 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-Squeeze: Simple and Effective Post-Tuning and In-Tuning Compression of LoRA Modules
Feb 11, 2026Despite its huge number of variants, standard Low-Rank Adaptation (LoRA) is still a dominant technique for parameter-efficient fine-tuning (PEFT). Nonetheless, it faces persistent challenges, including the pre-selection of an optimal rank and rank-specific hyper-parameters, as well as the deployment complexity of heterogeneous-rank modules and more sophisticated LoRA derivatives. In this work, we introduce LoRA-Squeeze, a simple and efficient methodology that aims to improve standard LoRA learning by changing LoRA module ranks either post-hoc or dynamically during training}. Our approach posits that it is better to first learn an expressive, higher-rank solution and then compress it, rather than learning a constrained, low-rank solution directly. The method involves fine-tuning with a deliberately high(er) source rank, reconstructing or efficiently approximating the reconstruction of the full weight update matrix, and then using Randomized Singular Value Decomposition (RSVD) to create a new, compressed LoRA module at a lower target rank. Extensive experiments across 13 text and 10 vision-language tasks show that post-hoc compression often produces lower-rank adapters that outperform those trained directly at the target rank, especially if a small number of fine-tuning steps at the target rank is allowed. Moreover, a gradual, in-tuning rank annealing variant of LoRA-Squeeze consistently achieves the best LoRA size-performance trade-off.
Deliberation in Latent Space via Differentiable Cache Augmentation
Dec 23, 2024



Techniques enabling large language models (LLMs) to "think more" by generating and attending to intermediate reasoning steps have shown promise in solving complex problems. However, the standard approaches generate sequences of discrete tokens immediately before responding, and so they can incur significant latency costs and be challenging to optimize. In this work, we demonstrate that a frozen LLM can be augmented with an offline coprocessor that operates on the model's key-value (kv) cache. This coprocessor augments the cache with a set of latent embeddings designed to improve the fidelity of subsequent decoding. We train this coprocessor using the language modeling loss from the decoder on standard pretraining data, while keeping the decoder itself frozen. This approach enables the model to learn, in an end-to-end differentiable fashion, how to distill additional computation into its kv-cache. Because the decoder remains unchanged, the coprocessor can operate offline and asynchronously, and the language model can function normally if the coprocessor is unavailable or if a given cache is deemed not to require extra computation. We show experimentally that when a cache is augmented, the decoder achieves lower perplexity on numerous subsequent tokens. Furthermore, even without any task-specific training, our experiments demonstrate that cache augmentation consistently reduces perplexity and improves performance across a range of reasoning-intensive tasks.
Towards Optimal Adapter Placement for Efficient Transfer Learning
Oct 21, 2024



Parameter-efficient transfer learning (PETL) aims to adapt pre-trained models to new downstream tasks while minimizing the number of fine-tuned parameters. Adapters, a popular approach in PETL, inject additional capacity into existing networks by incorporating low-rank projections, achieving performance comparable to full fine-tuning with significantly fewer parameters. This paper investigates the relationship between the placement of an adapter and its performance. We observe that adapter location within a network significantly impacts its effectiveness, and that the optimal placement is task-dependent. To exploit this observation, we introduce an extended search space of adapter connections, including long-range and recurrent adapters. We demonstrate that even randomly selected adapter placements from this expanded space yield improved results, and that high-performing placements often correlate with high gradient rank. Our findings reveal that a small number of strategically placed adapters can match or exceed the performance of the common baseline of adding adapters in every block, opening a new avenue for research into optimal adapter placement strategies.
DARE: Diverse Visual Question Answering with Robustness Evaluation
Sep 26, 2024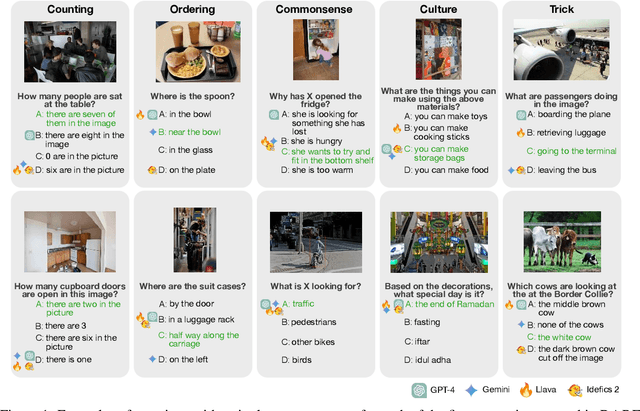
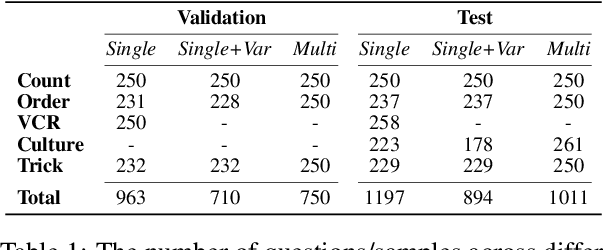


