 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling, Benchmarking, and Reasoning of Vision-Language Agents for Mobile GUI Navigation
May 26, 2026Vision-Language Models (VLMs) have shown rapid progress in mobile GUI navigation. This paper presents a systematic study of data scaling, benchmarking, and reasoning for VLM-based agents in this domain. To facilitate rigorous evaluation, we introduce HyperTrack, a large-scale dataset with over 16000 real-world tasks across more than 650 Chinese mobile applications, along with GUIEvalKit, an open-source toolkit for unified benchmarking of VLMs on offline GUI navigation tasks. Using HyperTrack, we analyze the effects of training data scale on both supervised and reinforcement-based finetuning. Our results show that reinforcement-based finetuning consistently outperforms supervised finetuning, particularly in out-of-domain settings, highlighting the synergy between data scaling and reinforcement learning. Leveraging GUIEvalKit, we further benchmark state-of-the-art (SOTA) VLMs and analyze how interaction history and reasoning capabilities influence task completion. Together, HyperTrack and GUIEvalKit provide a comprehensive platform for developing and evaluating VLM agents in mobile GUI navigation tasks.
Why Does Reinforcement Learning Generalize? A Feature-Level Mechanistic Study of Post-Training in Large Language Models
Apr 27, 2026Reinforcement learning (RL)-based post-training often improves the reasoning performance of large language models (LLMs) beyond the training domain, while supervised fine-tuning (SFT) frequently leads to general capabilities forgetting. However, the mechanisms underlying this contrast remain unclear. To bridge this gap, we present a feature-level mechanistic analysis methodology to probe RL generalization using a controlled experimental setup, where RL- and SFT-tuned models are trained from the same base model on identical data. Leveraging our interpretability framework, we align internal activations across models within a shared feature space and analyze how features evolve during post-training. We find that SFT rapidly introduces many highly specialized features that stabilize early in training, whereas RL induces more restrained and continually evolving feature changes that largely preserve base models' representations. Focusing on samples where RL succeeds but the base model fails, we identify a compact, task-agnostic set of features that directly mediate generalization across diverse tasks. Feature-level interventions confirm their causal role: disabling these features significantly degrades RL models' generalization performance, while amplifying them improves base models' performance. The code is available at https://github.com/danshi777/RL-generalization.
KnowRL: Boosting LLM Reasoning via Reinforcement Learning with Minimal-Sufficient Knowledge Guidance
Apr 14, 2026RLVR improves reasoning in large language models, but its effectiveness is often limited by severe reward sparsity on hard problems. Recent hint-based RL methods mitigate sparsity by injecting partial solutions or abstract templates, yet they typically scale guidance by adding more tokens, which introduce redundancy, inconsistency, and extra training overhead. We propose \textbf{KnowRL} (Knowledge-Guided Reinforcement Learning), an RL training framework that treats hint design as a minimal-sufficient guidance problem. During RL training, KnowRL decomposes guidance into atomic knowledge points (KPs) and uses Constrained Subset Search (CSS) to construct compact, interaction-aware subsets for training. We further identify a pruning interaction paradox -- removing one KP may help while removing multiple such KPs can hurt -- and explicitly optimize for robust subset curation under this dependency structure. We train KnowRL-Nemotron-1.5B from OpenMath-Nemotron-1.5B. Across eight reasoning benchmarks at the 1.5B scale, KnowRL-Nemotron-1.5B consistently outperforms strong RL and hinting baselines. Without KP hints at inference, KnowRL-Nemotron-1.5B reaches 70.08 average accuracy, already surpassing Nemotron-1.5B by +9.63 points; with selected KPs, performance improves to 74.16, establishing a new state of the art at this scale. The model, curated training data, and code are publicly available at https://github.com/Hasuer/KnowRL.
SOUP: Token-level Single-sample Mix-policy Reinforcement Learning for Large Language Models
Jan 29, 2026On-policy reinforcement learning (RL) methods widely used for language model post-training, like Group Relative Policy Optimization (GRPO), often suffer from limited exploration and early saturation due to low sampling diversity. While off-policy data can help, current approaches that mix entire trajectories cause significant policy mismatch and instability. In this work, we propose the $\textbf{S}$ingle-sample Mix-p$\textbf{O}$licy $\textbf{U}$nified $\textbf{P}$aradigm (SOUP), a framework that unifies off- and on-policy learning within individual samples at the token level. It confines off-policy influence to the prefix of a generated sequence sampled from historical policies, while the continuation is generated on-policy. Through token-level importance ratios, SOUP effectively leverages off-policy information while preserving training stability. Extensive experiments demonstrate that SOUP consistently outperforms standard on-policy training and existing off-policy extensions. Our further analysis clarifies how our fine-grained, single-sample mix-policy training can improve both exploration and final performance in LLM RL.
