 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere's the Point? Self-Supervised Multilingual Punctuation-Agnostic Sentence Segmentation
Paper and Code


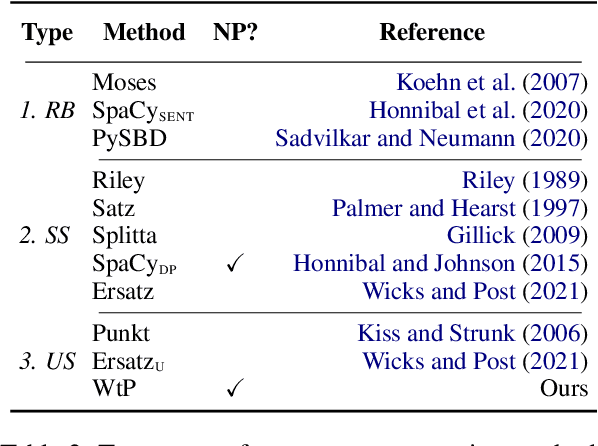
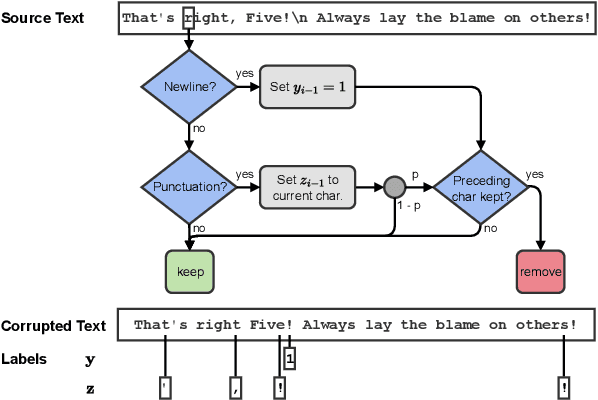
Many NLP pipelines split text into sentences as one of the crucial preprocessing steps. Prior sentence segmentation tools either rely on punctuation or require a considerable amount of sentence-segmented training data: both central assumptions might fail when porting sentence segmenters to diverse languages on a massive scale. In this work, we thus introduce a multilingual punctuation-agnostic sentence segmentation method, currently covering 85 languages, trained in a self-supervised fashion on unsegmented text, by making use of newline characters which implicitly perform segmentation into paragraphs. We further propose an approach that adapts our method to the segmentation in a given corpus by using only a small number (64-256) of sentence-segmented examples. The main results indicate that our method outperforms all the prior best sentence-segmentation tools by an average of 6.1% F1 points. Furthermore, we demonstrate that proper sentence segmentation has a point: the use of a (powerful) sentence segmenter makes a considerable difference for a downstream application such as machine translation (MT). By using our method to match sentence segmentation to the segmentation used during training of MT models, we achieve an average improvement of 2.3 BLEU points over the best prior segmentation tool, as well as massive gains over a trivial segmenter that splits text into equally sized blocks.