 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECLeKTic: a Novel Challenge Set for Evaluation of Cross-Lingual Knowledge Transfer
Feb 28, 2025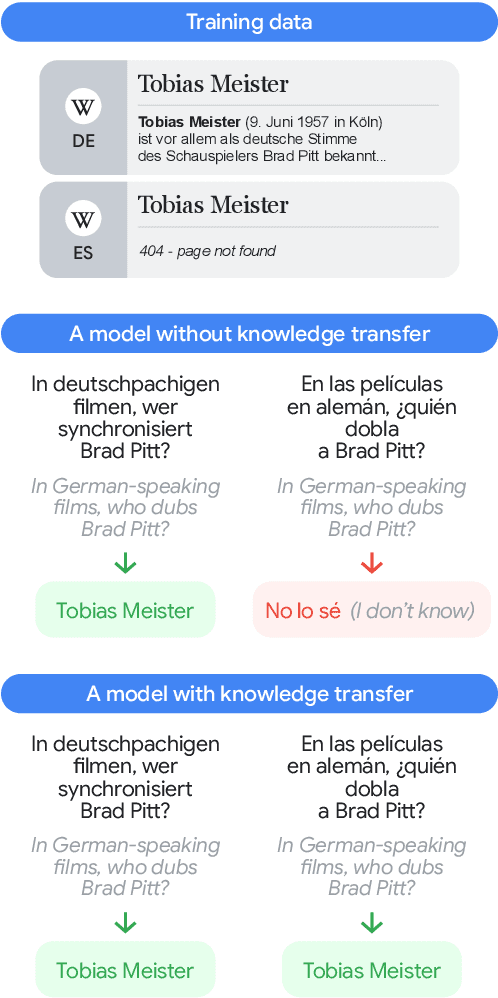
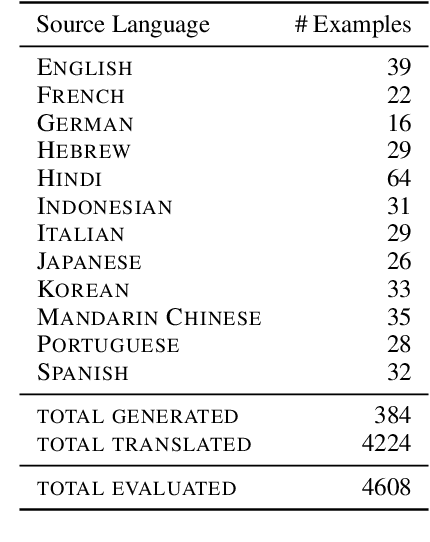
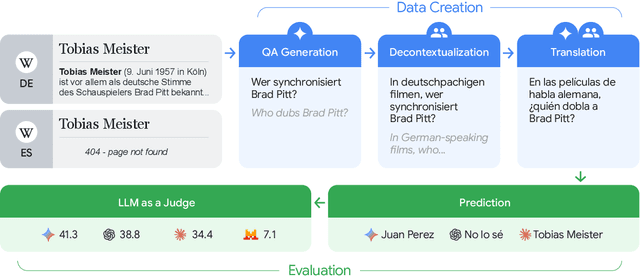
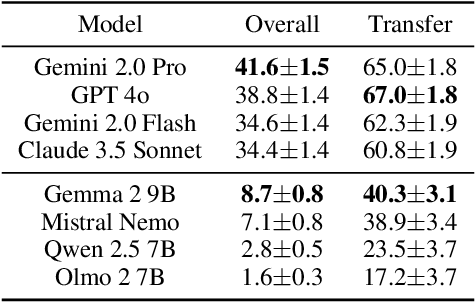
To achieve equitable performance across languages, multilingual large language models (LLMs) must be able to abstract knowledge beyond the language in which it was acquired. However, the current literature lacks reliable ways to measure LLMs' capability of cross-lingual knowledge transfer. To that end, we present ECLeKTic, a multilingual closed-book QA (CBQA) dataset that Evaluates Cross-Lingual Knowledge Transfer in a simple, black-box manner. We detected information with uneven coverage across languages by controlling for presence and absence of Wikipedia articles in 12 languages. We generated knowledge-seeking questions in a source language, for which the answer appears in a relevant Wikipedia article and translated them to all other 11 languages, for which the respective Wikipedias lack equivalent articles. Assuming that Wikipedia reflects the prominent knowledge in the LLM's training data, to solve ECLeKTic's CBQA task the model is required to transfer knowledge between languages. Experimenting with 8 LLMs, we show that SOTA models struggle to effectively share knowledge across, languages even if they can predict the answer well for queries in the same language the knowledge was acquired in.
