 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpidR-Adapt: A Universal Speech Representation Model for Few-Shot Adaptation
Dec 24, 2025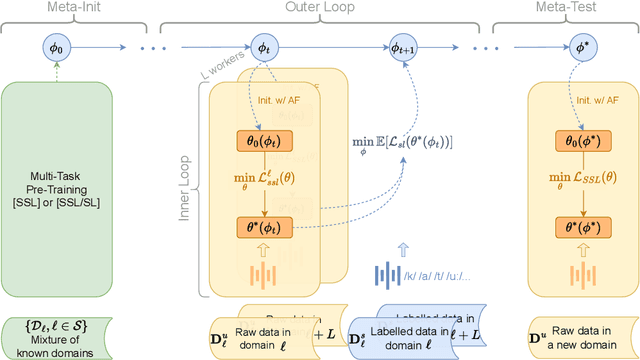

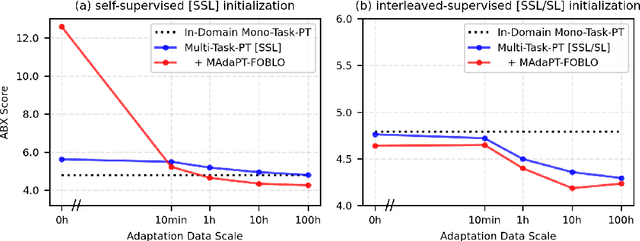
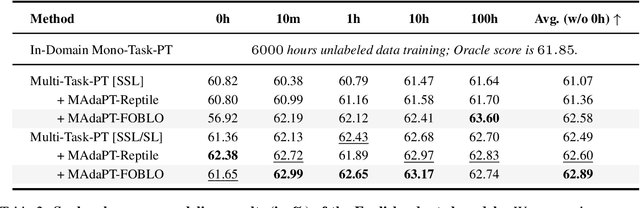
Human infants, with only a few hundred hours of speech exposure, acquire basic units of new languages, highlighting a striking efficiency gap compared to the data-hungry self-supervised speech models. To address this gap, this paper introduces SpidR-Adapt for rapid adaptation to new languages using minimal unlabeled data. We cast such low-resource speech representation learning as a meta-learning problem and construct a multi-task adaptive pre-training (MAdaPT) protocol which formulates the adaptation process as a bi-level optimization framework. To enable scalable meta-training under this framework, we propose a novel heuristic solution, first-order bi-level optimization (FOBLO), avoiding heavy computation costs. Finally, we stabilize meta-training by using a robust initialization through interleaved supervision which alternates self-supervised and supervised objectives. Empirically, SpidR-Adapt achieves rapid gains in phonemic discriminability (ABX) and spoken language modeling (sWUGGY, sBLIMP, tSC), improving over in-domain language models after training on less than 1h of target-language audio, over $100\times$ more data-efficient than standard training. These findings highlight a practical, architecture-agnostic path toward biologically inspired, data-efficient representations. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr-adapt.
Multilingual Pretraining for Pixel Language Models
May 27, 2025Pixel language models operate directly on images of rendered text, eliminating the need for a fixed vocabulary. While these models have demonstrated strong capabilities for downstream cross-lingual transfer, multilingual pretraining remains underexplored. We introduce PIXEL-M4, a model pretrained on four visually and linguistically diverse languages: English, Hindi, Ukrainian, and Simplified Chinese. Multilingual evaluations on semantic and syntactic tasks show that PIXEL-M4 outperforms an English-only counterpart on non-Latin scripts. Word-level probing analyses confirm that PIXEL-M4 captures rich linguistic features, even in languages not seen during pretraining. Furthermore, an analysis of its hidden representations shows that multilingual pretraining yields a semantic embedding space closely aligned across the languages used for pretraining. This work demonstrates that multilingual pretraining substantially enhances the capability of pixel language models to effectively support a diverse set of languages.
Evaluating Multimodal Language Models as Visual Assistants for Visually Impaired Users
Mar 28, 2025This paper explores the effectiveness of Multimodal Large Language models (MLLMs) as assistive technologies for visually impaired individuals. We conduct a user survey to identify adoption patterns and key challenges users face with such technologies. Despite a high adoption rate of these models, our findings highlight concerns related to contextual understanding, cultural sensitivity, and complex scene understanding, particularly for individuals who may rely solely on them for visual interpretation. Informed by these results, we collate five user-centred tasks with image and video inputs, including a novel task on Optical Braille Recognition. Our systematic evaluation of twelve MLLMs reveals that further advancements are necessary to overcome limitations related to cultural context, multilingual support, Braille reading comprehension, assistive object recognition, and hallucinations. This work provides critical insights into the future direction of multimodal AI for accessibility, underscoring the need for more inclusive, robust, and trustworthy visual assistance technologies.
Vision-Language Models under Cultural and Inclusive Considerations
Jul 08, 2024



