 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaimPT: A Portuguese Dataset of Annotated Claims in News Articles
Jan 27, 2026Fact-checking remains a demanding and time-consuming task, still largely dependent on manual verification and unable to match the rapid spread of misinformation online. This is particularly important because debunking false information typically takes longer to reach consumers than the misinformation itself; accelerating corrections through automation can therefore help counter it more effectively. Although many organizations perform manual fact-checking, this approach is difficult to scale given the growing volume of digital content. These limitations have motivated interest in automating fact-checking, where identifying claims is a crucial first step. However, progress has been uneven across languages, with English dominating due to abundant annotated data. Portuguese, like other languages, still lacks accessible, licensed datasets, limiting research, NLP developments and applications. In this paper, we introduce ClaimPT, a dataset of European Portuguese news articles annotated for factual claims, comprising 1,308 articles and 6,875 individual annotations. Unlike most existing resources based on social media or parliamentary transcripts, ClaimPT focuses on journalistic content, collected through a partnership with LUSA, the Portuguese News Agency. To ensure annotation quality, two trained annotators labeled each article, with a curator validating all annotations according to a newly proposed scheme. We also provide baseline models for claim detection, establishing initial benchmarks and enabling future NLP and IR applications. By releasing ClaimPT, we aim to advance research on low-resource fact-checking and enhance understanding of misinformation in news media.
Multilingual Large Language Models: A Systematic Survey
Nov 19, 2024This paper provides a comprehensive survey of the latest research on multilingual large language models (MLLMs). MLLMs not only are able to understand and generate language across linguistic boundaries, but also represent an important advancement in artificial intelligence. We first discuss the architecture and pre-training objectives of MLLMs, highlighting the key components and methodologies that contribute to their multilingual capabilities. We then discuss the construction of multilingual pre-training and alignment datasets, underscoring the importance of data quality and diversity in enhancing MLLM performance. An important focus of this survey is on the evaluation of MLLMs. We present a detailed taxonomy and roadmap covering the assessment of MLLMs' cross-lingual knowledge, reasoning, alignment with human values, safety, interpretability and specialized applications. Specifically, we extensively discuss multilingual evaluation benchmarks and datasets, and explore the use of LLMs themselves as multilingual evaluators. To enhance MLLMs from black to white boxes, we also address the interpretability of multilingual capabilities, cross-lingual transfer and language bias within these models. Finally, we provide a comprehensive review of real-world applications of MLLMs across diverse domains, including biology, medicine, computer science, mathematics and law. We showcase how these models have driven innovation and improvements in these specialized fields while also highlighting the challenges and opportunities in deploying MLLMs within diverse language communities and application scenarios. We listed the paper related in this survey and publicly available at https://github.com/tjunlp-lab/Awesome-Multilingual-LLMs-Papers.
Open Sentence Embeddings for Portuguese with the Serafim PT* encoders family
Jul 28, 2024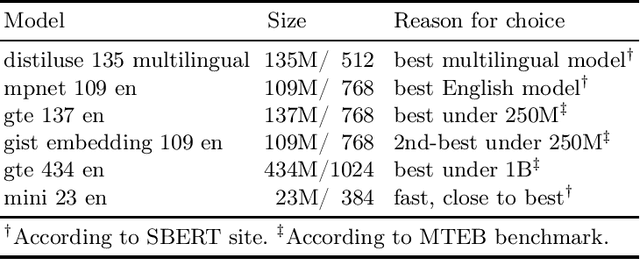

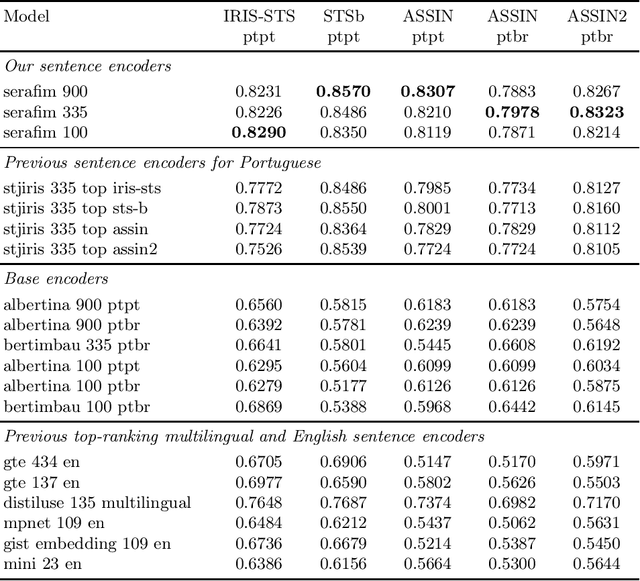
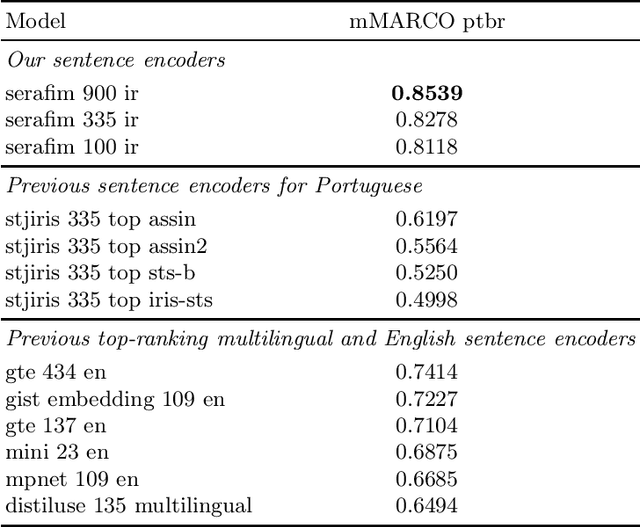
Sentence encoder encode the semantics of their input, enabling key downstream applications such as classification, clustering, or retrieval. In this paper, we present Serafim PT*, a family of open-source sentence encoders for Portuguese with various sizes, suited to different hardware/compute budgets. Each model exhibits state-of-the-art performance and is made openly available under a permissive license, allowing its use for both commercial and research purposes. Besides the sentence encoders, this paper contributes a systematic study and lessons learned concerning the selection criteria of learning objectives and parameters that support top-performing encoders.
