 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$μ$PLAN: Summarizing using a Content Plan as Cross-Lingual Bridge
Paper and Code
May 23, 2023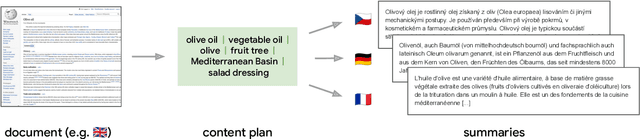
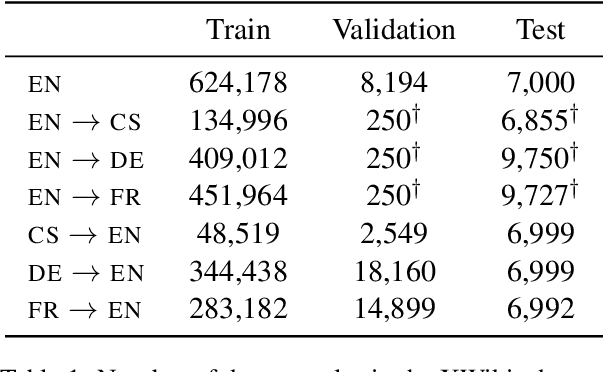


Cross-lingual summarization consists of generating a summary in one language given an input document in a different language, allowing for the dissemination of relevant content across speakers of other languages. However, this task remains challenging, mainly because of the need for cross-lingual datasets and the compounded difficulty of summarizing and translating. This work presents $\mu$PLAN, an approach to cross-lingual summarization that uses an intermediate planning step as a cross-lingual bridge. We formulate the plan as a sequence of entities that captures the conceptualization of the summary, i.e. identifying the salient content and expressing in which order to present the information, separate from the surface form. Using a multilingual knowledge base, we align the entities to their canonical designation across languages. $\mu$PLAN models first learn to generate the plan and then continue generating the summary conditioned on the plan and the input. We evaluate our methodology on the XWikis dataset on cross-lingual pairs across four languages and demonstrate that this planning objective achieves state-of-the-art performance in terms of ROUGE and faithfulness scores. Moreover, this planning approach improves the zero-shot transfer to new cross-lingual language pairs compared to non-planning baselines.