 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Plan and Generate Text with Citations
Apr 04, 2024The increasing demand for the deployment of LLMs in information-seeking scenarios has spurred efforts in creating verifiable systems, which generate responses to queries along with supporting evidence. In this paper, we explore the attribution capabilities of plan-based models which have been recently shown to improve the faithfulness, grounding, and controllability of generated text. We conceptualize plans as a sequence of questions which serve as blueprints of the generated content and its organization. We propose two attribution models that utilize different variants of blueprints, an abstractive model where questions are generated from scratch, and an extractive model where questions are copied from the input. Experiments on long-form question-answering show that planning consistently improves attribution quality. Moreover, the citations generated by blueprint models are more accurate compared to those obtained from LLM-based pipelines lacking a planning component.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Calibrating Likelihoods towards Consistency in Summarization Models
Oct 12, 2023Despite the recent advances in abstractive text summarization, current summarization models still suffer from generating factually inconsistent summaries, reducing their utility for real-world application. We argue that the main reason for such behavior is that the summarization models trained with maximum likelihood objective assign high probability to plausible sequences given the context, but they often do not accurately rank sequences by their consistency. In this work, we solve this problem by calibrating the likelihood of model generated sequences to better align with a consistency metric measured by natural language inference (NLI) models. The human evaluation study and automatic metrics show that the calibrated models generate more consistent and higher-quality summaries. We also show that the models trained using our method return probabilities that are better aligned with the NLI scores, which significantly increase reliability of summarization models.
$μ$PLAN: Summarizing using a Content Plan as Cross-Lingual Bridge
May 23, 2023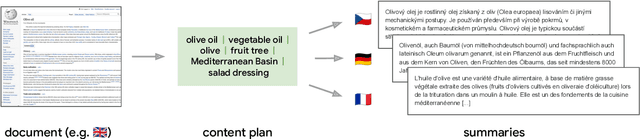
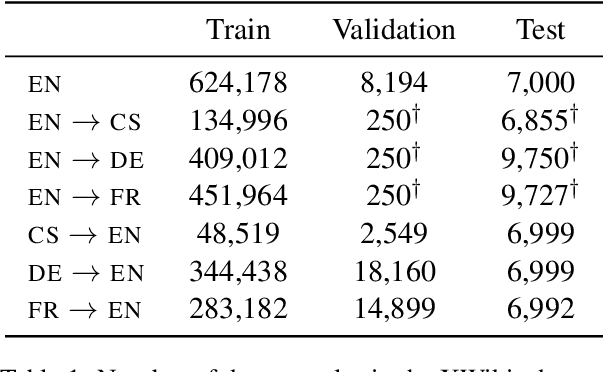


Cross-lingual summarization consists of generating a summary in one language given an input document in a different language, allowing for the dissemination of relevant content across speakers of other languages. However, this task remains challenging, mainly because of the need for cross-lingual datasets and the compounded difficulty of summarizing and translating. This work presents $\mu$PLAN, an approach to cross-lingual summarization that uses an intermediate planning step as a cross-lingual bridge. We formulate the plan as a sequence of entities that captures the conceptualization of the summary, i.e. identifying the salient content and expressing in which order to present the information, separate from the surface form. Using a multilingual knowledge base, we align the entities to their canonical designation across languages. $\mu$PLAN models first learn to generate the plan and then continue generating the summary conditioned on the plan and the input. We evaluate our methodology on the XWikis dataset on cross-lingual pairs across four languages and demonstrate that this planning objective achieves state-of-the-art performance in terms of ROUGE and faithfulness scores. Moreover, this planning approach improves the zero-shot transfer to new cross-lingual language pairs compared to non-planning baselines.
Text-Blueprint: An Interactive Platform for Plan-based Conditional Generation
Apr 28, 2023While conditional generation models can now generate natural language well enough to create fluent text, it is still difficult to control the generation process, leading to irrelevant, repetitive, and hallucinated content. Recent work shows that planning can be a useful intermediate step to render conditional generation less opaque and more grounded. We present a web browser-based demonstration for query-focused summarization that uses a sequence of question-answer pairs, as a blueprint plan for guiding text generation (i.e., what to say and in what order). We illustrate how users may interact with the generated text and associated plan visualizations, e.g., by editing and modifying the blueprint in order to improve or control the generated output. A short video demonstrating our system is available at https://goo.gle/text-blueprint-demo.
On Uncertainty Calibration and Selective Generation in Probabilistic Neural Summarization: A Benchmark Study
Apr 17, 2023