Vision Language Models (VLMs) extend remarkable capabilities of text-only large language models and vision-only models, and are able to learn from and process multi-modal vision-text input. While modern VLMs perform well on a number of standard image classification and image-text matching tasks, they still struggle with a number of crucial vision-language (VL) reasoning abilities such as counting and spatial reasoning. Moreover, while they might be very brittle to small variations in instructions and/or evaluation protocols, existing benchmarks fail to evaluate their robustness (or rather the lack of it). In order to couple challenging VL scenarios with comprehensive robustness evaluation, we introduce DARE, Diverse Visual Question Answering with Robustness Evaluation, a carefully created and curated multiple-choice VQA benchmark. DARE evaluates VLM performance on five diverse categories and includes four robustness-oriented evaluations based on the variations of: prompts, the subsets of answer options, the output format and the number of correct answers. Among a spectrum of other findings, we report that state-of-the-art VLMs still struggle with questions in most categories and are unable to consistently deliver their peak performance across the tested robustness evaluations. The worst case performance across the subsets of options is up to 34% below the performance in the standard case. The robustness of the open-source VLMs such as LLaVA 1.6 and Idefics2 cannot match the closed-source models such as GPT-4 and Gemini, but even the latter remain very brittle to different variations.
M2QA: Multi-domain Multilingual Question Answering
Jul 01, 2024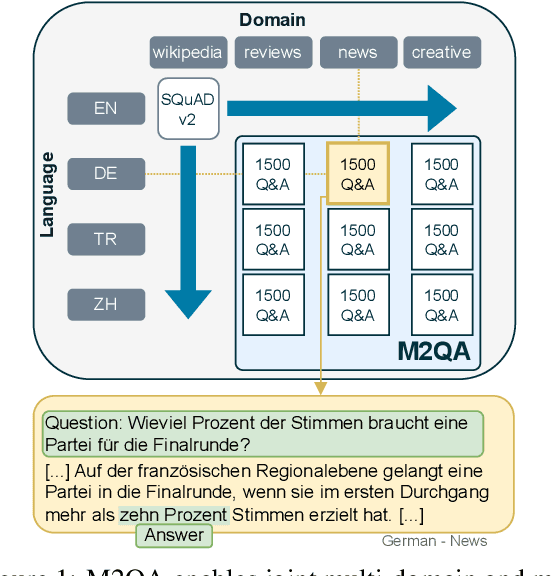

