. Our contributions are threefold. First, we introduce SpidR, a self-supervised speech representation model that efficiently learns representations with highly accessible phonetic information, which makes it particularly suited for textless spoken language modeling. It is trained on raw waveforms using a masked prediction objective combined with self-distillation and online clustering. The intermediate layers of the student model learn to predict assignments derived from the teacher's intermediate layers. This learning objective stabilizes the online clustering procedure compared to previous approaches, resulting in higher quality codebooks. SpidR outperforms wav2vec 2.0, HuBERT, WavLM, and DinoSR on downstream language modeling benchmarks (sWUGGY, sBLIMP, tSC). Second, we systematically evaluate across models and layers the correlation between speech unit quality (ABX, PNMI) and language modeling performance, validating these metrics as reliable proxies. Finally, SpidR significantly reduces pretraining time compared to HuBERT, requiring only one day of pretraining on 16 GPUs, instead of a week. This speedup is enabled by the pretraining method and an efficient codebase, which allows faster iteration and easier experimentation. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr.
BabyHuBERT: Multilingual Self-Supervised Learning for Segmenting Speakers in Child-Centered Long-Form Recordings
Sep 18, 2025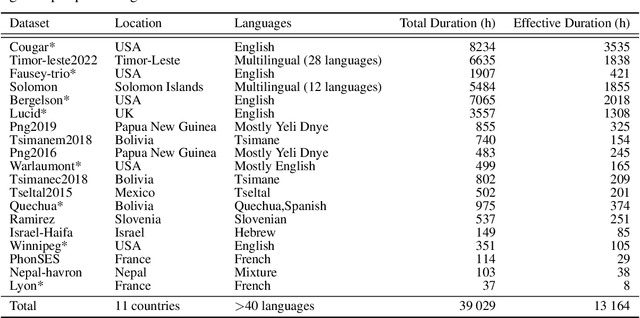
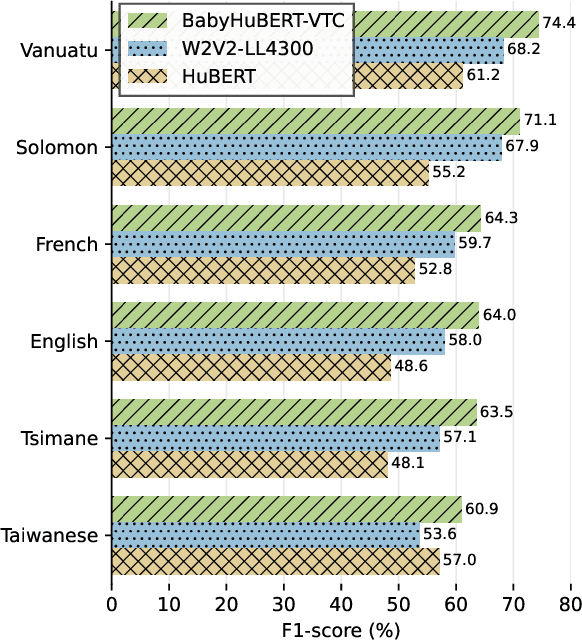
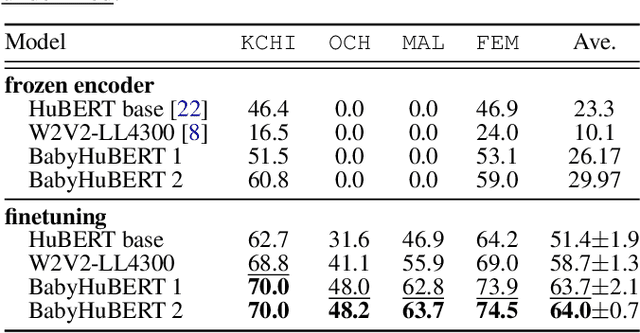
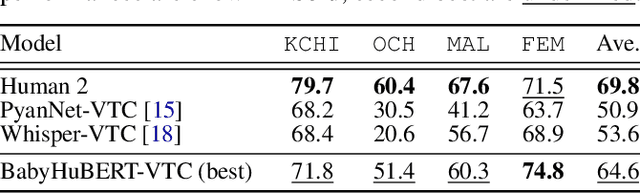
Child-centered long-form recordings are essential for studying early language development, but existing speech models trained on clean adult data perform poorly due to acoustic and linguistic differences. We introduce BabyHuBERT, the first self-supervised speech representation model trained on 13,000 hours of multilingual child-centered long-form recordings spanning over 40 languages. We evaluate BabyHuBERT on speaker segmentation, identifying when target children speak versus female adults, male adults, or other children -- a fundamental preprocessing step for analyzing naturalistic language experiences. BabyHuBERT achieves F1-scores from 52.1% to 74.4% across six diverse datasets, consistently outperforming W2V2-LL4300 (trained on English long-forms) and standard HuBERT (trained on clean adult speech). Notable improvements include 13.2 absolute F1 points over HuBERT on Vanuatu and 15.9 points on Solomon Islands corpora, demonstrating effectiveness on underrepresented languages. By sharing code and models, BabyHuBERT serves as a foundation model for child speech research, enabling fine-tuning on diverse downstream tasks.
fastabx: A library for efficient computation of ABX discriminability
May 05, 2025



We introduce fastabx, a high-performance Python library for building ABX discrimination tasks. ABX is a measure of the separation between generic categories of interest. It has been used extensively to evaluate phonetic discriminability in self-supervised speech representations. However, its broader adoption has been limited by the absence of adequate tools. fastabx addresses this gap by providing a framework capable of constructing any type of ABX task while delivering the efficiency necessary for rapid development cycles, both in task creation and in calculating distances between representations. We believe that fastabx will serve as a valuable resource for the broader representation learning community, enabling researchers to systematically investigate what information can be directly extracted from learned representations across several domains beyond speech processing. The source code is available at https://github.com/bootphon/fastabx.
