 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSearchQA: Bridging the Comprehensiveness Gap for Deep Research Agents
Jan 28, 2026We introduce DeepSearchQA, a 900-prompt benchmark for evaluating agents on difficult multi-step information-seeking tasks across 17 different fields. Unlike traditional benchmarks that target single answer retrieval or broad-spectrum factuality, DeepSearchQA features a dataset of challenging, handcrafted tasks designed to evaluate an agent's ability to execute complex search plans to generate exhaustive answer lists. This shift in design explicitly tests three critical, yet under-evaluated capabilities: 1) systematic collation of fragmented information from disparate sources, 2) de-duplication and entity resolution to ensure precision, and 3) the ability to reason about stopping criteria within an open-ended search space. Each task is structured as a causal chain, where discovering information for one step is dependent on the successful completion of the previous one, stressing long-horizon planning and context retention. All tasks are grounded in the open web with objectively verifiable answer sets. Our comprehensive evaluation of state-of-the-art agent architectures reveals significant performance limitations: even the most advanced models struggle to balance high recall with precision. We observe distinct failure modes ranging from premature stopping (under-retrieval) to hedging behaviors, where agents cast an overly wide net of low-confidence answers to artificially boost recall. These findings highlight critical headroom in current agent designs and position DeepSearchQA as an essential diagnostic tool for driving future research toward more robust, deep-research capabilities.
Integrated Triaging for Fast Reading Comprehension
Sep 28, 2019
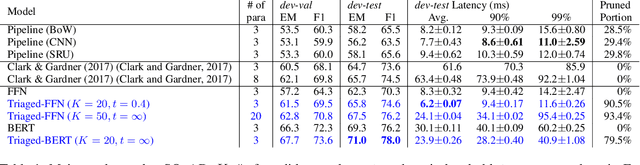
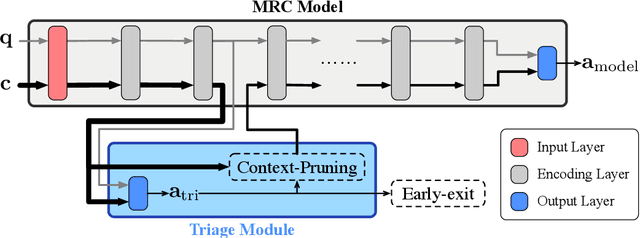
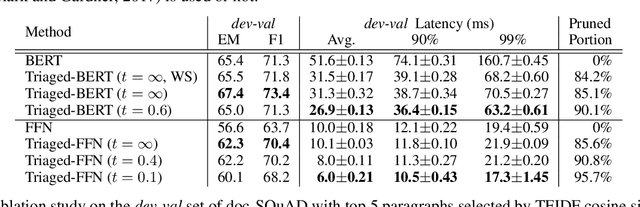
Although according to several benchmarks automatic machine reading comprehension (MRC) systems have recently reached super-human performance, less attention has been paid to their computational efficiency. However, efficiency is of crucial importance for training and deployment in real world applications. This paper introduces Integrated Triaging, a framework that prunes almost all context in early layers of a network, leaving the remaining (deep) layers to scan only a tiny fraction of the full corpus. This pruning drastically increases the efficiency of MRC models and further prevents the later layers from overfitting to prevalent short paragraphs in the training set. Our framework is extremely flexible and naturally applicable to a wide variety of models. Our experiment on doc-SQuAD and TriviaQA tasks demonstrates its effectiveness in consistently improving both speed and quality of several diverse MRC models.