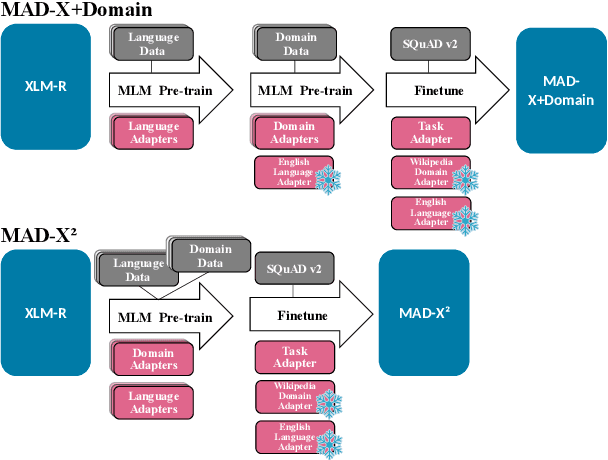

Generalization and robustness to input variation are core desiderata of machine learning research. Language varies along several axes, most importantly, language instance (e.g. French) and domain (e.g. news). While adapting NLP models to new languages within a single domain, or to new domains within a single language, is widely studied, research in joint adaptation is hampered by the lack of evaluation datasets. This prevents the transfer of NLP systems from well-resourced languages and domains to non-dominant language-domain combinations. To address this gap, we introduce M2QA, a multi-domain multilingual question answering benchmark. M2QA includes 13,500 SQuAD 2.0-style question-answer instances in German, Turkish, and Chinese for the domains of product reviews, news, and creative writing. We use M2QA to explore cross-lingual cross-domain performance of fine-tuned models and state-of-the-art LLMs and investigate modular approaches to domain and language adaptation. We witness 1) considerable performance variations across domain-language combinations within model classes and 2) considerable performance drops between source and target language-domain combinations across all model sizes. We demonstrate that M2QA is far from solved, and new methods to effectively transfer both linguistic and domain-specific information are necessary. We make M2QA publicly available at https://github.com/UKPLab/m2qa.
Adapters: A Unified Library for Parameter-Efficient and Modular Transfer Learning
Nov 18, 2023We introduce Adapters, an open-source library that unifies parameter-efficient and modular transfer learning in large language models. By integrating 10 diverse adapter methods into a unified interface, Adapters offers ease of use and flexible configuration. Our library allows researchers and practitioners to leverage adapter modularity through composition blocks, enabling the design of complex adapter setups. We demonstrate the library's efficacy by evaluating its performance against full fine-tuning on various NLP tasks. Adapters provides a powerful tool for addressing the challenges of conventional fine-tuning paradigms and promoting more efficient and modular transfer learning. The library is available via https://adapterhub.ml/adapters.
Language and Task Arithmetic with Parameter-Efficient Layers for Zero-Shot Summarization
Nov 15, 2023

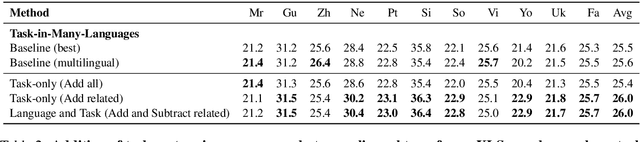

Parameter-efficient fine-tuning (PEFT) using labeled task data can significantly improve the performance of large language models (LLMs) on the downstream task. However, there are 7000 languages in the world and many of these languages lack labeled data for real-world language generation tasks. In this paper, we propose to improve zero-shot cross-lingual transfer by composing language or task specialized parameters. Our method composes language and task PEFT modules via element-wise arithmetic operations to leverage unlabeled data and English labeled data. We extend our approach to cases where labeled data from more languages is available and propose to arithmetically compose PEFT modules trained on languages related to the target. Empirical results on summarization demonstrate that our method is an effective strategy that obtains consistent gains using minimal training of PEFT modules.
Where's the Point? Self-Supervised Multilingual Punctuation-Agnostic Sentence Segmentation
May 30, 2023