Stratified Prediction-Powered Inference for Hybrid Language Model Evaluation
Jun 06, 2024

Prediction-powered inference (PPI) is a method that improves statistical estimates based on limited human-labeled data. PPI achieves this by combining small amounts of human-labeled data with larger amounts of data labeled by a reasonably accurate -- but potentially biased -- automatic system, in a way that results in tighter confidence intervals for certain parameters of interest (e.g., the mean performance of a language model). In this paper, we propose a method called Stratified Prediction-Powered Inference (StratPPI), in which we show that the basic PPI estimates can be considerably improved by employing simple data stratification strategies. Without making any assumptions on the underlying automatic labeling system or data distribution, we derive an algorithm for computing provably valid confidence intervals for population parameters (such as averages) that is based on stratified sampling. In particular, we show both theoretically and empirically that, with appropriate choices of stratification and sample allocation, our approach can provide substantially tighter confidence intervals than unstratified approaches. Specifically, StratPPI is expected to improve in cases where the performance of the autorater varies across different conditional distributions of the target data.
Bayesian Prediction-Powered Inference
May 09, 2024Prediction-powered inference (PPI) is a method that improves statistical estimates based on limited human-labeled data. Specifically, PPI methods provide tighter confidence intervals by combining small amounts of human-labeled data with larger amounts of data labeled by a reasonably accurate, but potentially biased, automatic system. We propose a framework for PPI based on Bayesian inference that allows researchers to develop new task-appropriate PPI methods easily. Exploiting the ease with which we can design new metrics, we propose improved PPI methods for several importantcases, such as autoraters that give discrete responses (e.g., prompted LLM ``judges'') and autoraters with scores that have a non-linear relationship to human scores.
Learning to Plan and Generate Text with Citations
Apr 04, 2024The increasing demand for the deployment of LLMs in information-seeking scenarios has spurred efforts in creating verifiable systems, which generate responses to queries along with supporting evidence. In this paper, we explore the attribution capabilities of plan-based models which have been recently shown to improve the faithfulness, grounding, and controllability of generated text. We conceptualize plans as a sequence of questions which serve as blueprints of the generated content and its organization. We propose two attribution models that utilize different variants of blueprints, an abstractive model where questions are generated from scratch, and an extractive model where questions are copied from the input. Experiments on long-form question-answering show that planning consistently improves attribution quality. Moreover, the citations generated by blueprint models are more accurate compared to those obtained from LLM-based pipelines lacking a planning component.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Language and Task Arithmetic with Parameter-Efficient Layers for Zero-Shot Summarization
Nov 15, 2023

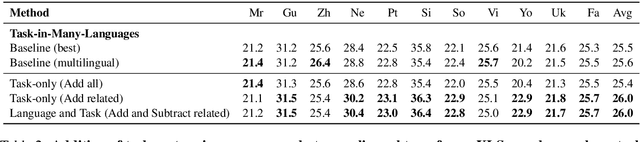

Parameter-efficient fine-tuning (PEFT) using labeled task data can significantly improve the performance of large language models (LLMs) on the downstream task. However, there are 7000 languages in the world and many of these languages lack labeled data for real-world language generation tasks. In this paper, we propose to improve zero-shot cross-lingual transfer by composing language or task specialized parameters. Our method composes language and task PEFT modules via element-wise arithmetic operations to leverage unlabeled data and English labeled data. We extend our approach to cases where labeled data from more languages is available and propose to arithmetically compose PEFT modules trained on languages related to the target. Empirical results on summarization demonstrate that our method is an effective strategy that obtains consistent gains using minimal training of PEFT modules.
