 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models
Paper and Code

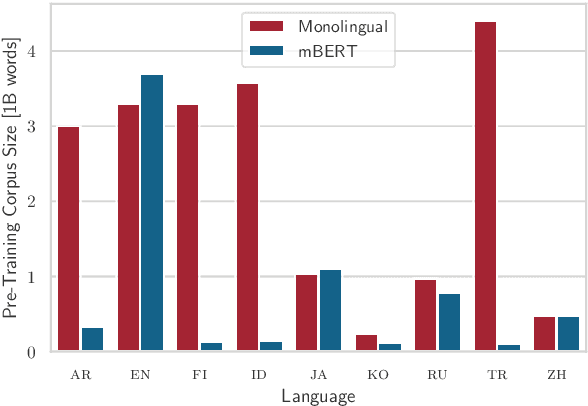
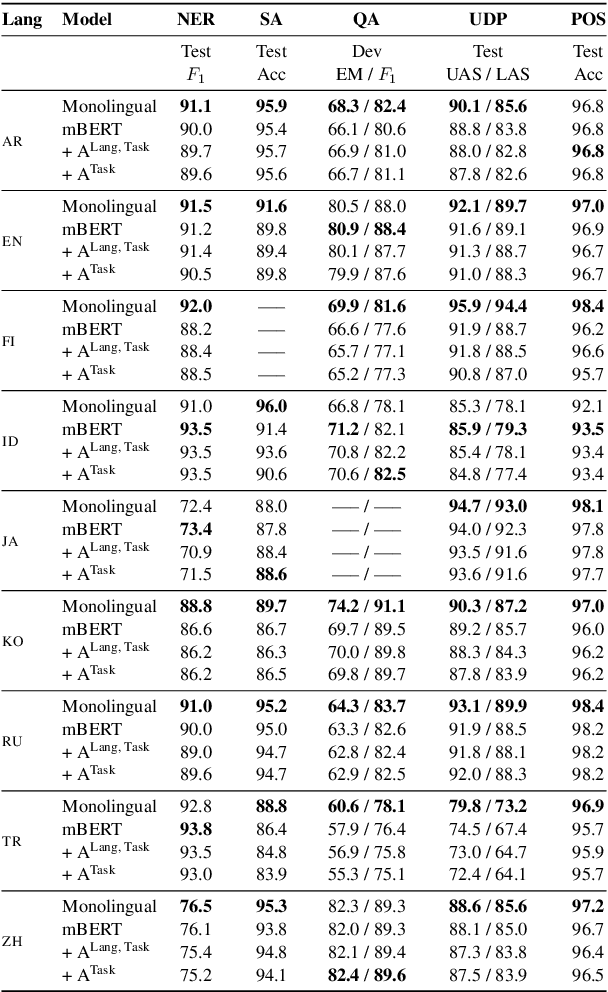
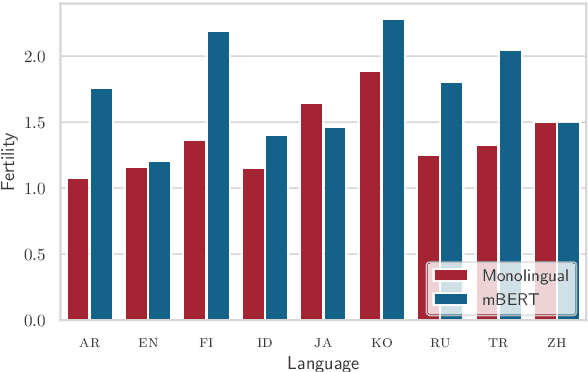
In this work we provide a \textit{systematic empirical comparison} of pretrained multilingual language models versus their monolingual counterparts with regard to their monolingual task performance. We study a set of nine typologically diverse languages with readily available pretrained monolingual models on a set of five diverse monolingual downstream tasks. We first establish if a gap between the multilingual and the corresponding monolingual representation of that language exists, and subsequently investigate the reason for a performance difference. To disentangle the impacting variables, we train new monolingual models on the same data, but with different tokenizers, both the monolingual and the multilingual version. We find that while the pretraining data size is an important factor, the designated tokenizer of the monolingual model plays an equally important role in the downstream performance. Our results show that languages which are adequately represented in the multilingual model's vocabulary exhibit negligible performance decreases over their monolingual counterparts. We further find that replacing the original multilingual tokenizer with the specialized monolingual tokenizer improves the downstream performance of the multilingual model for almost every task and language.