 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSA-COMET: Do LLMs Outperform Learned Metrics in Evaluating MT for Under-Resourced African Languages?
Jun 05, 2025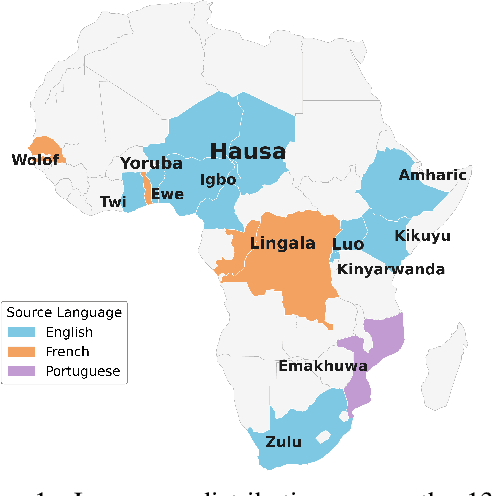
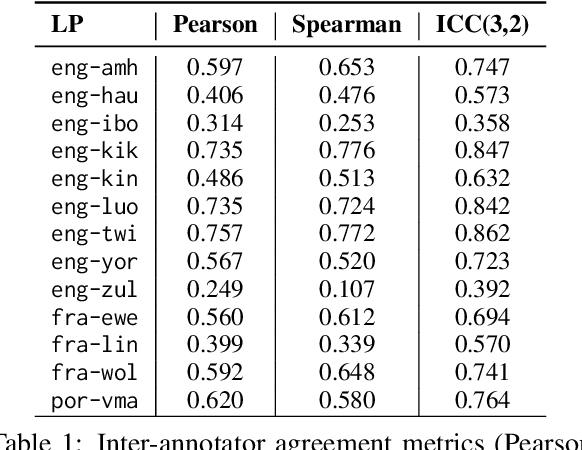
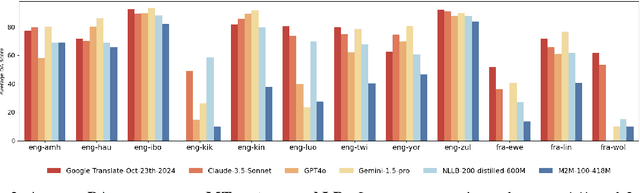
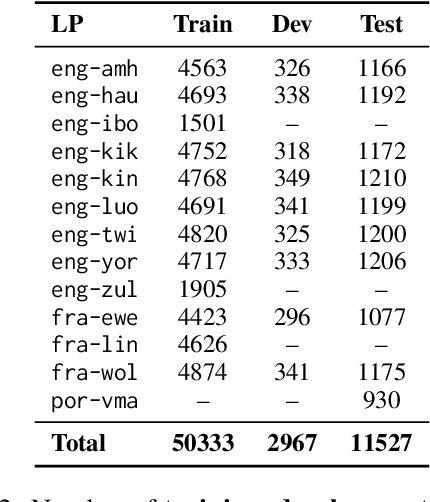
Evaluating machine translation (MT) quality for under-resourced African languages remains a significant challenge, as existing metrics often suffer from limited language coverage and poor performance in low-resource settings. While recent efforts, such as AfriCOMET, have addressed some of the issues, they are still constrained by small evaluation sets, a lack of publicly available training data tailored to African languages, and inconsistent performance in extremely low-resource scenarios. In this work, we introduce SSA-MTE, a large-scale human-annotated MT evaluation (MTE) dataset covering 13 African language pairs from the News domain, with over 63,000 sentence-level annotations from a diverse set of MT systems. Based on this data, we develop SSA-COMET and SSA-COMET-QE, improved reference-based and reference-free evaluation metrics. We also benchmark prompting-based approaches using state-of-the-art LLMs like GPT-4o and Claude. Our experimental results show that SSA-COMET models significantly outperform AfriCOMET and are competitive with the strongest LLM (Gemini 2.5 Pro) evaluated in our study, particularly on low-resource languages such as Twi, Luo, and Yoruba. All resources are released under open licenses to support future research.
