 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Sentence Embeddings for Portuguese with the Serafim PT* encoders family
Jul 28, 2024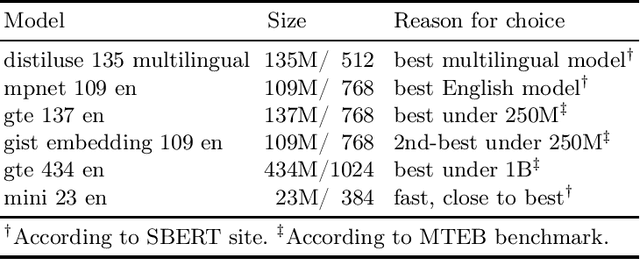

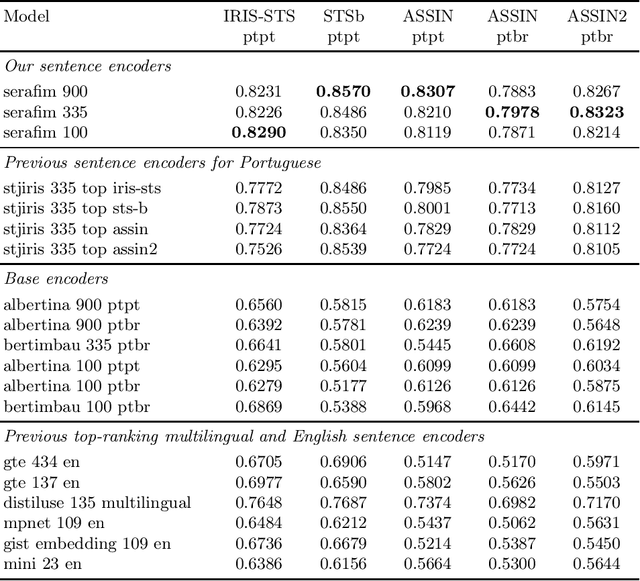
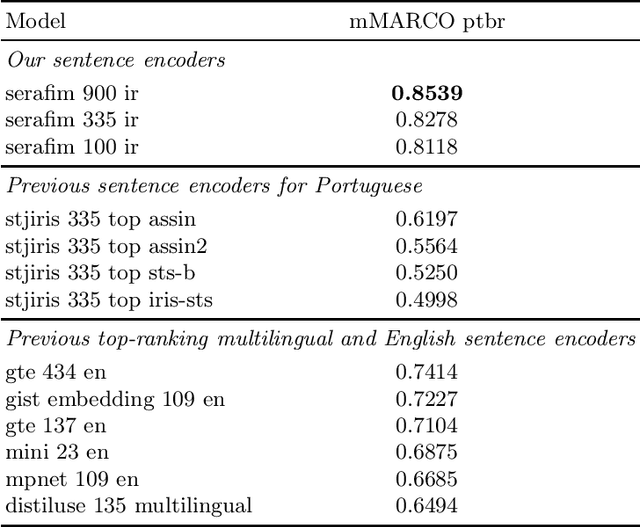
Sentence encoder encode the semantics of their input, enabling key downstream applications such as classification, clustering, or retrieval. In this paper, we present Serafim PT*, a family of open-source sentence encoders for Portuguese with various sizes, suited to different hardware/compute budgets. Each model exhibits state-of-the-art performance and is made openly available under a permissive license, allowing its use for both commercial and research purposes. Besides the sentence encoders, this paper contributes a systematic study and lessons learned concerning the selection criteria of learning objectives and parameters that support top-performing encoders.
Pix2Pix-OnTheFly: Leveraging LLMs for Instruction-Guided Image Editing
Mar 12, 2024The combination of language processing and image processing keeps attracting increased interest given recent impressive advances that leverage the combined strengths of both domains of research. Among these advances, the task of editing an image on the basis solely of a natural language instruction stands out as a most challenging endeavour. While recent approaches for this task resort, in one way or other, to some form of preliminary preparation, training or fine-tuning, this paper explores a novel approach: We propose a preparation-free method that permits instruction-guided image editing on the fly. This approach is organized along three steps properly orchestrated that resort to image captioning and DDIM inversion, followed by obtaining the edit direction embedding, followed by image editing proper. While dispensing with preliminary preparation, our approach demonstrates to be effective and competitive, outperforming recent, state of the art models for this task when evaluated on the MAGICBRUSH dataset.