Meta-prompting Optimized Retrieval-augmented Generation
Jul 04, 2024


Retrieval-augmented generation resorts to content retrieved from external sources in order to leverage the performance of large language models in downstream tasks. The excessive volume of retrieved content, the possible dispersion of its parts, or their out of focus range may happen nevertheless to eventually have a detrimental rather than an incremental effect. To mitigate this issue and improve retrieval-augmented generation, we propose a method to refine the retrieved content before it is included in the prompt by resorting to meta-prompting optimization. Put to empirical test with the demanding multi-hop question answering task from the StrategyQA dataset, the evaluation results indicate that this method outperforms a similar retrieval-augmented system but without this method by over 30%.
PORTULAN ExtraGLUE Datasets and Models: Kick-starting a Benchmark for the Neural Processing of Portuguese
Apr 09, 2024Leveraging research on the neural modelling of Portuguese, we contribute a collection of datasets for an array of language processing tasks and a corresponding collection of fine-tuned neural language models on these downstream tasks. To align with mainstream benchmarks in the literature, originally developed in English, and to kick start their Portuguese counterparts, the datasets were machine-translated from English with a state-of-the-art translation engine. The resulting PORTULAN ExtraGLUE benchmark is a basis for research on Portuguese whose improvement can be pursued in future work. Similarly, the respective fine-tuned neural language models, developed with a low-rank adaptation approach, are made available as baselines that can stimulate future work on the neural processing of Portuguese. All datasets and models have been developed and are made available for two variants of Portuguese: European and Brazilian.
Pix2Pix-OnTheFly: Leveraging LLMs for Instruction-Guided Image Editing
Mar 12, 2024The combination of language processing and image processing keeps attracting increased interest given recent impressive advances that leverage the combined strengths of both domains of research. Among these advances, the task of editing an image on the basis solely of a natural language instruction stands out as a most challenging endeavour. While recent approaches for this task resort, in one way or other, to some form of preliminary preparation, training or fine-tuning, this paper explores a novel approach: We propose a preparation-free method that permits instruction-guided image editing on the fly. This approach is organized along three steps properly orchestrated that resort to image captioning and DDIM inversion, followed by obtaining the edit direction embedding, followed by image editing proper. While dispensing with preliminary preparation, our approach demonstrates to be effective and competitive, outperforming recent, state of the art models for this task when evaluated on the MAGICBRUSH dataset.
Fostering the Ecosystem of Open Neural Encoders for Portuguese with Albertina PT* Family
Mar 05, 2024To foster the neural encoding of Portuguese, this paper contributes foundation encoder models that represent an expansion of the still very scarce ecosystem of large language models specifically developed for this language that are fully open, in the sense that they are open source and openly distributed for free under an open license for any purpose, thus including research and commercial usages. Like most languages other than English, Portuguese is low-resourced in terms of these foundational language resources, there being the inaugural 900 million parameter Albertina and 335 million Bertimbau. Taking this couple of models as an inaugural set, we present the extension of the ecosystem of state-of-the-art open encoders for Portuguese with a larger, top performance-driven model with 1.5 billion parameters, and a smaller, efficiency-driven model with 100 million parameters. While achieving this primary goal, further results that are relevant for this ecosystem were obtained as well, namely new datasets for Portuguese based on the SuperGLUE benchmark, which we also distribute openly.
