 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage and Task Arithmetic with Parameter-Efficient Layers for Zero-Shot Summarization
Paper and Code


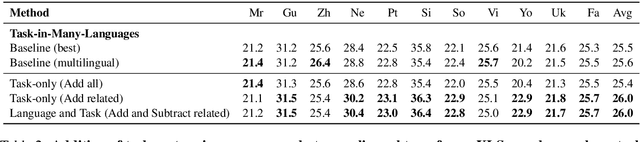

Parameter-efficient fine-tuning (PEFT) using labeled task data can significantly improve the performance of large language models (LLMs) on the downstream task. However, there are 7000 languages in the world and many of these languages lack labeled data for real-world language generation tasks. In this paper, we propose to improve zero-shot cross-lingual transfer by composing language or task specialized parameters. Our method composes language and task PEFT modules via element-wise arithmetic operations to leverage unlabeled data and English labeled data. We extend our approach to cases where labeled data from more languages is available and propose to arithmetically compose PEFT modules trained on languages related to the target. Empirical results on summarization demonstrate that our method is an effective strategy that obtains consistent gains using minimal training of PEFT modules.