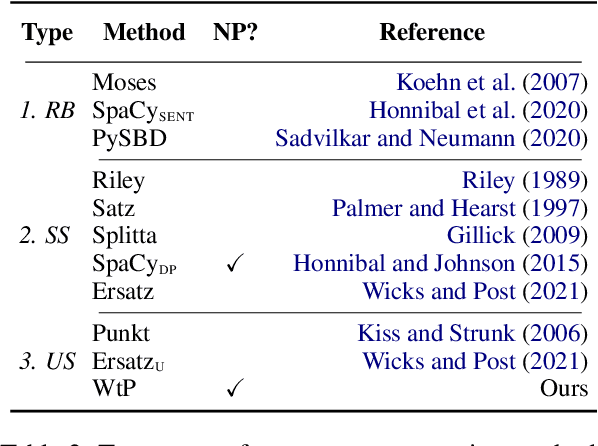
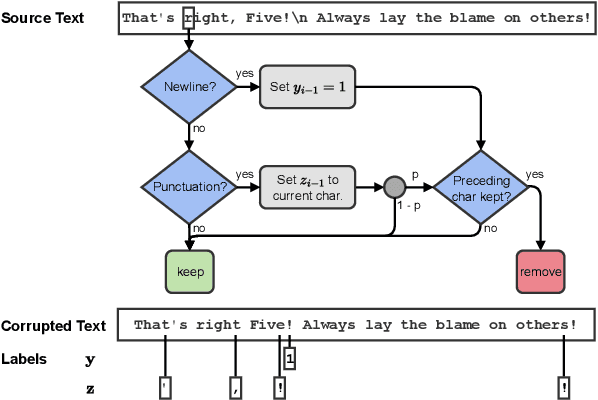
Many NLP pipelines split text into sentences as one of the crucial preprocessing steps. Prior sentence segmentation tools either rely on punctuation or require a considerable amount of sentence-segmented training data: both central assumptions might fail when porting sentence segmenters to diverse languages on a massive scale. In this work, we thus introduce a multilingual punctuation-agnostic sentence segmentation method, currently covering 85 languages, trained in a self-supervised fashion on unsegmented text, by making use of newline characters which implicitly perform segmentation into paragraphs. We further propose an approach that adapts our method to the segmentation in a given corpus by using only a small number (64-256) of sentence-segmented examples. The main results indicate that our method outperforms all the prior best sentence-segmentation tools by an average of 6.1% F1 points. Furthermore, we demonstrate that proper sentence segmentation has a point: the use of a (powerful) sentence segmenter makes a considerable difference for a downstream application such as machine translation (MT). By using our method to match sentence segmentation to the segmentation used during training of MT models, we achieve an average improvement of 2.3 BLEU points over the best prior segmentation tool, as well as massive gains over a trivial segmenter that splits text into equally sized blocks.
mmT5: Modular Multilingual Pre-Training Solves Source Language Hallucinations
May 23, 2023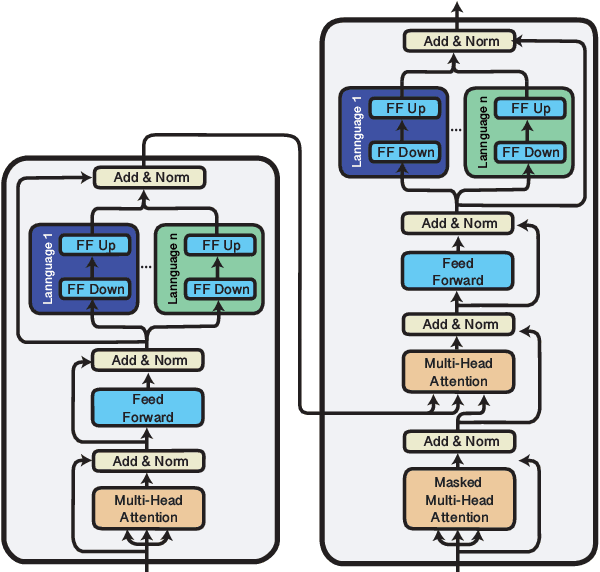



