 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Blind Spot of Agent Safety: How Benign User Instructions Expose Critical Vulnerabilities in Computer-Use Agents
Apr 12, 2026Computer-use agents (CUAs) can now autonomously complete complex tasks in real digital environments, but when misled, they can also be used to automate harmful actions programmatically. Existing safety evaluations largely target explicit threats such as misuse and prompt injection, but overlook a subtle yet critical setting where user instructions are entirely benign and harm arises from the task context or execution outcome. We introduce OS-BLIND, a benchmark that evaluates CUAs under unintended attack conditions, comprising 300 human-crafted tasks across 12 categories, 8 applications, and 2 threat clusters: environment-embedded threats and agent-initiated harms. Our evaluation on frontier models and agentic frameworks reveals that most CUAs exceed 90% attack success rate (ASR), and even the safety-aligned Claude 4.5 Sonnet reaches 73.0% ASR. More interestingly, this vulnerability becomes even more severe, with ASR rising from 73.0% to 92.7% when Claude 4.5 Sonnet is deployed in multi-agent systems. Our analysis further shows that existing safety defenses provide limited protection when user instructions are benign. Safety alignment primarily activates within the first few steps and rarely re-engages during subsequent execution. In multi-agent systems, decomposed subtasks obscure the harmful intent from the model, causing safety-aligned models to fail. We will release our OS-BLIND to encourage the broader research community to further investigate and address these safety challenges.
Structured Distillation of Web Agent Capabilities Enables Generalization
Apr 09, 2026Frontier LLMs can navigate complex websites, but their cost and reliance on third-party APIs make local deployment impractical. We introduce Agent-as-Annotators, a framework that structures synthetic trajectory generation for web agents by analogy to human annotation roles, replacing the Task Designer, Annotator, and Supervisor with modular LLM components. Using Gemini 3 Pro as teacher, we generate 3,000 trajectories across six web environments and fine-tune a 9B-parameter student with pure supervised learning on the 2,322 that pass quality filtering. The resulting model achieves 41.5% on WebArena, surpassing closed-source models such as Claude 3.5 Sonnet (36.0%) and GPT-4o (31.5%) under the same evaluation protocol, and nearly doubling the previous best open-weight result (Go-Browse, 21.7%). Capabilities transfer to unseen environments, with an 18.2 percentage point gain on WorkArena L1 (an enterprise platform never seen during training) and consistent improvements across three additional benchmarks. Ablations confirm that each pipeline component contributes meaningfully, with Judge filtering, evaluation hints, and reasoning traces each accounting for measurable gains. These results demonstrate that structured trajectory synthesis from a single frontier teacher is sufficient to produce competitive, locally deployable web agents. Project page: https://agent-as-annotators.github.io
CUBE: A Standard for Unifying Agent Benchmarks
Mar 16, 2026The proliferation of agent benchmarks has created critical fragmentation that threatens research productivity. Each new benchmark requires substantial custom integration, creating an "integration tax" that limits comprehensive evaluation. We propose CUBE (Common Unified Benchmark Environments), a universal protocol standard built on MCP and Gym that allows benchmarks to be wrapped once and used everywhere. By separating task, benchmark, package, and registry concerns into distinct API layers, CUBE enables any compliant platform to access any compliant benchmark for evaluation, RL training, or data generation without custom integration. We call on the community to contribute to the development of this standard before platform-specific implementations deepen fragmentation as benchmark production accelerates through 2026.
LLM2Vec-Gen: Generative Embeddings from Large Language Models
Mar 11, 2026LLM-based text embedders typically encode the semantic content of their input. However, embedding tasks require mapping diverse inputs to similar outputs. Typically, this input-output is addressed by training embedding models with paired data using contrastive learning. In this work, we propose a novel self-supervised approach, LLM2Vec-Gen, which adopts a different paradigm: rather than encoding the input, we learn to represent the model's potential response. Specifically, we add trainable special tokens to the LLM's vocabulary, append them to input, and optimize them to represent the LLM's response in a fixed-length sequence. Training is guided by the LLM's own completion for the query, along with an unsupervised embedding teacher that provides distillation targets. This formulation helps to bridge the input-output gap and transfers LLM capabilities such as safety alignment and reasoning to embedding tasks. Crucially, the LLM backbone remains frozen and training requires only unlabeled queries. LLM2Vec-Gen achieves state-of-the-art self-supervised performance on the Massive Text Embedding Benchmark (MTEB), improving by 9.3% over the best unsupervised embedding teacher. We also observe up to 43.2% reduction in harmful content retrieval and 29.3% improvement in reasoning capabilities for embedding tasks. Finally, the learned embeddings are interpretable and can be decoded into text to reveal their semantic content.
Operationalising the Superficial Alignment Hypothesis via Task Complexity
Feb 17, 2026The superficial alignment hypothesis (SAH) posits that large language models learn most of their knowledge during pre-training, and that post-training merely surfaces this knowledge. The SAH, however, lacks a precise definition, which has led to (i) different and seemingly orthogonal arguments supporting it, and (ii) important critiques to it. We propose a new metric called task complexity: the length of the shortest program that achieves a target performance on a task. In this framework, the SAH simply claims that pre-trained models drastically reduce the complexity of achieving high performance on many tasks. Our definition unifies prior arguments supporting the SAH, interpreting them as different strategies to find such short programs. Experimentally, we estimate the task complexity of mathematical reasoning, machine translation, and instruction following; we then show that these complexities can be remarkably low when conditioned on a pre-trained model. Further, we find that pre-training enables access to strong performances on our tasks, but it can require programs of gigabytes of length to access them. Post-training, on the other hand, collapses the complexity of reaching this same performance by several orders of magnitude. Overall, our results highlight that task adaptation often requires surprisingly little information -- often just a few kilobytes.
