 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Structured Ranking
Paper and Code
Oct 16, 2012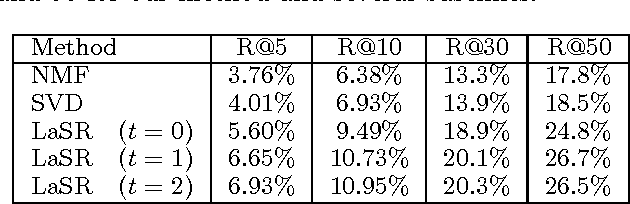
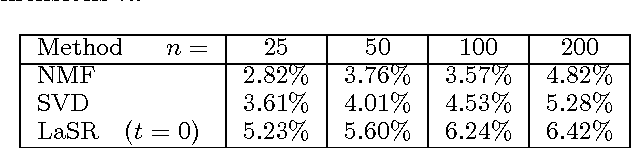
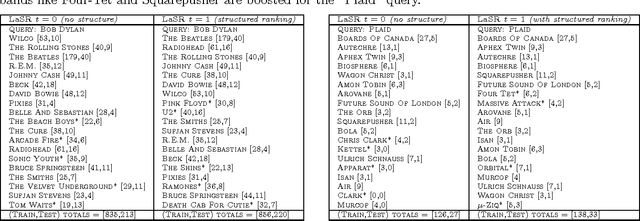

Many latent (factorized) models have been proposed for recommendation tasks like collaborative filtering and for ranking tasks like document or image retrieval and annotation. Common to all those methods is that during inference the items are scored independently by their similarity to the query in the latent embedding space. The structure of the ranked list (i.e. considering the set of items returned as a whole) is not taken into account. This can be a problem because the set of top predictions can be either too diverse (contain results that contradict each other) or are not diverse enough. In this paper we introduce a method for learning latent structured rankings that improves over existing methods by providing the right blend of predictions at the top of the ranked list. Particular emphasis is put on making this method scalable. Empirical results on large scale image annotation and music recommendation tasks show improvements over existing approaches.