Large vision-language models (VLMs) can assist visually impaired people by describing images from their daily lives. Current evaluation datasets may not reflect diverse cultural user backgrounds or the situational context of this use case. To address this problem, we create a survey to determine caption preferences and propose a culture-centric evaluation benchmark by filtering VizWiz, an existing dataset with images taken by people who are blind. We then evaluate several VLMs, investigating their reliability as visual assistants in a culturally diverse setting. While our results for state-of-the-art models are promising, we identify challenges such as hallucination and misalignment of automatic evaluation metrics with human judgment. We make our survey, data, code, and model outputs publicly available.
Towards Privacy-Aware Sign Language Translation at Scale
Feb 14, 2024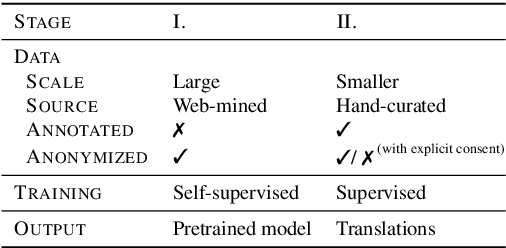

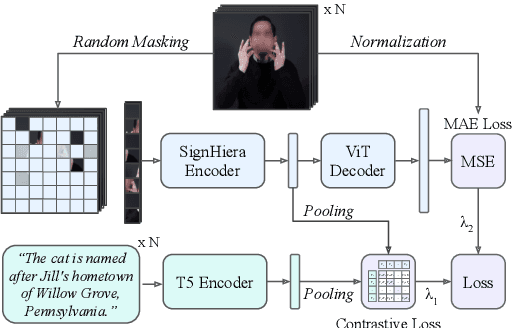
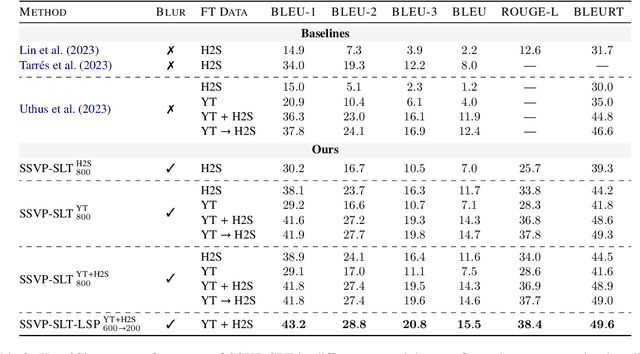
A major impediment to the advancement of sign language translation (SLT) is data scarcity. Much of the sign language data currently available on the web cannot be used for training supervised models due to the lack of aligned captions. Furthermore, scaling SLT using large-scale web-scraped datasets bears privacy risks due to the presence of biometric information, which the responsible development of SLT technologies should account for. In this work, we propose a two-stage framework for privacy-aware SLT at scale that addresses both of these issues. We introduce SSVP-SLT, which leverages self-supervised video pretraining on anonymized and unannotated videos, followed by supervised SLT finetuning on a curated parallel dataset. SSVP-SLT achieves state-of-the-art finetuned and zero-shot gloss-free SLT performance on the How2Sign dataset, outperforming the strongest respective baselines by over 3 BLEU-4. Based on controlled experiments, we further discuss the advantages and limitations of self-supervised pretraining and anonymization via facial obfuscation for SLT.
PHD: Pixel-Based Language Modeling of Historical Documents
Nov 04, 2023
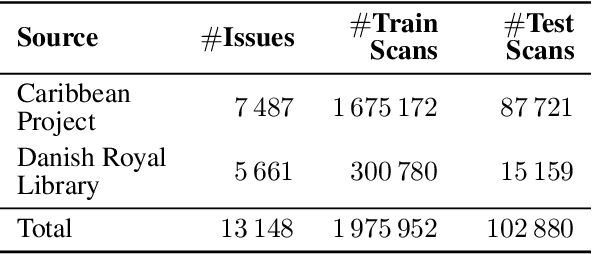