BRIDGE: Predicting Human Task Completion Time From Model Performance
Feb 06, 2026Evaluating the real-world capabilities of AI systems requires grounding benchmark performance in human-interpretable measures of task difficulty. Existing approaches that rely on direct human task completion time annotations are costly, noisy, and difficult to scale across benchmarks. In this work, we propose BRIDGE, a unified psychometric framework that learns the latent difficulty scale from model responses and anchors it to human task completion time. Using a two-parameter logistic Item Response Theory model, we jointly estimate latent task difficulty and model capability from model performance data across multiple benchmarks. We demonstrate that latent task difficulty varies linearly with the logarithm of human completion time, allowing human task completion time to be inferred for new benchmarks from model performance alone. Leveraging this alignment, we forecast frontier model capabilities in terms of human task length and independently reproduce METR's exponential scaling results, with the 50% solvable task horizon doubling approximately every 6 months.
LatentLens: Revealing Highly Interpretable Visual Tokens in LLMs
Jan 31, 2026Transforming a large language model (LLM) into a Vision-Language Model (VLM) can be achieved by mapping the visual tokens from a vision encoder into the embedding space of an LLM. Intriguingly, this mapping can be as simple as a shallow MLP transformation. To understand why LLMs can so readily process visual tokens, we need interpretability methods that reveal what is encoded in the visual token representations at every layer of LLM processing. In this work, we introduce LatentLens, a novel approach for mapping latent representations to descriptions in natural language. LatentLens works by encoding a large text corpus and storing contextualized token representations for each token in that corpus. Visual token representations are then compared to their contextualized textual representations, with the top-k nearest neighbor representations providing descriptions of the visual token. We evaluate this method on 10 different VLMs, showing that commonly used methods, such as LogitLens, substantially underestimate the interpretability of visual tokens. With LatentLens instead, the majority of visual tokens are interpretable across all studied models and all layers. Qualitatively, we show that the descriptions produced by LatentLens are semantically meaningful and provide more fine-grained interpretations for humans compared to individual tokens. More broadly, our findings contribute new evidence on the alignment between vision and language representations, opening up new directions for analyzing latent representations.
Value Drifts: Tracing Value Alignment During LLM Post-Training
Oct 30, 2025As LLMs occupy an increasingly important role in society, they are more and more confronted with questions that require them not only to draw on their general knowledge but also to align with certain human value systems. Therefore, studying the alignment of LLMs with human values has become a crucial field of inquiry. Prior work, however, mostly focuses on evaluating the alignment of fully trained models, overlooking the training dynamics by which models learn to express human values. In this work, we investigate how and at which stage value alignment arises during the course of a model's post-training. Our analysis disentangles the effects of post-training algorithms and datasets, measuring both the magnitude and time of value drifts during training. Experimenting with Llama-3 and Qwen-3 models of different sizes and popular supervised fine-tuning (SFT) and preference optimization datasets and algorithms, we find that the SFT phase generally establishes a model's values, and subsequent preference optimization rarely re-aligns these values. Furthermore, using a synthetic preference dataset that enables controlled manipulation of values, we find that different preference optimization algorithms lead to different value alignment outcomes, even when preference data is held constant. Our findings provide actionable insights into how values are learned during post-training and help to inform data curation, as well as the selection of models and algorithms for preference optimization to improve model alignment to human values.
Build the web for agents, not agents for the web
Jun 12, 2025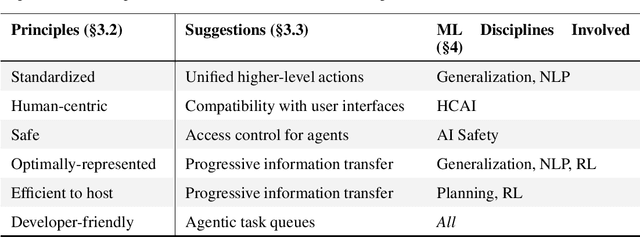
Recent advancements in Large Language Models (LLMs) and multimodal counterparts have spurred significant interest in developing web agents -- AI systems capable of autonomously navigating and completing tasks within web environments. While holding tremendous promise for automating complex web interactions, current approaches face substantial challenges due to the fundamental mismatch between human-designed interfaces and LLM capabilities. Current methods struggle with the inherent complexity of web inputs, whether processing massive DOM trees, relying on screenshots augmented with additional information, or bypassing the user interface entirely through API interactions. This position paper advocates for a paradigm shift in web agent research: rather than forcing web agents to adapt to interfaces designed for humans, we should develop a new interaction paradigm specifically optimized for agentic capabilities. To this end, we introduce the concept of an Agentic Web Interface (AWI), an interface specifically designed for agents to navigate a website. We establish six guiding principles for AWI design, emphasizing safety, efficiency, and standardization, to account for the interests of all primary stakeholders. This reframing aims to overcome fundamental limitations of existing interfaces, paving the way for more efficient, reliable, and transparent web agent design, which will be a collaborative effort involving the broader ML community.
REARANK: Reasoning Re-ranking Agent via Reinforcement Learning
May 26, 2025We present REARANK, a large language model (LLM)-based listwise reasoning reranking agent. REARANK explicitly reasons before reranking, significantly improving both performance and interpretability. Leveraging reinforcement learning and data augmentation, REARANK achieves substantial improvements over baseline models across popular information retrieval benchmarks, notably requiring only 179 annotated samples. Built on top of Qwen2.5-7B, our REARANK-7B demonstrates performance comparable to GPT-4 on both in-domain and out-of-domain benchmarks and even surpasses GPT-4 on reasoning-intensive BRIGHT benchmarks. These results underscore the effectiveness of our approach and highlight how reinforcement learning can enhance LLM reasoning capabilities in reranking.