 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Model to Classroom: Evaluating Generated MCQs for Portuguese with Narrative and Difficulty Concerns
Jun 18, 2025While MCQs are valuable for learning and evaluation, manually creating them with varying difficulty levels and targeted reading skills remains a time-consuming and costly task. Recent advances in generative AI provide an opportunity to automate MCQ generation efficiently. However, assessing the actual quality and reliability of generated MCQs has received limited attention -- particularly regarding cases where generation fails. This aspect becomes particularly important when the generated MCQs are meant to be applied in real-world settings. Additionally, most MCQ generation studies focus on English, leaving other languages underexplored. This paper investigates the capabilities of current generative models in producing MCQs for reading comprehension in Portuguese, a morphologically rich language. Our study focuses on generating MCQs that align with curriculum-relevant narrative elements and span different difficulty levels. We evaluate these MCQs through expert review and by analyzing the psychometric properties extracted from student responses to assess their suitability for elementary school students. Our results show that current models can generate MCQs of comparable quality to human-authored ones. However, we identify issues related to semantic clarity and answerability. Also, challenges remain in generating distractors that engage students and meet established criteria for high-quality MCQ option design.
Advancing Question Generation with Joint Narrative and Difficulty Control
Jun 07, 2025Question Generation (QG), the task of automatically generating questions from a source input, has seen significant progress in recent years. Difficulty-controllable QG (DCQG) enables control over the difficulty level of generated questions while considering the learner's ability. Additionally, narrative-controllable QG (NCQG) allows control over the narrative aspects embedded in the questions. However, research in QG lacks a focus on combining these two types of control, which is important for generating questions tailored to educational purposes. To address this gap, we propose a strategy for Joint Narrative and Difficulty Control, enabling simultaneous control over these two attributes in the generation of reading comprehension questions. Our evaluation provides preliminary evidence that this approach is feasible, though it is not effective across all instances. Our findings highlight the conditions under which the strategy performs well and discuss the trade-offs associated with its application.
SSA-COMET: Do LLMs Outperform Learned Metrics in Evaluating MT for Under-Resourced African Languages?
Jun 05, 2025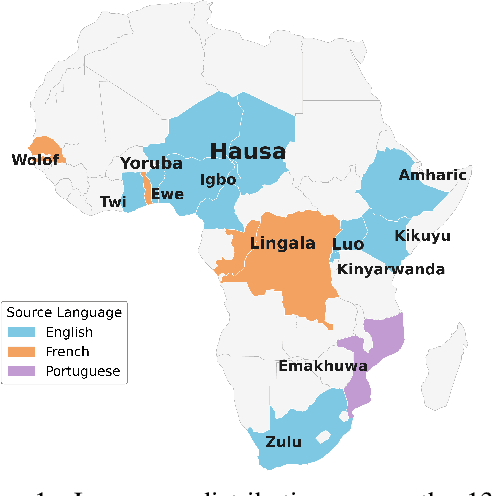
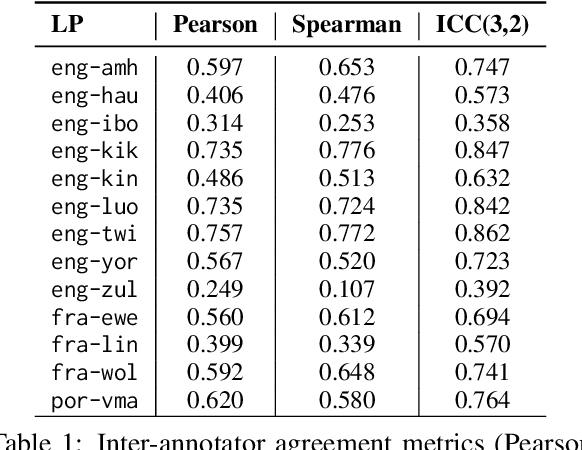
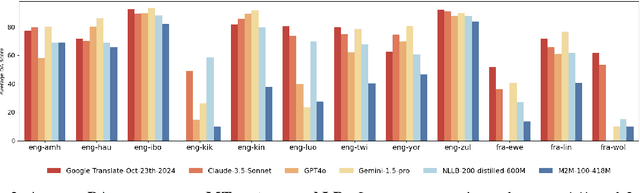
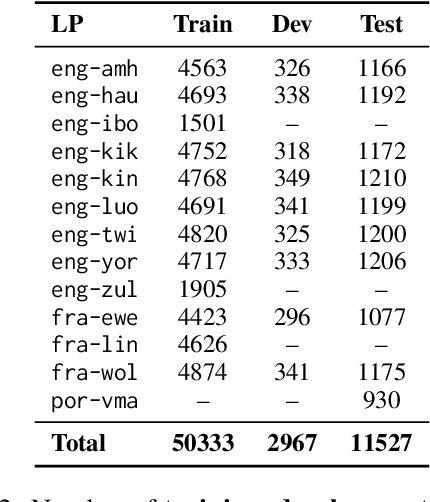