FastFusionNet: New State-of-the-Art for DAWNBench SQuAD
Mar 02, 2019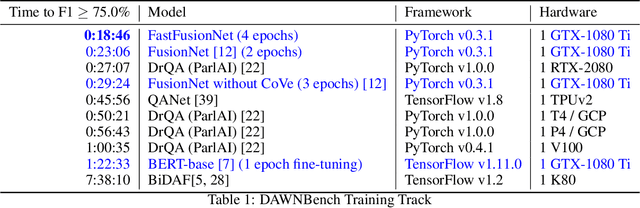
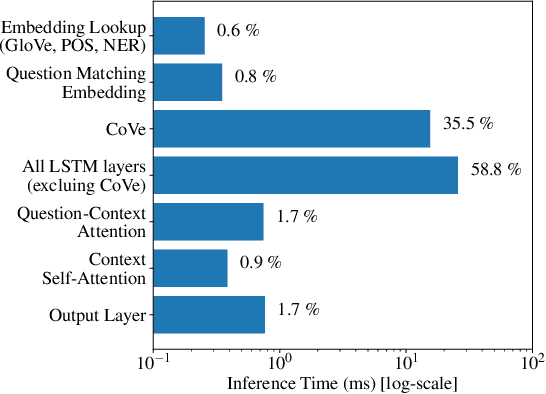
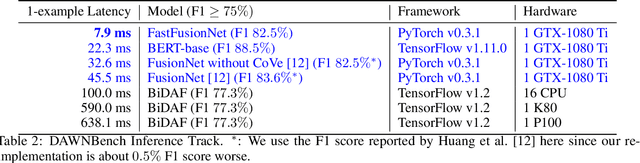
In this technical report, we introduce FastFusionNet, an efficient variant of FusionNet [12]. FusionNet is a high performing reading comprehension architecture, which was designed primarily for maximum retrieval accuracy with less regard towards computational requirements. For FastFusionNets we remove the expensive CoVe layers [21] and substitute the BiLSTMs with far more efficient SRU layers [19]. The resulting architecture obtains state-of-the-art results on DAWNBench [5] while achieving the lowest training and inference time on SQuAD [25] to-date. The code is available at https://github.com/felixgwu/FastFusionNet.
Fast Reading Comprehension with ConvNets
Nov 12, 2017
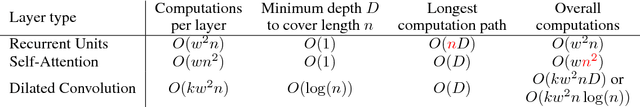

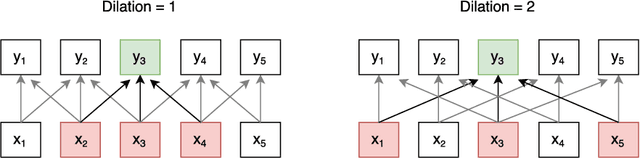
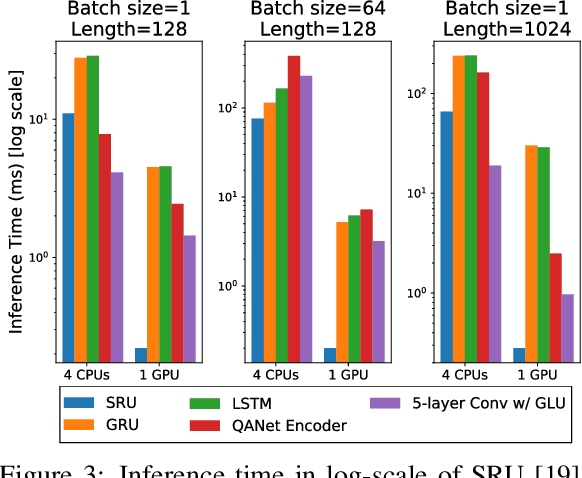
State-of-the-art deep reading comprehension models are dominated by recurrent neural nets. Their sequential nature is a natural fit for language, but it also precludes parallelization within an instances and often becomes the bottleneck for deploying such models to latency critical scenarios. This is particularly problematic for longer texts. Here we present a convolutional architecture as an alternative to these recurrent architectures. Using simple dilated convolutional units in place of recurrent ones, we achieve results comparable to the state of the art on two question answering tasks, while at the same time achieving up to two orders of magnitude speedups for question answering.
