 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Timescale Gradient Sliding for Distributed Optimization
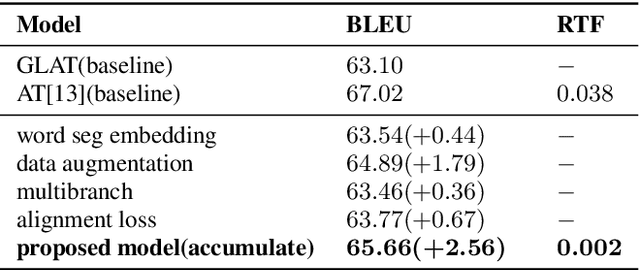
Jun 18, 2025We propose two first-order methods for convex, non-smooth, distributed optimization problems, hereafter called Multi-Timescale Gradient Sliding (MT-GS) and its accelerated variant (AMT-GS). Our MT-GS and AMT-GS can take advantage of similarities between (local) objectives to reduce the communication rounds, are flexible so that different subsets (of agents) can communicate at different, user-picked rates, and are fully deterministic. These three desirable features are achieved through a block-decomposable primal-dual formulation, and a multi-timescale variant of the sliding method introduced in Lan et al. (2020), Lan (2016), where different dual blocks are updated at potentially different rates. To find an $\epsilon$-suboptimal solution, the complexities of our algorithms achieve optimal dependency on $\epsilon$: MT-GS needs $O(\overline{r}A/\epsilon)$ communication rounds and $O(\overline{r}/\epsilon^2)$ subgradient steps for Lipchitz objectives, and AMT-GS needs $O(\overline{r}A/\sqrt{\epsilon\mu})$ communication rounds and $O(\overline{r}/(\epsilon\mu))$ subgradient steps if the objectives are also $\mu$-strongly convex. Here, $\overline{r}$ measures the ``average rate of updates'' for dual blocks, and $A$ measures similarities between (subgradients of) local functions. In addition, the linear dependency of communication rounds on $A$ is optimal (Arjevani and Shamir 2015), thereby providing a positive answer to the open question whether such dependency is achievable for non-smooth objectives (Arjevani and Shamir 2015).
Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
PARF-Net: integrating pixel-wise adaptive receptive fields into hybrid Transformer-CNN network for medical image segmentation
Jan 06, 2025



Convolutional neural networks (CNNs) excel in local feature extraction while Transformers are superior in processing global semantic information. By leveraging the strengths of both, hybrid Transformer-CNN networks have become the major architectures in medical image segmentation tasks. However, existing hybrid methods still suffer deficient learning of local semantic features due to the fixed receptive fields of convolutions, and also fall short in effectively integrating local and long-range dependencies. To address these issues, we develop a new method PARF-Net to integrate convolutions of Pixel-wise Adaptive Receptive Fields (Conv-PARF) into hybrid Network for medical image segmentation. The Conv-PARF is introduced to cope with inter-pixel semantic differences and dynamically adjust convolutional receptive fields for each pixel, thus providing distinguishable features to disentangle the lesions with varying shapes and scales from the background. The features derived from the Conv-PARF layers are further processed using hybrid Transformer-CNN blocks under a lightweight manner, to effectively capture local and long-range dependencies, thus boosting the segmentation performance. By assessing PARF-Net on four widely used medical image datasets including MoNuSeg, GlaS, DSB2018 and multi-organ Synapse, we showcase the advantages of our method over the state-of-the-arts. For instance, PARF-Net achieves 84.27% mean Dice on the Synapse dataset, surpassing existing methods by a large margin.