Calibrating Likelihoods towards Consistency in Summarization Models
Oct 12, 2023Despite the recent advances in abstractive text summarization, current summarization models still suffer from generating factually inconsistent summaries, reducing their utility for real-world application. We argue that the main reason for such behavior is that the summarization models trained with maximum likelihood objective assign high probability to plausible sequences given the context, but they often do not accurately rank sequences by their consistency. In this work, we solve this problem by calibrating the likelihood of model generated sequences to better align with a consistency metric measured by natural language inference (NLI) models. The human evaluation study and automatic metrics show that the calibrated models generate more consistent and higher-quality summaries. We also show that the models trained using our method return probabilities that are better aligned with the NLI scores, which significantly increase reliability of summarization models.
Benchmarking Large Language Model Capabilities for Conditional Generation
Jun 29, 2023Pre-trained large language models (PLMs) underlie most new developments in natural language processing. They have shifted the field from application-specific model pipelines to a single model that is adapted to a wide range of tasks. Autoregressive PLMs like GPT-3 or PaLM, alongside techniques like few-shot learning, have additionally shifted the output modality to generation instead of classification or regression. Despite their ubiquitous use, the generation quality of language models is rarely evaluated when these models are introduced. Additionally, it is unclear how existing generation tasks--while they can be used to compare systems at a high level--relate to the real world use cases for which people have been adopting them. In this work, we discuss how to adapt existing application-specific generation benchmarks to PLMs and provide an in-depth, empirical study of the limitations and capabilities of PLMs in natural language generation tasks along dimensions such as scale, architecture, input and output language. Our results show that PLMs differ in their applicability to different data regimes and their generalization to multiple languages and inform which PLMs to use for a given generation task setup. We share best practices to be taken into consideration when benchmarking generation capabilities during the development of upcoming PLMs.
$μ$PLAN: Summarizing using a Content Plan as Cross-Lingual Bridge
May 23, 2023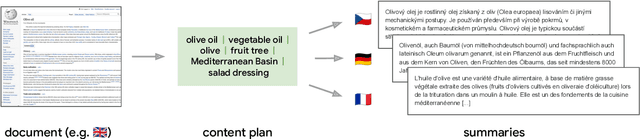
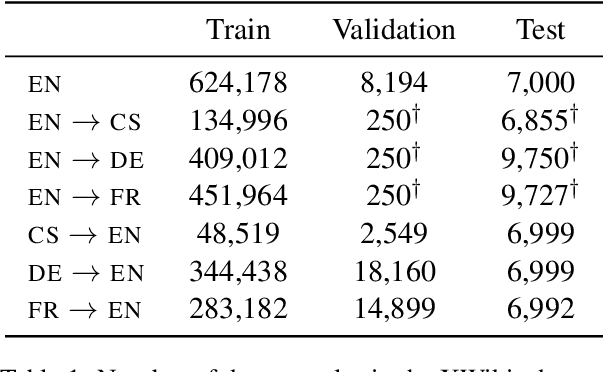


Cross-lingual summarization consists of generating a summary in one language given an input document in a different language, allowing for the dissemination of relevant content across speakers of other languages. However, this task remains challenging, mainly because of the need for cross-lingual datasets and the compounded difficulty of summarizing and translating. This work presents $\mu$PLAN, an approach to cross-lingual summarization that uses an intermediate planning step as a cross-lingual bridge. We formulate the plan as a sequence of entities that captures the conceptualization of the summary, i.e. identifying the salient content and expressing in which order to present the information, separate from the surface form. Using a multilingual knowledge base, we align the entities to their canonical designation across languages. $\mu$PLAN models first learn to generate the plan and then continue generating the summary conditioned on the plan and the input. We evaluate our methodology on the XWikis dataset on cross-lingual pairs across four languages and demonstrate that this planning objective achieves state-of-the-art performance in terms of ROUGE and faithfulness scores. Moreover, this planning approach improves the zero-shot transfer to new cross-lingual language pairs compared to non-planning baselines.