Revisiting Entropy in Reinforcement Learning for Large Reasoning Models
Nov 08, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a predominant approach for enhancing the reasoning capabilities of large language models (LLMs). However, the entropy of LLMs usually collapses during RLVR training, causing premature convergence to suboptimal local minima and hinder further performance improvement. Although various approaches have been proposed to mitigate entropy collapse, a comprehensive study of entropy in RLVR remains lacking. To address this gap, we conduct extensive experiments to investigate the entropy dynamics of LLMs trained with RLVR and analyze how model entropy correlates with response diversity, calibration, and performance across various benchmarks. Our findings reveal that the number of off-policy updates, the diversity of training data, and the clipping thresholds in the optimization objective are critical factors influencing the entropy of LLMs trained with RLVR. Moreover, we theoretically and empirically demonstrate that tokens with positive advantages are the primary contributors to entropy collapse, and that model entropy can be effectively regulated by adjusting the relative loss weights of tokens with positive and negative advantages during training.
Joint Training And Decoding for Multilingual End-to-End Simultaneous Speech Translation
Mar 14, 2025Recent studies on end-to-end speech translation(ST) have facilitated the exploration of multilingual end-to-end ST and end-to-end simultaneous ST. In this paper, we investigate end-to-end simultaneous speech translation in a one-to-many multilingual setting which is closer to applications in real scenarios. We explore a separate decoder architecture and a unified architecture for joint synchronous training in this scenario. To further explore knowledge transfer across languages, we propose an asynchronous training strategy on the proposed unified decoder architecture. A multi-way aligned multilingual end-to-end ST dataset was curated as a benchmark testbed to evaluate our methods. Experimental results demonstrate the effectiveness of our models on the collected dataset. Our codes and data are available at: https://github.com/XiaoMi/TED-MMST.
ProBench: Benchmarking Large Language Models in Competitive Programming
Feb 28, 2025With reasoning language models such as OpenAI-o3 and DeepSeek-R1 emerging, large language models (LLMs) have entered a new phase of development. However, existing benchmarks for coding evaluation are gradually inadequate to assess the capability of advanced LLMs in code reasoning. To bridge the gap for high-level code reasoning assessment, we propose ProBench to benchmark LLMs in competitive programming, drawing inspiration from the International Collegiate Programming Contest. ProBench collects a comprehensive set of competitive programming problems from Codeforces, Luogu, and Nowcoder platforms during the period from July to December 2024, obtaining real test results through online submissions to ensure the fairness and accuracy of the evaluation. We establish a unified problem attribute system, including difficulty grading and algorithm tagging. With carefully collected and annotated data in ProBench, we systematically assess 9 latest LLMs in competitive programming across multiple dimensions, including thought chain analysis, error type diagnosis, and reasoning depth evaluation. Experimental results show that QwQ-32B-Preview achieves the best score of 20.93 followed by DeepSeek-V3 with a score of 16.38, suggesting that models trained with specialized reasoning tasks significantly outperform general-purpose models (even larger than reasoning-oriented models) in programming. Further analysis also reveals key areas for programming capability enhancement, e.g., algorithm adaptability and reasoning sufficiency, providing important insights for the future development of reasoning models.
Large Language Model Safety: A Holistic Survey
Dec 23, 2024



The rapid development and deployment of large language models (LLMs) have introduced a new frontier in artificial intelligence, marked by unprecedented capabilities in natural language understanding and generation. However, the increasing integration of these models into critical applications raises substantial safety concerns, necessitating a thorough examination of their potential risks and associated mitigation strategies. This survey provides a comprehensive overview of the current landscape of LLM safety, covering four major categories: value misalignment, robustness to adversarial attacks, misuse, and autonomous AI risks. In addition to the comprehensive review of the mitigation methodologies and evaluation resources on these four aspects, we further explore four topics related to LLM safety: the safety implications of LLM agents, the role of interpretability in enhancing LLM safety, the technology roadmaps proposed and abided by a list of AI companies and institutes for LLM safety, and AI governance aimed at LLM safety with discussions on international cooperation, policy proposals, and prospective regulatory directions. Our findings underscore the necessity for a proactive, multifaceted approach to LLM safety, emphasizing the integration of technical solutions, ethical considerations, and robust governance frameworks. This survey is intended to serve as a foundational resource for academy researchers, industry practitioners, and policymakers, offering insights into the challenges and opportunities associated with the safe integration of LLMs into society. Ultimately, it seeks to contribute to the safe and beneficial development of LLMs, aligning with the overarching goal of harnessing AI for societal advancement and well-being. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLM-Safety-Papers.