OpenEval: Benchmarking Chinese LLMs across Capability, Alignment and Safety
Mar 18, 2024



The rapid development of Chinese large language models (LLMs) poses big challenges for efficient LLM evaluation. While current initiatives have introduced new benchmarks or evaluation platforms for assessing Chinese LLMs, many of these focus primarily on capabilities, usually overlooking potential alignment and safety issues. To address this gap, we introduce OpenEval, an evaluation testbed that benchmarks Chinese LLMs across capability, alignment and safety. For capability assessment, we include 12 benchmark datasets to evaluate Chinese LLMs from 4 sub-dimensions: NLP tasks, disciplinary knowledge, commonsense reasoning and mathematical reasoning. For alignment assessment, OpenEval contains 7 datasets that examines the bias, offensiveness and illegalness in the outputs yielded by Chinese LLMs. To evaluate safety, especially anticipated risks (e.g., power-seeking, self-awareness) of advanced LLMs, we include 6 datasets. In addition to these benchmarks, we have implemented a phased public evaluation and benchmark update strategy to ensure that OpenEval is in line with the development of Chinese LLMs or even able to provide cutting-edge benchmark datasets to guide the development of Chinese LLMs. In our first public evaluation, we have tested a range of Chinese LLMs, spanning from 7B to 72B parameters, including both open-source and proprietary models. Evaluation results indicate that while Chinese LLMs have shown impressive performance in certain tasks, more attention should be directed towards broader aspects such as commonsense reasoning, alignment, and safety.
Memory-Constrained Algorithms for Convex Optimization via Recursive Cutting-Planes
Jun 16, 2023We propose a family of recursive cutting-plane algorithms to solve feasibility problems with constrained memory, which can also be used for first-order convex optimization. Precisely, in order to find a point within a ball of radius $\epsilon$ with a separation oracle in dimension $d$ -- or to minimize $1$-Lipschitz convex functions to accuracy $\epsilon$ over the unit ball -- our algorithms use $\mathcal O(\frac{d^2}{p}\ln \frac{1}{\epsilon})$ bits of memory, and make $\mathcal O((C\frac{d}{p}\ln \frac{1}{\epsilon})^p)$ oracle calls, for some universal constant $C \geq 1$. The family is parametrized by $p\in[d]$ and provides an oracle-complexity/memory trade-off in the sub-polynomial regime $\ln\frac{1}{\epsilon}\gg\ln d$. While several works gave lower-bound trade-offs (impossibility results) -- we explicit here their dependence with $\ln\frac{1}{\epsilon}$, showing that these also hold in any sub-polynomial regime -- to the best of our knowledge this is the first class of algorithms that provides a positive trade-off between gradient descent and cutting-plane methods in any regime with $\epsilon\leq 1/\sqrt d$. The algorithms divide the $d$ variables into $p$ blocks and optimize over blocks sequentially, with approximate separation vectors constructed using a variant of Vaidya's method. In the regime $\epsilon \leq d^{-\Omega(d)}$, our algorithm with $p=d$ achieves the information-theoretic optimal memory usage and improves the oracle-complexity of gradient descent.
Quadratic Memory is Necessary for Optimal Query Complexity in Convex Optimization: Center-of-Mass is Pareto-Optimal
Feb 09, 2023
We give query complexity lower bounds for convex optimization and the related feasibility problem. We show that quadratic memory is necessary to achieve the optimal oracle complexity for first-order convex optimization. In particular, this shows that center-of-mass cutting-planes algorithms in dimension $d$ which use $\tilde O(d^2)$ memory and $\tilde O(d)$ queries are Pareto-optimal for both convex optimization and the feasibility problem, up to logarithmic factors. Precisely, we prove that to minimize $1$-Lipschitz convex functions over the unit ball to $1/d^4$ accuracy, any deterministic first-order algorithms using at most $d^{2-\delta}$ bits of memory must make $\tilde\Omega(d^{1+\delta/3})$ queries, for any $\delta\in[0,1]$. For the feasibility problem, in which an algorithm only has access to a separation oracle, we show a stronger trade-off: for at most $d^{2-\delta}$ memory, the number of queries required is $\tilde\Omega(d^{1+\delta})$. This resolves a COLT 2019 open problem of Woodworth and Srebro.