Evaluating Induced CCG Parsers on Grounded Semantic Parsing
Jan 31, 2017
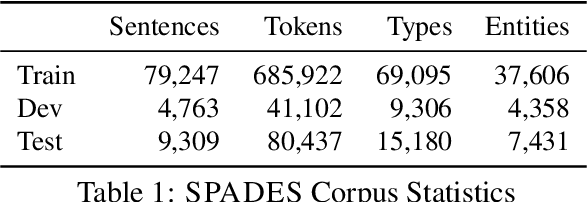
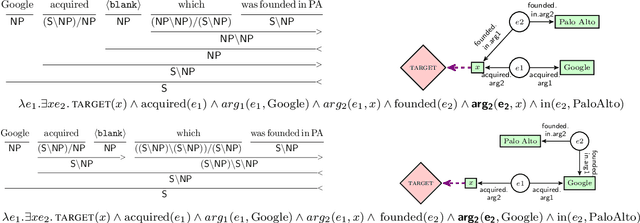
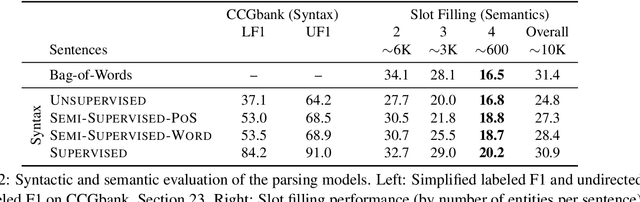
We compare the effectiveness of four different syntactic CCG parsers for a semantic slot-filling task to explore how much syntactic supervision is required for downstream semantic analysis. This extrinsic, task-based evaluation provides a unique window to explore the strengths and weaknesses of semantics captured by unsupervised grammar induction systems. We release a new Freebase semantic parsing dataset called SPADES (Semantic PArsing of DEclarative Sentences) containing 93K cloze-style questions paired with answers. We evaluate all our models on this dataset. Our code and data are available at https://github.com/sivareddyg/graph-parser.
Latent Structured Ranking
Oct 16, 2012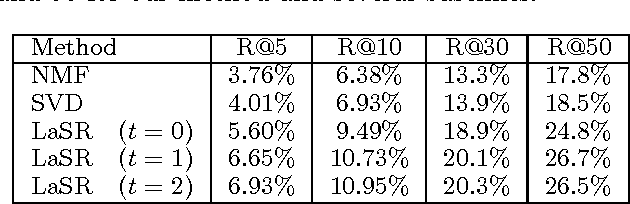
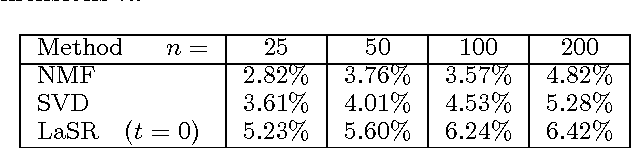
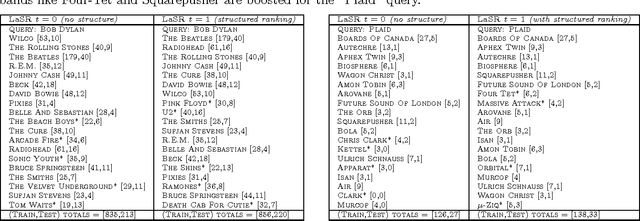

Many latent (factorized) models have been proposed for recommendation tasks like collaborative filtering and for ranking tasks like document or image retrieval and annotation. Common to all those methods is that during inference the items are scored independently by their similarity to the query in the latent embedding space. The structure of the ranked list (i.e. considering the set of items returned as a whole) is not taken into account. This can be a problem because the set of top predictions can be either too diverse (contain results that contradict each other) or are not diverse enough. In this paper we introduce a method for learning latent structured rankings that improves over existing methods by providing the right blend of predictions at the top of the ranked list. Particular emphasis is put on making this method scalable. Empirical results on large scale image annotation and music recommendation tasks show improvements over existing approaches.