Evaluating machine translation (MT) quality for under-resourced African languages remains a significant challenge, as existing metrics often suffer from limited language coverage and poor performance in low-resource settings. While recent efforts, such as AfriCOMET, have addressed some of the issues, they are still constrained by small evaluation sets, a lack of publicly available training data tailored to African languages, and inconsistent performance in extremely low-resource scenarios. In this work, we introduce SSA-MTE, a large-scale human-annotated MT evaluation (MTE) dataset covering 13 African language pairs from the News domain, with over 63,000 sentence-level annotations from a diverse set of MT systems. Based on this data, we develop SSA-COMET and SSA-COMET-QE, improved reference-based and reference-free evaluation metrics. We also benchmark prompting-based approaches using state-of-the-art LLMs like GPT-4o and Claude. Our experimental results show that SSA-COMET models significantly outperform AfriCOMET and are competitive with the strongest LLM (Gemini 2.5 Pro) evaluated in our study, particularly on low-resource languages such as Twi, Luo, and Yoruba. All resources are released under open licenses to support future research.
Are Sparse Autoencoders Useful for Java Function Bug Detection?
May 15, 2025Software vulnerabilities such as buffer overflows and SQL injections are a major source of security breaches. Traditional methods for vulnerability detection remain essential but are limited by high false positive rates, scalability issues, and reliance on manual effort. These constraints have driven interest in AI-based approaches to automated vulnerability detection and secure code generation. While Large Language Models (LLMs) have opened new avenues for classification tasks, their complexity and opacity pose challenges for interpretability and deployment. Sparse Autoencoder offer a promising solution to this problem. We explore whether SAEs can serve as a lightweight, interpretable alternative for bug detection in Java functions. We evaluate the effectiveness of SAEs when applied to representations from GPT-2 Small and Gemma 2B, examining their capacity to highlight buggy behaviour without fine-tuning the underlying LLMs. We found that SAE-derived features enable bug detection with an F1 score of up to 89%, consistently outperforming fine-tuned transformer encoder baselines. Our work provides the first empirical evidence that SAEs can be used to detect software bugs directly from the internal representations of pretrained LLMs, without any fine-tuning or task-specific supervision.
Expanding FLORES+ Benchmark for more Low-Resource Settings: Portuguese-Emakhuwa Machine Translation Evaluation
Aug 21, 2024As part of the Open Language Data Initiative shared tasks, we have expanded the FLORES+ evaluation set to include Emakhuwa, a low-resource language widely spoken in Mozambique. We translated the dev and devtest sets from Portuguese into Emakhuwa, and we detail the translation process and quality assurance measures used. Our methodology involved various quality checks, including post-editing and adequacy assessments. The resulting datasets consist of multiple reference sentences for each source. We present baseline results from training a Neural Machine Translation system and fine-tuning existing multilingual translation models. Our findings suggest that spelling inconsistencies remain a challenge in Emakhuwa. Additionally, the baseline models underperformed on this evaluation set, underscoring the necessity for further research to enhance machine translation quality for Emakhuwa. The data is publicly available at https://huggingface.co/datasets/LIACC/Emakhuwa-FLORES.