Direct Speech-to-speech Translation without Textual Annotation using Bottleneck Features
Dec 12, 2022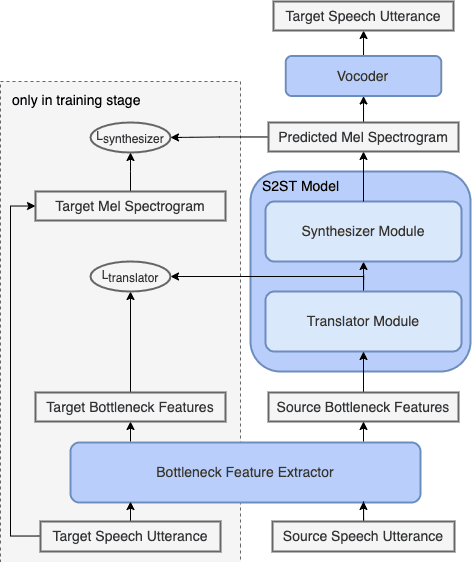

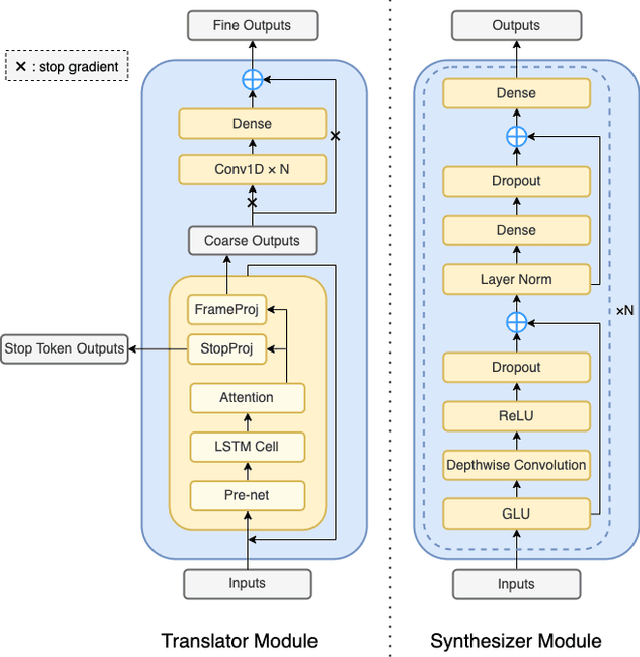
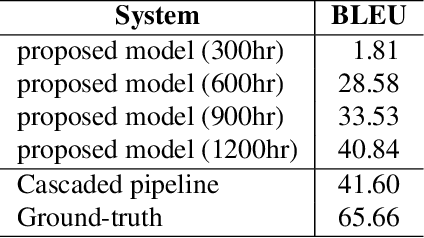
Speech-to-speech translation directly translates a speech utterance to another between different languages, and has great potential in tasks such as simultaneous interpretation. State-of-art models usually contains an auxiliary module for phoneme sequences prediction, and this requires textual annotation of the training dataset. We propose a direct speech-to-speech translation model which can be trained without any textual annotation or content information. Instead of introducing an auxiliary phoneme prediction task in the model, we propose to use bottleneck features as intermediate training objectives for our model to ensure the translation performance of the system. Experiments on Mandarin-Cantonese speech translation demonstrate the feasibility of the proposed approach and the performance can match a cascaded system with respect of translation and synthesis qualities.
A Novel Chinese Dialect TTS Frontend with Non-Autoregressive Neural Machine Translation
Jun 15, 2022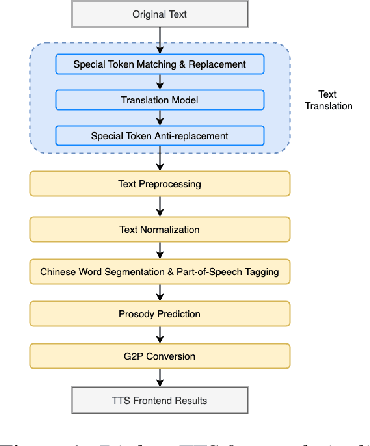


Chinese dialect text-to-speech(TTS) system usually can only be utilized by native linguists, because the written form of Chinese dialects has different characters, idioms, grammar and usage from Mandarin, and even the local speaker cannot input a correct sentence. For Mandarin text inputs, Chinese dialect TTS can only generate partly-meaningful speech with relatively poor prosody and naturalness. To lower the bar of use and make it more practical in commercial, we propose a novel Chinese dialect TTS frontend with a translation module. It helps to convert Mandarin text into idiomatic expressions with correct orthography and grammar, so that the intelligibility and naturalness of the synthesized speech can be improved. A non-autoregressive neural machine translation model with a glancing sampling strategy is proposed for the translation task. It is the first known work to incorporate translation with TTS frontend. Our experiments on Cantonese approve that the proposed frontend can help Cantonese TTS system achieve a 0.27 improvement in MOS with Mandarin inputs.