Advancing Generative AI for Portuguese with Open Decoder Gervásio PT*
Mar 05, 2024
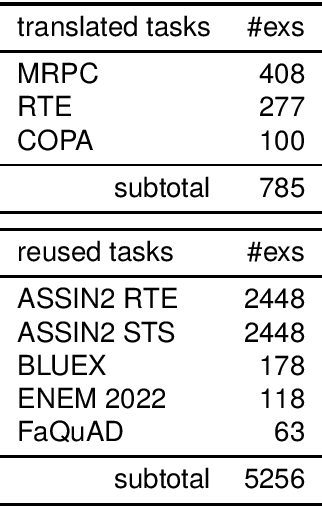
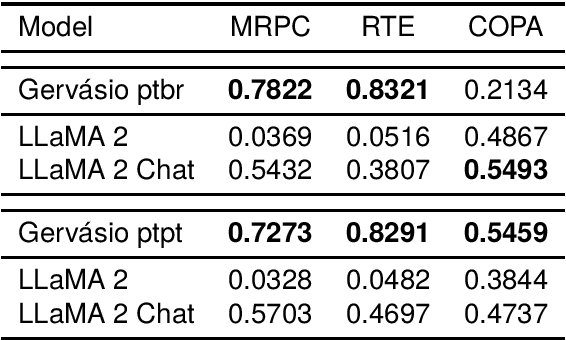
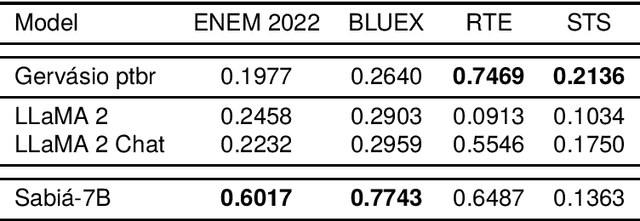
To advance the neural decoding of Portuguese, in this paper we present a fully open Transformer-based, instruction-tuned decoder model that sets a new state of the art in this respect. To develop this decoder, which we named Gerv\'asio PT*, a strong LLaMA~2 7B model was used as a starting point, and its further improvement through additional training was done over language resources that include new instruction data sets of Portuguese prepared for this purpose, which are also contributed in this paper. All versions of Gerv\'asio are open source and distributed for free under an open license, including for either research or commercial usage, and can be run on consumer-grade hardware, thus seeking to contribute to the advancement of research and innovation in language technology for Portuguese.
Fostering the Ecosystem of Open Neural Encoders for Portuguese with Albertina PT* Family
Mar 05, 2024To foster the neural encoding of Portuguese, this paper contributes foundation encoder models that represent an expansion of the still very scarce ecosystem of large language models specifically developed for this language that are fully open, in the sense that they are open source and openly distributed for free under an open license for any purpose, thus including research and commercial usages. Like most languages other than English, Portuguese is low-resourced in terms of these foundational language resources, there being the inaugural 900 million parameter Albertina and 335 million Bertimbau. Taking this couple of models as an inaugural set, we present the extension of the ecosystem of state-of-the-art open encoders for Portuguese with a larger, top performance-driven model with 1.5 billion parameters, and a smaller, efficiency-driven model with 100 million parameters. While achieving this primary goal, further results that are relevant for this ecosystem were obtained as well, namely new datasets for Portuguese based on the SuperGLUE benchmark, which we also distribute openly.
Advancing Neural Encoding of Portuguese with Transformer Albertina PT-*
May 11, 2023To advance the neural encoding of Portuguese (PT), and a fortiori the technological preparation of this language for the digital age, we developed a Transformer-based foundation model that sets a new state of the art in this respect for two of its variants, namely European Portuguese from Portugal (PT-PT) and American Portuguese from Brazil (PT-BR). To develop this encoder, which we named Albertina PT-*, a strong model was used as a starting point, DeBERTa, and its pre-training was done over data sets of Portuguese, namely over a data set we gathered for PT-PT and over the brWaC corpus for PT-BR. The performance of Albertina and competing models was assessed by evaluating them on prominent downstream language processing tasks adapted for Portuguese. Both Albertina PT-PT and PT-BR versions are distributed free of charge and under the most permissive license possible and can be run on consumer-grade hardware, thus seeking to contribute to the advancement of research and innovation in language technology for Portuguese.