The digitisation of historical documents has provided historians with unprecedented research opportunities. Yet, the conventional approach to analysing historical documents involves converting them from images to text using OCR, a process that overlooks the potential benefits of treating them as images and introduces high levels of noise. To bridge this gap, we take advantage of recent advancements in pixel-based language models trained to reconstruct masked patches of pixels instead of predicting token distributions. Due to the scarcity of real historical scans, we propose a novel method for generating synthetic scans to resemble real historical documents. We then pre-train our model, PHD, on a combination of synthetic scans and real historical newspapers from the 1700-1900 period. Through our experiments, we demonstrate that PHD exhibits high proficiency in reconstructing masked image patches and provide evidence of our model's noteworthy language understanding capabilities. Notably, we successfully apply our model to a historical QA task, highlighting its usefulness in this domain.
Text Rendering Strategies for Pixel Language Models
Nov 01, 2023



Pixel-based language models process text rendered as images, which allows them to handle any script, making them a promising approach to open vocabulary language modelling. However, recent approaches use text renderers that produce a large set of almost-equivalent input patches, which may prove sub-optimal for downstream tasks, due to redundancy in the input representations. In this paper, we investigate four approaches to rendering text in the PIXEL model (Rust et al., 2023), and find that simple character bigram rendering brings improved performance on sentence-level tasks without compromising performance on token-level or multilingual tasks. This new rendering strategy also makes it possible to train a more compact model with only 22M parameters that performs on par with the original 86M parameter model. Our analyses show that character bigram rendering leads to a consistently better model but with an anisotropic patch embedding space, driven by a patch frequency bias, highlighting the connections between image patch- and tokenization-based language models.
Differential Privacy, Linguistic Fairness, and Training Data Influence: Impossibility and Possibility Theorems for Multilingual Language Models
Aug 17, 2023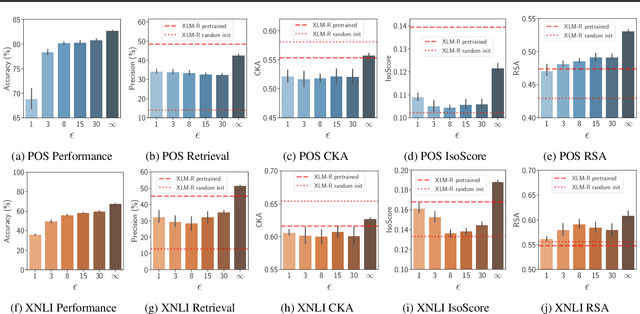

