 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSearchQA: Bridging the Comprehensiveness Gap for Deep Research Agents
Jan 28, 2026We introduce DeepSearchQA, a 900-prompt benchmark for evaluating agents on difficult multi-step information-seeking tasks across 17 different fields. Unlike traditional benchmarks that target single answer retrieval or broad-spectrum factuality, DeepSearchQA features a dataset of challenging, handcrafted tasks designed to evaluate an agent's ability to execute complex search plans to generate exhaustive answer lists. This shift in design explicitly tests three critical, yet under-evaluated capabilities: 1) systematic collation of fragmented information from disparate sources, 2) de-duplication and entity resolution to ensure precision, and 3) the ability to reason about stopping criteria within an open-ended search space. Each task is structured as a causal chain, where discovering information for one step is dependent on the successful completion of the previous one, stressing long-horizon planning and context retention. All tasks are grounded in the open web with objectively verifiable answer sets. Our comprehensive evaluation of state-of-the-art agent architectures reveals significant performance limitations: even the most advanced models struggle to balance high recall with precision. We observe distinct failure modes ranging from premature stopping (under-retrieval) to hedging behaviors, where agents cast an overly wide net of low-confidence answers to artificially boost recall. These findings highlight critical headroom in current agent designs and position DeepSearchQA as an essential diagnostic tool for driving future research toward more robust, deep-research capabilities.
The FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
SimpleQA Verified: A Reliable Factuality Benchmark to Measure Parametric Knowledge
Sep 09, 2025



We introduce SimpleQA Verified, a 1,000-prompt benchmark for evaluating Large Language Model (LLM) short-form factuality based on OpenAI's SimpleQA. It addresses critical limitations in OpenAI's benchmark, including noisy and incorrect labels, topical biases, and question redundancy. SimpleQA Verified was created through a rigorous multi-stage filtering process involving de-duplication, topic balancing, and source reconciliation to produce a more reliable and challenging evaluation set, alongside improvements in the autorater prompt. On this new benchmark, Gemini 2.5 Pro achieves a state-of-the-art F1-score of 55.6, outperforming other frontier models, including GPT-5. This work provides the research community with a higher-fidelity tool to track genuine progress in parametric model factuality and to mitigate hallucinations. The benchmark dataset, evaluation code, and leaderboard are available at: https://www.kaggle.com/benchmarks/deepmind/simpleqa-verified.
The FACTS Grounding Leaderboard: Benchmarking LLMs' Ability to Ground Responses to Long-Form Input
Jan 06, 2025



We introduce FACTS Grounding, an online leaderboard and associated benchmark that evaluates language models' ability to generate text that is factually accurate with respect to given context in the user prompt. In our benchmark, each prompt includes a user request and a full document, with a maximum length of 32k tokens, requiring long-form responses. The long-form responses are required to be fully grounded in the provided context document while fulfilling the user request. Models are evaluated using automated judge models in two phases: (1) responses are disqualified if they do not fulfill the user request; (2) they are judged as accurate if the response is fully grounded in the provided document. The automated judge models were comprehensively evaluated against a held-out test-set to pick the best prompt template, and the final factuality score is an aggregate of multiple judge models to mitigate evaluation bias. The FACTS Grounding leaderboard will be actively maintained over time, and contains both public and private splits to allow for external participation while guarding the integrity of the leaderboard. It can be found at https://www.kaggle.com/facts-leaderboard.
Task Planning for Object Rearrangement in Multi-room Environments
Jun 01, 2024



Object rearrangement in a multi-room setup should produce a reasonable plan that reduces the agent's overall travel and the number of steps. Recent state-of-the-art methods fail to produce such plans because they rely on explicit exploration for discovering unseen objects due to partial observability and a heuristic planner to sequence the actions for rearrangement. This paper proposes a novel hierarchical task planner to efficiently plan a sequence of actions to discover unseen objects and rearrange misplaced objects within an untidy house to achieve a desired tidy state. The proposed method introduces several novel techniques, including (i) a method for discovering unseen objects using commonsense knowledge from large language models, (ii) a collision resolution and buffer prediction method based on Cross-Entropy Method to handle blocked goal and swap cases, (iii) a directed spatial graph-based state space for scalability, and (iv) deep reinforcement learning (RL) for producing an efficient planner. The planner interleaves the discovery of unseen objects and rearrangement to minimize the number of steps taken and overall traversal of the agent. The paper also presents new metrics and a benchmark dataset called MoPOR to evaluate the effectiveness of the rearrangement planning in a multi-room setting. The experimental results demonstrate that the proposed method effectively addresses the multi-room rearrangement problem.
DOLOMITES: Domain-Specific Long-Form Methodical Tasks
May 09, 2024Experts in various fields routinely perform methodical writing tasks to plan, organize, and report their work. From a clinician writing a differential diagnosis for a patient, to a teacher writing a lesson plan for students, these tasks are pervasive, requiring to methodically generate structured long-form output for a given input. We develop a typology of methodical tasks structured in the form of a task objective, procedure, input, and output, and introduce DoLoMiTes, a novel benchmark with specifications for 519 such tasks elicited from hundreds of experts from across 25 fields. Our benchmark further contains specific instantiations of methodical tasks with concrete input and output examples (1,857 in total) which we obtain by collecting expert revisions of up to 10 model-generated examples of each task. We use these examples to evaluate contemporary language models highlighting that automating methodical tasks is a challenging long-form generation problem, as it requires performing complex inferences, while drawing upon the given context as well as domain knowledge.
Anticipate & Collab: Data-driven Task Anticipation and Knowledge-driven Planning for Human-robot Collaboration
Apr 04, 2024