Advancing Generative AI for Portuguese with Open Decoder Gervásio PT*
Mar 05, 2024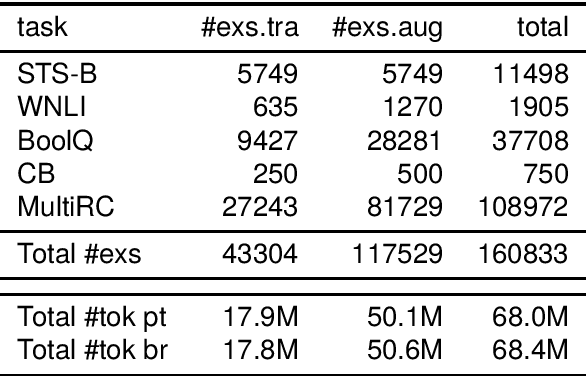
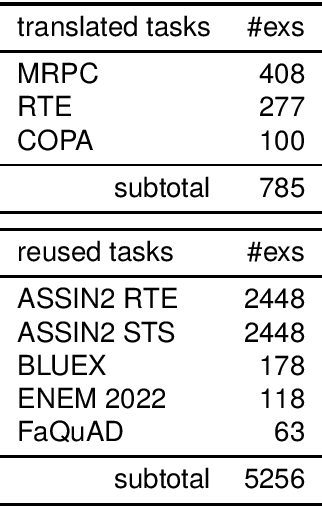
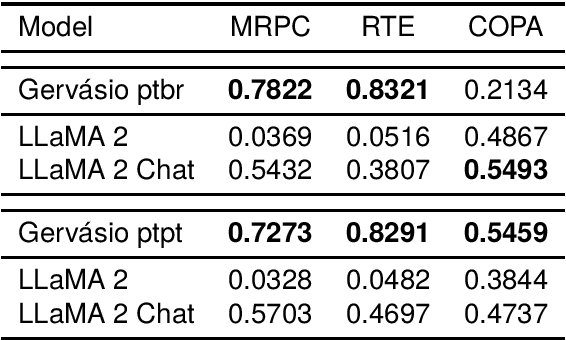
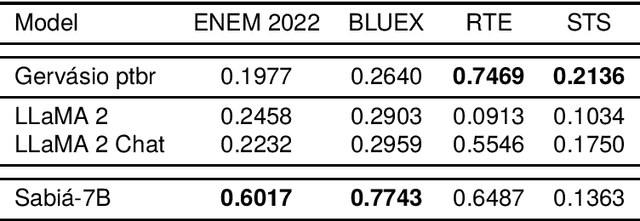
To advance the neural decoding of Portuguese, in this paper we present a fully open Transformer-based, instruction-tuned decoder model that sets a new state of the art in this respect. To develop this decoder, which we named Gerv\'asio PT*, a strong LLaMA~2 7B model was used as a starting point, and its further improvement through additional training was done over language resources that include new instruction data sets of Portuguese prepared for this purpose, which are also contributed in this paper. All versions of Gerv\'asio are open source and distributed for free under an open license, including for either research or commercial usage, and can be run on consumer-grade hardware, thus seeking to contribute to the advancement of research and innovation in language technology for Portuguese.
Advancing Neural Encoding of Portuguese with Transformer Albertina PT-*
May 11, 2023To advance the neural encoding of Portuguese (PT), and a fortiori the technological preparation of this language for the digital age, we developed a Transformer-based foundation model that sets a new state of the art in this respect for two of its variants, namely European Portuguese from Portugal (PT-PT) and American Portuguese from Brazil (PT-BR). To develop this encoder, which we named Albertina PT-*, a strong model was used as a starting point, DeBERTa, and its pre-training was done over data sets of Portuguese, namely over a data set we gathered for PT-PT and over the brWaC corpus for PT-BR. The performance of Albertina and competing models was assessed by evaluating them on prominent downstream language processing tasks adapted for Portuguese. Both Albertina PT-PT and PT-BR versions are distributed free of charge and under the most permissive license possible and can be run on consumer-grade hardware, thus seeking to contribute to the advancement of research and innovation in language technology for Portuguese.
Transfer Learning of Lexical Semantic Families for Argumentative Discourse Units Identification
Sep 06, 2022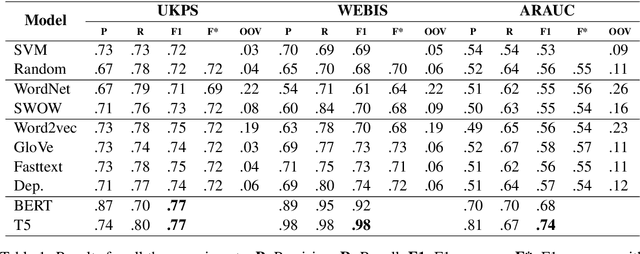



Argument mining tasks require an informed range of low to high complexity linguistic phenomena and commonsense knowledge. Previous work has shown that pre-trained language models are highly effective at encoding syntactic and semantic linguistic phenomena when applied with transfer learning techniques and built on different pre-training objectives. It remains an issue of how much the existing pre-trained language models encompass the complexity of argument mining tasks. We rely on experimentation to shed light on how language models obtained from different lexical semantic families leverage the performance of the identification of argumentative discourse units task. Experimental results show that transfer learning techniques are beneficial to the task and that current methods may be insufficient to leverage commonsense knowledge from different lexical semantic families.