Principal Component Pursuit for Pattern Identification in Environmental Mixtures
Oct 29, 2021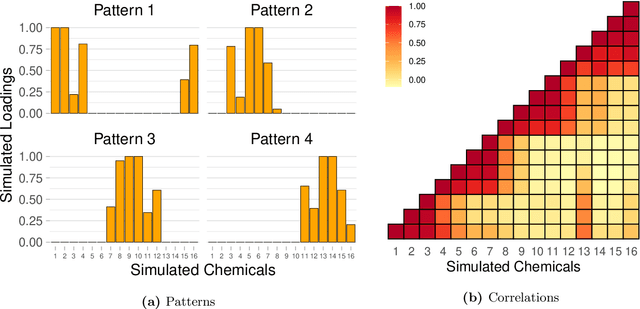
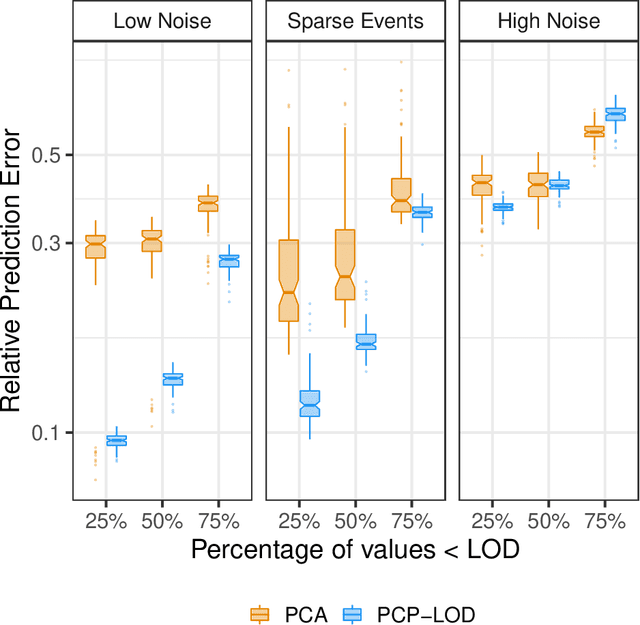
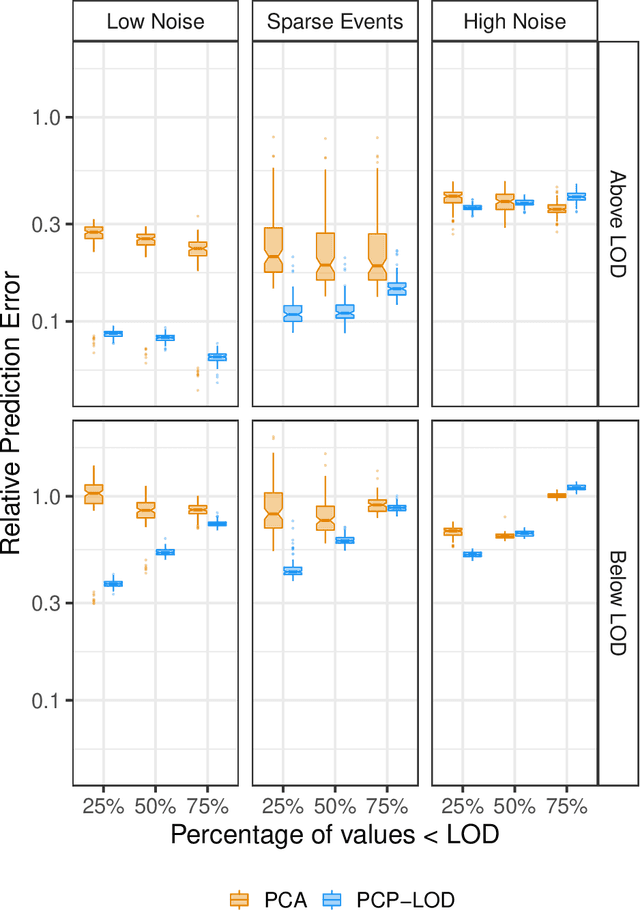
Environmental health researchers often aim to identify sources/behaviors that give rise to potentially harmful exposures. We adapted principal component pursuit (PCP)-a robust technique for dimensionality reduction in computer vision and signal processing-to identify patterns in environmental mixtures. PCP decomposes the exposure mixture into a low-rank matrix containing consistent exposure patterns across pollutants and a sparse matrix isolating unique exposure events. We adapted PCP to accommodate non-negative and missing data, and values below a given limit of detection (LOD). We simulated data to represent environmental mixtures of two sizes with increasing proportions <LOD and three noise structures. We compared PCP-LOD to principal component analysis (PCA) to evaluate performance. We next applied PCP-LOD to a mixture of 21 persistent organic pollutants (POPs) measured in 1,000 U.S. adults from the 2001-2002 National Health and Nutrition Examination Survey. We applied singular value decomposition to the estimated low-rank matrix to characterize the patterns. PCP-LOD recovered the true number of patterns through cross-validation for all simulations; based on an a priori specified criterion, PCA recovered the