Modern deep models for summarization attains impressive benchmark performance, but they are prone to generating miscalibrated predictive uncertainty. This means that they assign high confidence to low-quality predictions, leading to compromised reliability and trustworthiness in real-world applications. Probabilistic deep learning methods are common solutions to the miscalibration problem. However, their relative effectiveness in complex autoregressive summarization tasks are not well-understood. In this work, we thoroughly investigate different state-of-the-art probabilistic methods' effectiveness in improving the uncertainty quality of the neural summarization models, across three large-scale benchmarks with varying difficulty. We show that the probabilistic methods consistently improve the model's generation and uncertainty quality, leading to improved selective generation performance (i.e., abstaining from low-quality summaries) in practice. We also reveal notable failure patterns of probabilistic methods widely-adopted in NLP community (e.g., Deep Ensemble and Monte Carlo Dropout), cautioning the importance of choosing appropriate method for the data setting.
mFACE: Multilingual Summarization with Factual Consistency Evaluation
Dec 20, 2022



Abstractive summarization has enjoyed renewed interest in recent years, thanks to pre-trained language models and the availability of large-scale datasets. Despite promising results, current models still suffer from generating factually inconsistent summaries, reducing their utility for real-world application. Several recent efforts attempt to address this by devising models that automatically detect factual inconsistencies in machine generated summaries. However, they focus exclusively on English, a language with abundant resources. In this work, we leverage factual consistency evaluation models to improve multilingual summarization. We explore two intuitive approaches to mitigate hallucinations based on the signal provided by a multilingual NLI model, namely data filtering and controlled generation. Experimental results in the 45 languages from the XLSum dataset show gains over strong baselines in both automatic and human evaluation.
Little Red Riding Hood Goes Around the Globe:Crosslingual Story Planning and Generation with Large Language Models
Dec 20, 2022



We consider the problem of automatically generating stories in multiple languages. Compared to prior work in monolingual story generation, crosslingual story generation allows for more universal research on story planning. We propose to use Prompting Large Language Models with Plans to study which plan is optimal for story generation. We consider 4 types of plans and systematically analyse how the outputs differ for different planning strategies. The study demonstrates that formulating the plans as question-answer pairs leads to more coherent generated stories while the plan gives more control to the story creators.
Query Refinement Prompts for Closed-Book Long-Form Question Answering
Oct 31, 2022Large language models (LLMs) have been shown to perform well in answering questions and in producing long-form texts, both in few-shot closed-book settings. While the former can be validated using well-known evaluation metrics, the latter is difficult to evaluate. We resolve the difficulties to evaluate long-form output by doing both tasks at once -- to do question answering that requires long-form answers. Such questions tend to be multifaceted, i.e., they may have ambiguities and/or require information from multiple sources. To this end, we define query refinement prompts that encourage LLMs to explicitly express the multifacetedness in questions and generate long-form answers covering multiple facets of the question. Our experiments on two long-form question answering datasets, ASQA and AQuAMuSe, show that using our prompts allows us to outperform fully finetuned models in the closed book setting, as well as achieve results comparable to retrieve-then-generate open-book models.
Calibrating Sequence likelihood Improves Conditional Language Generation
Sep 30, 2022
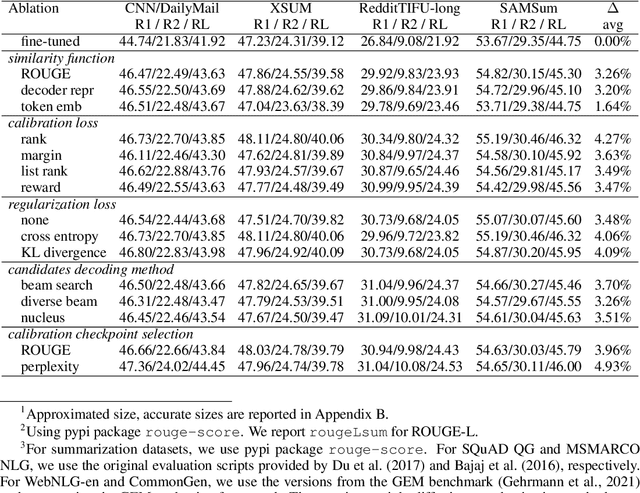


Conditional language models are predominantly trained with maximum likelihood estimation (MLE), giving probability mass to sparsely observed target sequences. While MLE trained models assign high probability to plausible sequences given the context, the model probabilities often do not accurately rank-order generated sequences by quality. This has been empirically observed in beam search decoding as output quality degrading with large beam sizes, and decoding strategies benefiting from heuristics such as length normalization and repetition-blocking. In this work, we introduce sequence likelihood calibration (SLiC) where the likelihood of model generated sequences are calibrated to better align with reference sequences in the model's latent space. With SLiC, decoding heuristics become unnecessary and decoding candidates' quality significantly improves regardless of the decoding method. Furthermore, SLiC shows no sign of diminishing returns with model scale, and presents alternative ways to improve quality with limited training and inference budgets. With SLiC, we exceed or match SOTA results on a wide range of generation tasks spanning abstractive summarization, question generation, abstractive question answering and data-to-text generation, even with modest-sized models.