Multilingual sequence-to-sequence models perform poorly with increased language coverage and fail to consistently generate text in the correct target language in few-shot settings. To address these challenges, we propose mmT5, a modular multilingual sequence-to-sequence model. mmT5 utilizes language-specific modules during pre-training, which disentangle language-specific information from language-agnostic information. We identify representation drift during fine-tuning as a key limitation of modular generative models and develop strategies that enable effective zero-shot transfer. Our model outperforms mT5 at the same parameter sizes by a large margin on representative natural language understanding and generation tasks in 40+ languages. Compared to mT5, mmT5 raises the rate of generating text in the correct language under zero-shot settings from 7% to 99%, thereby greatly alleviating the source language hallucination problem.
CompoundPiece: Evaluating and Improving Decompounding Performance of Language Models
May 23, 2023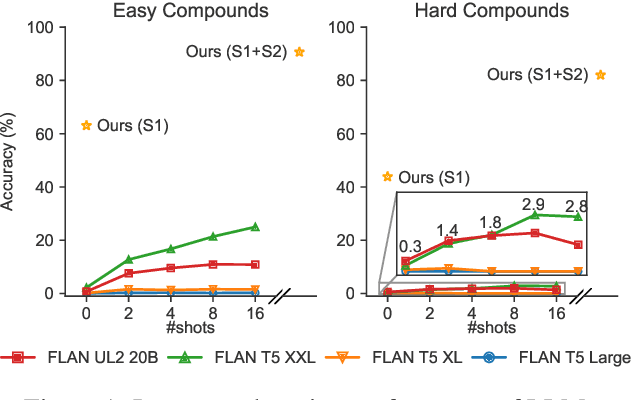
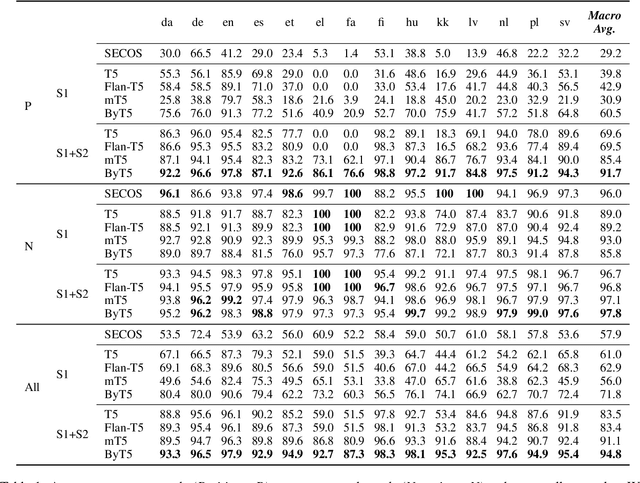

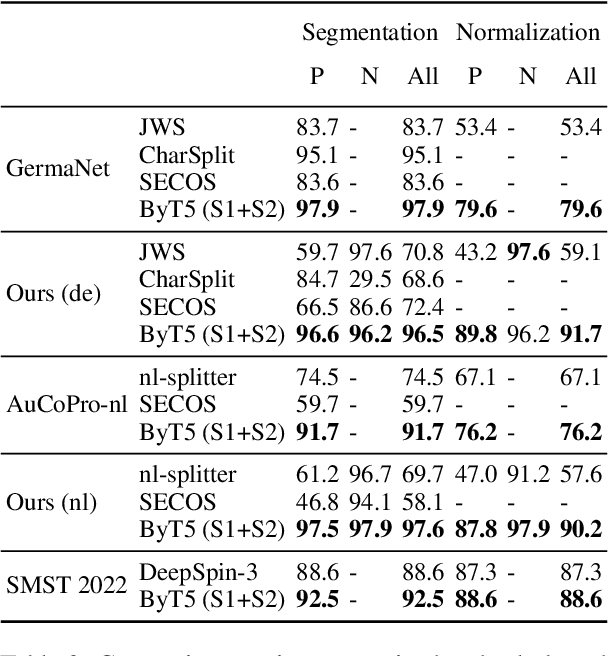
While many languages possess processes of joining two or more words to create compound words, previous studies have been typically limited only to languages with excessively productive compound formation (e.g., German, Dutch) and there is no public dataset containing compound and non-compound words across a large number of languages. In this work, we systematically study decompounding, the task of splitting compound words into their constituents, at a wide scale. We first address the data gap by introducing a dataset of 255k compound and non-compound words across 56 diverse languages obtained from Wiktionary. We then use this dataset to evaluate an array of Large Language Models (LLMs) on the decompounding task. We find that LLMs perform poorly, especially on words which are tokenized unfavorably by subword tokenization. We thus introduce a novel methodology to train dedicated models for decompounding. The proposed two-stage procedure relies on a fully self-supervised objective in the first stage, while the second, supervised learning stage optionally fine-tunes the model on the annotated Wiktionary data. Our self-supervised models outperform the prior best unsupervised decompounding models by 13.9% accuracy on average. Our fine-tuned models outperform all prior (language-specific) decompounding tools. Furthermore, we use our models to leverage decompounding during the creation of a subword tokenizer, which we refer to as CompoundPiece. CompoundPiece tokenizes compound words more favorably on average, leading to improved performance on decompounding over an otherwise equivalent model using SentencePiece tokenization.