Shennong: a Python toolbox for audio speech features extraction
Dec 10, 2021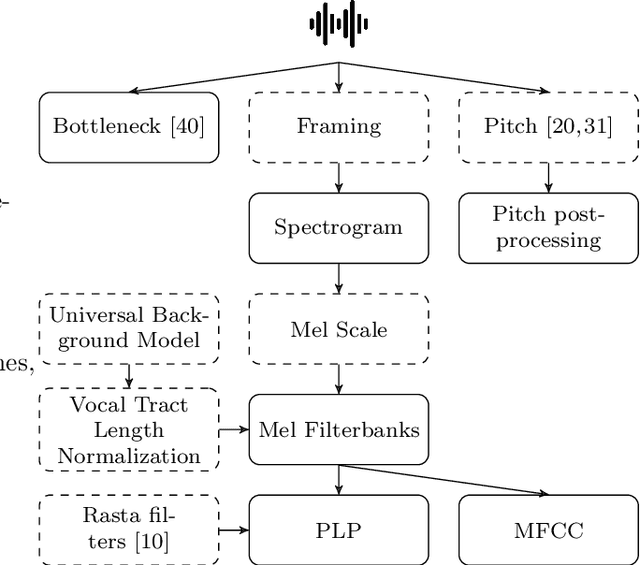
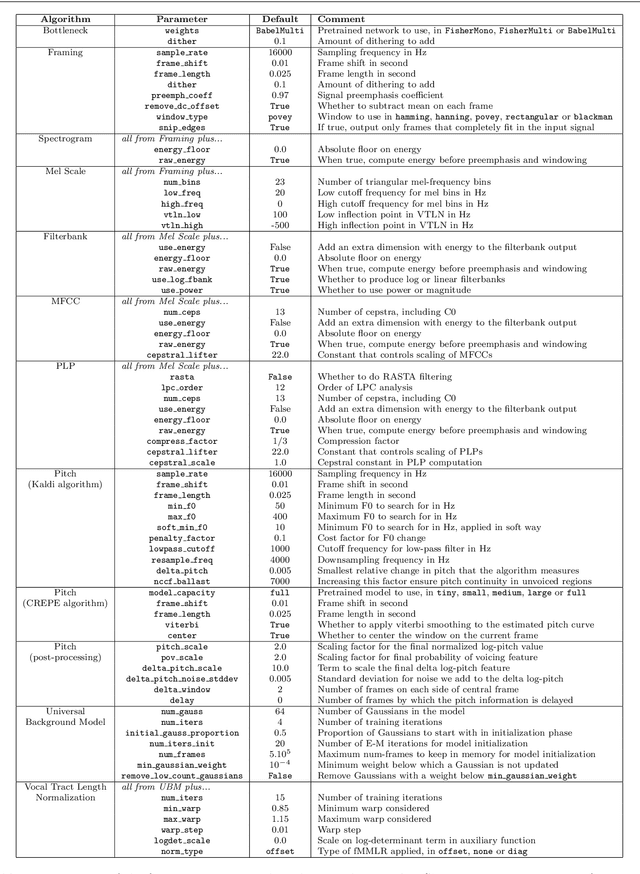
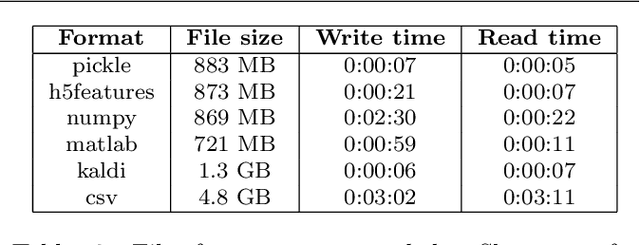
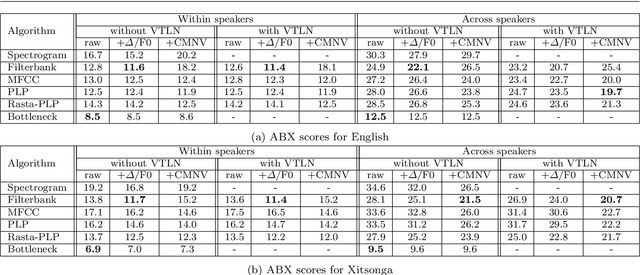
We introduce Shennong, a Python toolbox and command-line utility for speech features extraction. It implements a wide range of well-established state of art algorithms including spectro-temporal filters such as Mel-Frequency Cepstral Filterbanks or Predictive Linear Filters, pre-trained neural networks, pitch estimators as well as speaker normalization methods and post-processing algorithms. Shennong is an open source, easy-to-use, reliable and extensible framework. The use of Python makes the integration to others speech modeling and machine learning tools easy. It aims to replace or complement several heterogeneous software, such as Kaldi or Praat. After describing the Shennong software architecture, its core components and implemented algorithms, this paper illustrates its use on three applications: a comparison of speech features performances on a phones discrimination task, an analysis of a Vocal Tract Length Normalization model as a function of the speech duration used for training and a comparison of pitch estimation algorithms under various noise conditions.