Star-Agents: Automatic Data Optimization with LLM Agents for Instruction Tuning
Nov 21, 2024

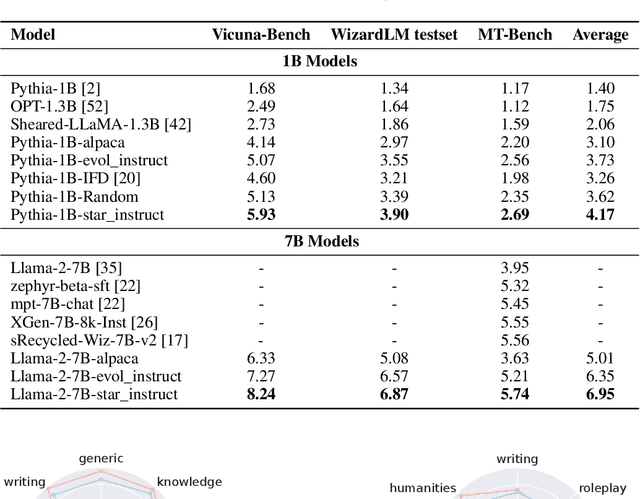
The efficacy of large language models (LLMs) on downstream tasks usually hinges on instruction tuning, which relies critically on the quality of training data. Unfortunately, collecting high-quality and diverse data is both expensive and time-consuming. To mitigate this issue, we propose a novel Star-Agents framework, which automates the enhancement of data quality across datasets through multi-agent collaboration and assessment. The framework adopts a three-pronged strategy. It initially generates diverse instruction data with multiple LLM agents through a bespoke sampling method. Subsequently, the generated data undergo a rigorous evaluation using a dual-model method that assesses both difficulty and quality. Finaly, the above process evolves in a dynamic refinement phase, where more effective LLMs are prioritized, enhancing the overall data quality. Our empirical studies, including instruction tuning experiments with models such as Pythia and LLaMA, demonstrate the effectiveness of the proposed framework. Optimized datasets have achieved substantial improvements, with an average increase of 12% and notable gains in specific metrics, such as a 40% improvement in Fermi, as evidenced by benchmarks like MT-bench, Vicuna bench, and WizardLM testset.
Multilingual Large Language Models: A Systematic Survey
Nov 19, 2024This paper provides a comprehensive survey of the latest research on multilingual large language models (MLLMs). MLLMs not only are able to understand and generate language across linguistic boundaries, but also represent an important advancement in artificial intelligence. We first discuss the architecture and pre-training objectives of MLLMs, highlighting the key components and methodologies that contribute to their multilingual capabilities. We then discuss the construction of multilingual pre-training and alignment datasets, underscoring the importance of data quality and diversity in enhancing MLLM performance. An important focus of this survey is on the evaluation of MLLMs. We present a detailed taxonomy and roadmap covering the assessment of MLLMs' cross-lingual knowledge, reasoning, alignment with human values, safety, interpretability and specialized applications. Specifically, we extensively discuss multilingual evaluation benchmarks and datasets, and explore the use of LLMs themselves as multilingual evaluators. To enhance MLLMs from black to white boxes, we also address the interpretability of multilingual capabilities, cross-lingual transfer and language bias within these models. Finally, we provide a comprehensive review of real-world applications of MLLMs across diverse domains, including biology, medicine, computer science, mathematics and law. We showcase how these models have driven innovation and improvements in these specialized fields while also highlighting the challenges and opportunities in deploying MLLMs within diverse language communities and application scenarios. We listed the paper related in this survey and publicly available at https://github.com/tjunlp-lab/Awesome-Multilingual-LLMs-Papers.