SEAHORSE: A Multilingual, Multifaceted Dataset for Summarization Evaluation
May 22, 2023
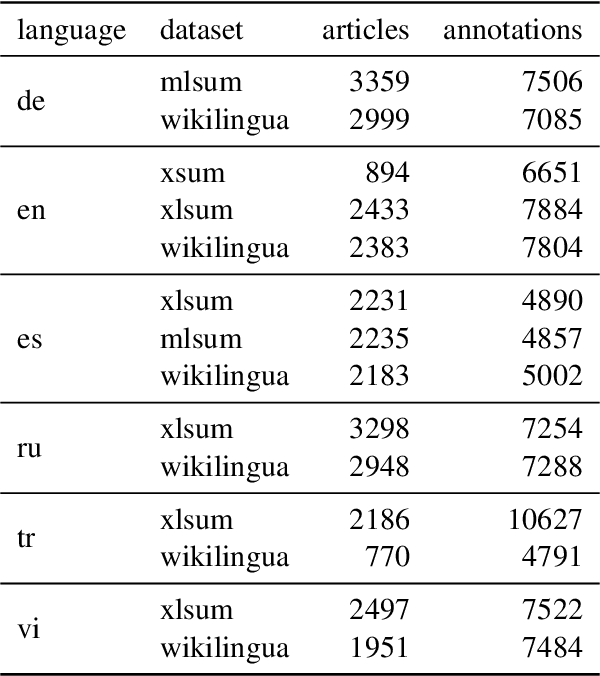
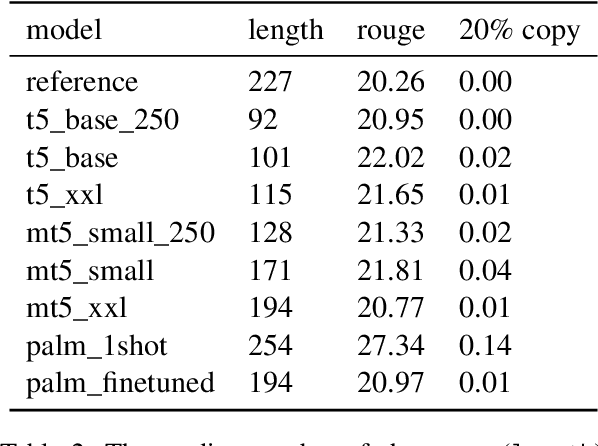
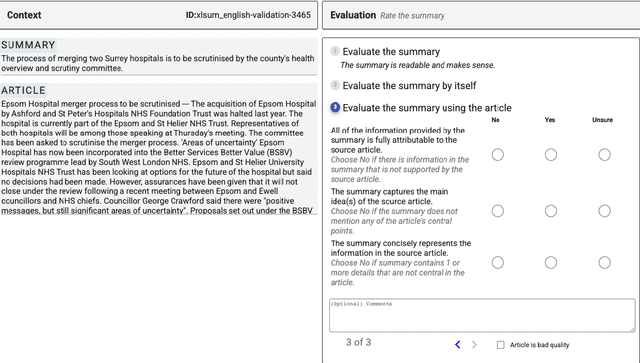
Reliable automatic evaluation of summarization systems is challenging due to the multifaceted and subjective nature of the task. This is especially the case for languages other than English, where human evaluations are scarce. In this work, we introduce SEAHORSE, a dataset for multilingual, multifaceted summarization evaluation. SEAHORSE consists of 96K summaries with human ratings along 6 quality dimensions: comprehensibility, repetition, grammar, attribution, main ideas, and conciseness, covering 6 languages, 9 systems and 4 datasets. As a result of its size and scope, SEAHORSE can serve both as a benchmark to evaluate learnt metrics, as well as a large-scale resource for training such metrics. We show that metrics trained with SEAHORSE achieve strong performance on the out-of-domain meta-evaluation benchmarks TRUE (Honovich et al., 2022) and mFACE (Aharoni et al., 2022). We make SEAHORSE publicly available for future research on multilingual and multifaceted summarization evaluation.