An agent assisting humans in daily living activities can collaborate more effectively by anticipating upcoming tasks. Data-driven methods represent the state of the art in task anticipation, planning, and related problems, but these methods are resource-hungry and opaque. Our prior work introduced a proof of concept framework that used an LLM to anticipate 3 high-level tasks that served as goals for a classical planning system that computed a sequence of low-level actions for the agent to achieve these goals. This paper describes DaTAPlan, our framework that significantly extends our prior work toward human-robot collaboration. Specifically, DaTAPlan planner computes actions for an agent and a human to collaboratively and jointly achieve the tasks anticipated by the LLM, and the agent automatically adapts to unexpected changes in human action outcomes and preferences. We evaluate DaTAPlan capabilities in a realistic simulation environment, demonstrating accurate task anticipation, effective human-robot collaboration, and the ability to adapt to unexpected changes. Project website: https://dataplan-hrc.github.io
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
SEAHORSE: A Multilingual, Multifaceted Dataset for Summarization Evaluation
May 22, 2023
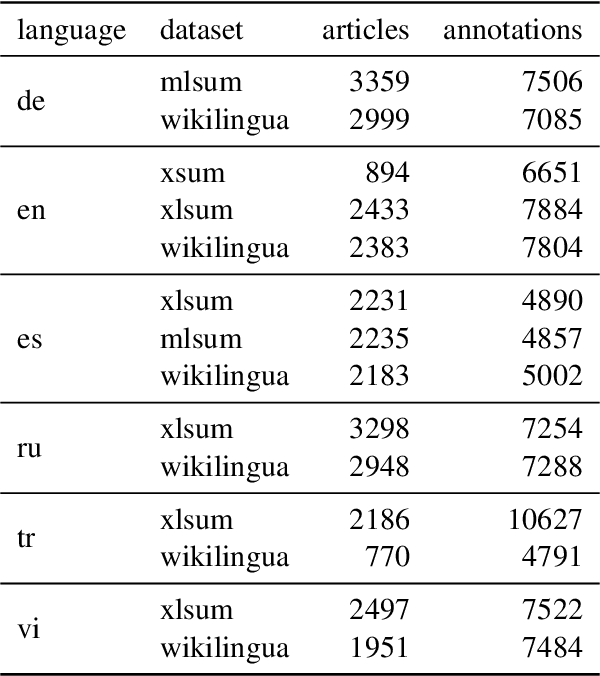
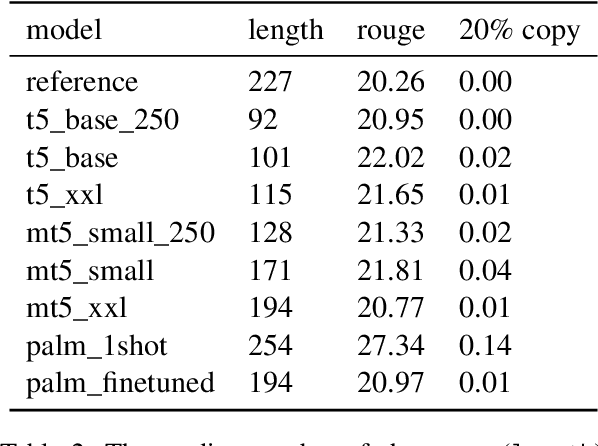
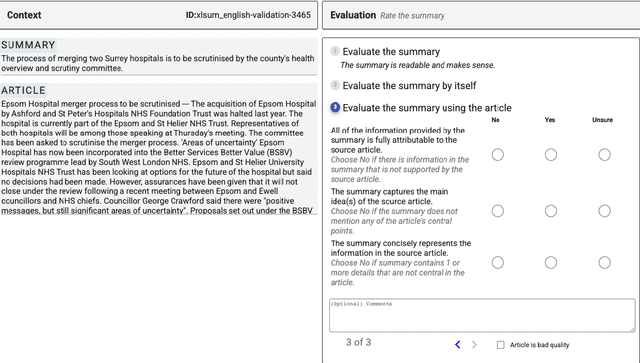
Reliable automatic evaluation of summarization systems is challenging due to the multifaceted and subjective nature of the task. This is especially the case for languages other than English, where human evaluations are scarce. In this work, we introduce SEAHORSE, a dataset for multilingual, multifaceted summarization evaluation. SEAHORSE consists of 96K summaries with human ratings along 6 quality dimensions: comprehensibility, repetition, grammar, attribution, main ideas, and conciseness, covering 6 languages, 9 systems and 4 datasets. As a result of its size and scope, SEAHORSE can serve both as a benchmark to evaluate learnt metrics, as well as a large-scale resource for training such metrics. We show that metrics trained with SEAHORSE achieve strong performance on the out-of-domain meta-evaluation benchmarks TRUE (Honovich et al., 2022) and mFACE (Aharoni et al., 2022). We make SEAHORSE publicly available for future research on multilingual and multifaceted summarization evaluation.
Text-Blueprint: An Interactive Platform for Plan-based Conditional Generation
Apr 28, 2023While conditional generation models can now generate natural language well enough to create fluent text, it is still difficult to control the generation process, leading to irrelevant, repetitive, and hallucinated content. Recent work shows that planning can be a useful intermediate step to render conditional generation less opaque and more grounded. We present a web browser-based demonstration for query-focused summarization that uses a sequence of question-answer pairs, as a blueprint plan for guiding text generation (i.e., what to say and in what order). We illustrate how users may interact with the generated text and associated plan visualizations, e.g., by editing and modifying the blueprint in order to improve or control the generated output. A short video demonstrating our system is available at https://goo.gle/text-blueprint-demo.