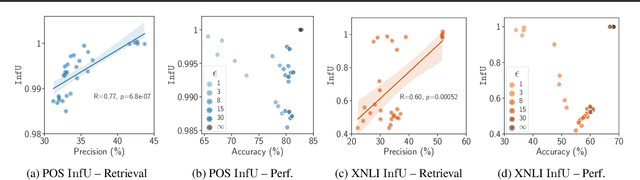
Language models such as mBERT, XLM-R, and BLOOM aim to achieve multilingual generalization or compression to facilitate transfer to a large number of (potentially unseen) languages. However, these models should ideally also be private, linguistically fair, and transparent, by relating their predictions to training data. Can these requirements be simultaneously satisfied? We show that multilingual compression and linguistic fairness are compatible with differential privacy, but that differential privacy is at odds with training data influence sparsity, an objective for transparency. We further present a series of experiments on two common NLP tasks and evaluate multilingual compression and training data influence sparsity under different privacy guarantees, exploring these trade-offs in more detail. Our results suggest that we need to develop ways to jointly optimize for these objectives in order to find practical trade-offs.
Language Modelling with Pixels
Jul 14, 2022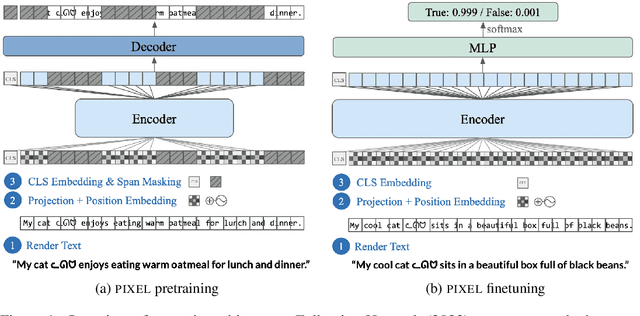
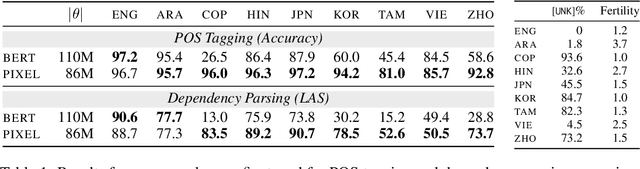


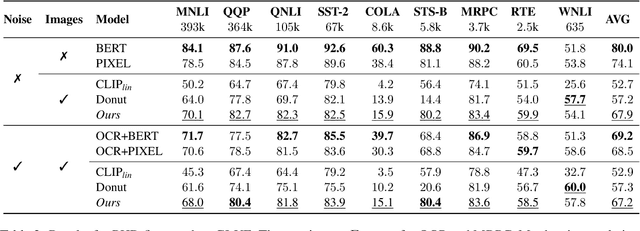
Language models are defined over a finite set of inputs, which creates a vocabulary bottleneck when we attempt to scale the number of supported languages. Tackling this bottleneck results in a trade-off between what can be represented in the embedding matrix and computational issues in the output layer. This paper introduces PIXEL, the Pixel-based Encoder of Language, which suffers from neither of these issues. PIXEL is a pretrained language model that renders text as images, making it possible to transfer representations across languages based on orthographic similarity or the co-activation of pixels. PIXEL is trained to reconstruct the pixels of masked patches, instead of predicting a distribution over tokens. We pretrain the 86M parameter PIXEL model on the same English data as BERT and evaluate on syntactic and semantic tasks in typologically diverse languages, including various non-Latin scripts. We find that PIXEL substantially outperforms BERT on syntactic and semantic processing tasks on scripts that are not found in the pretraining data, but PIXEL is slightly weaker than BERT when working with Latin scripts. Furthermore, we find that PIXEL is more robust to noisy text inputs than BERT, further confirming the benefits of modelling language with pixels.
Challenges and Strategies in Cross-Cultural NLP
Mar 18, 2022
Various efforts in the Natural Language Processing (NLP) community have been made to accommodate linguistic diversity and serve speakers of many different languages. However, it is important to acknowledge that speakers and the content they produce and require, vary not just by language, but also by culture. Although language and culture are tightly linked, there are important differences. Analogous to cross-lingual and multilingual NLP, cross-cultural and multicultural NLP considers these differences in order to better serve users of NLP systems. We propose a principled framework to frame these efforts, and survey existing and potential strategies.