FairytaleQA Translated: Enabling Educational Question and Answer Generation in Less-Resourced Languages
Jun 06, 2024Question Answering (QA) datasets are crucial in assessing reading comprehension skills for both machines and humans. While numerous datasets have been developed in English for this purpose, a noticeable void exists in less-resourced languages. To alleviate this gap, our paper introduces machine-translated versions of FairytaleQA, a renowned QA dataset designed to assess and enhance narrative comprehension skills in young children. By employing fine-tuned, modest-scale models, we establish benchmarks for both Question Generation (QG) and QA tasks within the translated datasets. In addition, we present a case study proposing a model for generating question-answer pairs, with an evaluation incorporating quality metrics such as question well-formedness, answerability, relevance, and children suitability. Our evaluation prioritizes quantifying and describing error cases, along with providing directions for future work. This paper contributes to the advancement of QA and QG research in less-resourced languages, promoting accessibility and inclusivity in the development of these models for reading comprehension. The code and data is publicly available at github.com/bernardoleite/fairytaleqa-translated.
PORTULAN ExtraGLUE Datasets and Models: Kick-starting a Benchmark for the Neural Processing of Portuguese
Apr 09, 2024Leveraging research on the neural modelling of Portuguese, we contribute a collection of datasets for an array of language processing tasks and a corresponding collection of fine-tuned neural language models on these downstream tasks. To align with mainstream benchmarks in the literature, originally developed in English, and to kick start their Portuguese counterparts, the datasets were machine-translated from English with a state-of-the-art translation engine. The resulting PORTULAN ExtraGLUE benchmark is a basis for research on Portuguese whose improvement can be pursued in future work. Similarly, the respective fine-tuned neural language models, developed with a low-rank adaptation approach, are made available as baselines that can stimulate future work on the neural processing of Portuguese. All datasets and models have been developed and are made available for two variants of Portuguese: European and Brazilian.
On Few-Shot Prompting for Controllable Question-Answer Generation in Narrative Comprehension
Apr 03, 2024Question Generation aims to automatically generate questions based on a given input provided as context. A controllable question generation scheme focuses on generating questions with specific attributes, allowing better control. In this study, we propose a few-shot prompting strategy for controlling the generation of question-answer pairs from children's narrative texts. We aim to control two attributes: the question's explicitness and underlying narrative elements. With empirical evaluation, we show the effectiveness of controlling the generation process by employing few-shot prompting side by side with a reference model. Our experiments highlight instances where the few-shot strategy surpasses the reference model, particularly in scenarios such as semantic closeness evaluation and the diversity and coherency of question-answer pairs. However, these improvements are not always statistically significant. The code is publicly available at github.com/bernardoleite/few-shot-prompting-qg-control.
Fostering the Ecosystem of Open Neural Encoders for Portuguese with Albertina PT* Family
Mar 05, 2024To foster the neural encoding of Portuguese, this paper contributes foundation encoder models that represent an expansion of the still very scarce ecosystem of large language models specifically developed for this language that are fully open, in the sense that they are open source and openly distributed for free under an open license for any purpose, thus including research and commercial usages. Like most languages other than English, Portuguese is low-resourced in terms of these foundational language resources, there being the inaugural 900 million parameter Albertina and 335 million Bertimbau. Taking this couple of models as an inaugural set, we present the extension of the ecosystem of state-of-the-art open encoders for Portuguese with a larger, top performance-driven model with 1.5 billion parameters, and a smaller, efficiency-driven model with 100 million parameters. While achieving this primary goal, further results that are relevant for this ecosystem were obtained as well, namely new datasets for Portuguese based on the SuperGLUE benchmark, which we also distribute openly.
Towards Enriched Controllability for Educational Question Generation
Jun 21, 2023Question Generation (QG) is a task within Natural Language Processing (NLP) that involves automatically generating questions given an input, typically composed of a text and a target answer. Recent work on QG aims to control the type of generated questions so that they meet educational needs. A remarkable example of controllability in educational QG is the generation of questions underlying certain narrative elements, e.g., causal relationship, outcome resolution, or prediction. This study aims to enrich controllability in QG by introducing a new guidance attribute: question explicitness. We propose to control the generation of explicit and implicit wh-questions from children-friendly stories. We show preliminary evidence of controlling QG via question explicitness alone and simultaneously with another target attribute: the question's narrative element. The code is publicly available at github.com/bernardoleite/question-generation-control.