Multi-View Learning over Structured and Non-Identical Outputs
Jun 13, 2012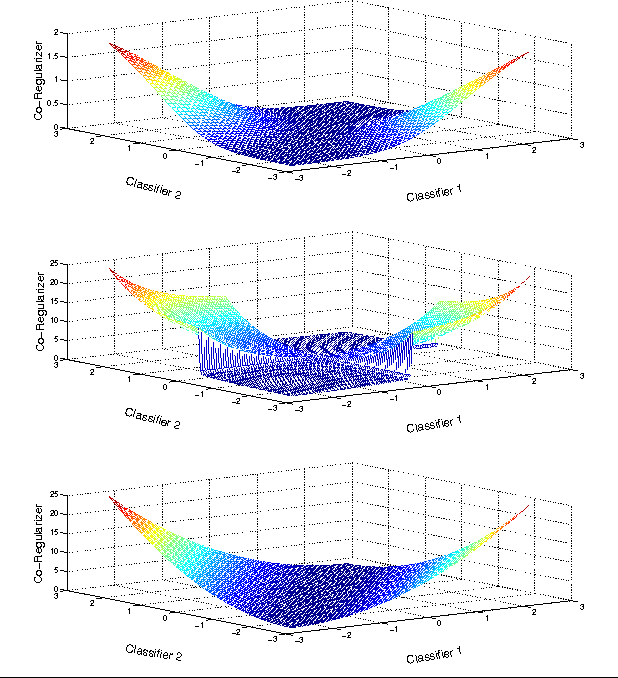
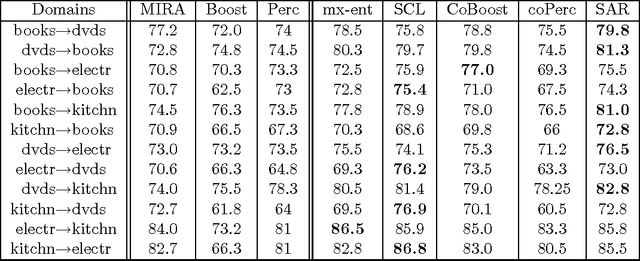
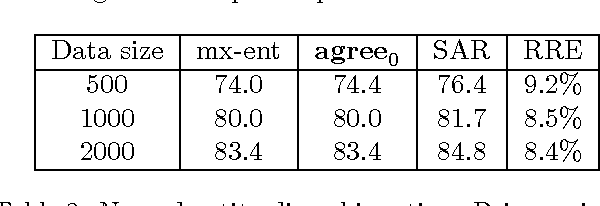
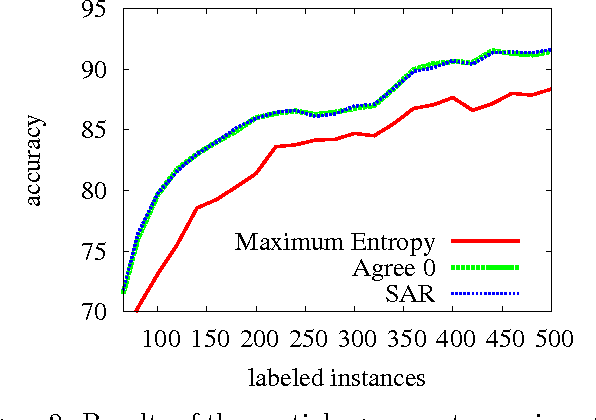
In many machine learning problems, labeled training data is limited but unlabeled data is ample. Some of these problems have instances that can be factored into multiple views, each of which is nearly sufficent in determining the correct labels. In this paper we present a new algorithm for probabilistic multi-view learning which uses the idea of stochastic agreement between views as regularization. Our algorithm works on structured and unstructured problems and easily generalizes to partial agreement scenarios. For the full agreement case, our algorithm minimizes the Bhattacharyya distance between the models of each view, and performs better than CoBoosting and two-view Perceptron on several flat and structured classification problems.