Warmup Generations: A Task-Agnostic Approach for Guiding Sequence-to-Sequence Learning with Unsupervised Initial State Generation
Feb 17, 2025



Traditional supervised fine-tuning (SFT) strategies for sequence-to-sequence tasks often train models to directly generate the target output. Recent work has shown that guiding models with intermediate steps, such as keywords, outlines, or reasoning chains, can significantly improve performance, coherence, and interpretability. However, these methods often depend on predefined intermediate formats and annotated data, limiting their scalability and generalizability. In this work, we introduce a task-agnostic framework that enables models to generate intermediate "warmup" sequences. These warmup sequences, serving as an initial state for subsequent generation, are optimized to enhance the probability of generating the target sequence without relying on external supervision or human-designed structures. Drawing inspiration from reinforcement learning principles, our method iteratively refines these intermediate steps to maximize their contribution to the final output, similar to reward-driven optimization in reinforcement learning with human feedback. Experimental results across tasks such as translation, summarization, and multi-choice question answering for logical reasoning show that our approach outperforms traditional SFT methods, and offers a scalable and flexible solution for sequence-to-sequence tasks.
Cross-Modal Consistency in Multimodal Large Language Models
Nov 14, 2024Recent developments in multimodal methodologies have marked the beginning of an exciting era for models adept at processing diverse data types, encompassing text, audio, and visual content. Models like GPT-4V, which merge computer vision with advanced language processing, exhibit extraordinary proficiency in handling intricate tasks that require a simultaneous understanding of both textual and visual information. Prior research efforts have meticulously evaluated the efficacy of these Vision Large Language Models (VLLMs) in various domains, including object detection, image captioning, and other related fields. However, existing analyses have often suffered from limitations, primarily centering on the isolated evaluation of each modality's performance while neglecting to explore their intricate cross-modal interactions. Specifically, the question of whether these models achieve the same level of accuracy when confronted with identical task instances across different modalities remains unanswered. In this study, we take the initiative to delve into the interaction and comparison among these modalities of interest by introducing a novel concept termed cross-modal consistency. Furthermore, we propose a quantitative evaluation framework founded on this concept. Our experimental findings, drawn from a curated collection of parallel vision-language datasets developed by us, unveil a pronounced inconsistency between the vision and language modalities within GPT-4V, despite its portrayal as a unified multimodal model. Our research yields insights into the appropriate utilization of such models and hints at potential avenues for enhancing their design.
Lost in Translation: When GPT-4V Can't See Eye to Eye with Text. A Vision-Language-Consistency Analysis of VLLMs and Beyond
Oct 19, 2023Recent advancements in multimodal techniques open exciting possibilities for models excelling in diverse tasks involving text, audio, and image processing. Models like GPT-4V, blending computer vision and language modeling, excel in complex text and image tasks. Numerous prior research endeavors have diligently examined the performance of these Vision Large Language Models (VLLMs) across tasks like object detection, image captioning and others. However, these analyses often focus on evaluating the performance of each modality in isolation, lacking insights into their cross-modal interactions. Specifically, questions concerning whether these vision-language models execute vision and language tasks consistently or independently have remained unanswered. In this study, we draw inspiration from recent investigations into multilingualism and conduct a comprehensive analysis of model's cross-modal interactions. We introduce a systematic framework that quantifies the capability disparities between different modalities in the multi-modal setting and provide a set of datasets designed for these evaluations. Our findings reveal that models like GPT-4V tend to perform consistently modalities when the tasks are relatively simple. However, the trustworthiness of results derived from the vision modality diminishes as the tasks become more challenging. Expanding on our findings, we introduce "Vision Description Prompting," a method that effectively improves performance in challenging vision-related tasks.
Don't Trust GPT When Your Question Is Not In English
May 24, 2023Large Language Models (LLMs) have demonstrated exceptional natural language understanding abilities and have excelled in a variety of natural language processing (NLP)tasks in recent years. Despite the fact that most LLMs are trained predominantly in English, multiple studies have demonstrated their comparative performance in many other languages. However, fundamental questions persist regarding how LLMs acquire their multi-lingual abilities and how performance varies across different languages. These inquiries are crucial for the study of LLMs since users and researchers often come from diverse language backgrounds, potentially influencing their utilization and interpretation of LLMs' results. In this work, we propose a systematic way of qualifying the performance disparities of LLMs under multilingual settings. We investigate the phenomenon of across-language generalizations in LLMs, wherein insufficient multi-lingual training data leads to advanced multi-lingual capabilities. To accomplish this, we employ a novel back-translation-based prompting method. The results show that GPT exhibits highly translating-like behaviour in multilingual settings.