true number of patterns in 32% of simulations. PCP-LOD achieved lower relative predictive error than PCA for all simulated datasets with up to 50% of the data <LOD. When 75% of values were <LOD, PCP-LOD outperformed PCA only when noise was low. In the POP mixture, PCP-LOD identified a rank-three underlying structure and separated 6% of values as unique events. One pattern represented comprehensive exposure to all POPs. The other patterns grouped chemicals based on known structure and toxicity. PCP-LOD serves as a useful tool to express multi-dimensional exposures as consistent patterns that, if found to be related to adverse health, are amenable to targeted interventions.
Cross-speaker Emotion Transfer Based on Speaker Condition Layer Normalization and Semi-Supervised Training in Text-To-Speech
Oct 11, 2021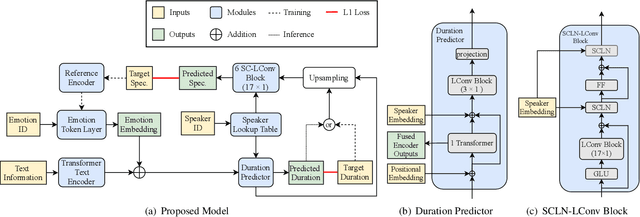

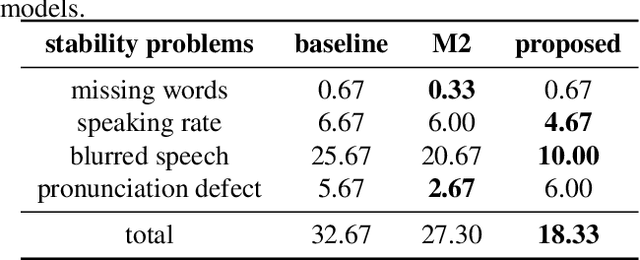
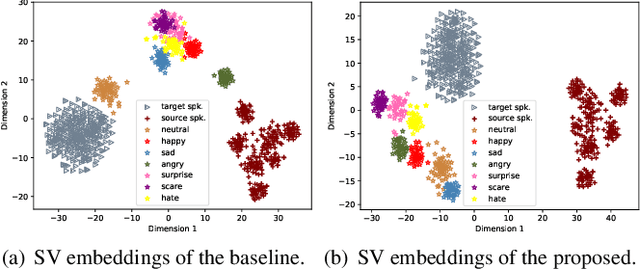
In expressive speech synthesis, there are high requirements for emotion interpretation. However, it is time-consuming to acquire emotional audio corpus for arbitrary speakers due to their deduction ability. In response to this problem, this paper proposes a cross-speaker emotion transfer method that can realize the transfer of emotions from source speaker to target speaker. A set of emotion tokens is firstly defined to represent various categories of emotions. They are trained to be highly correlated with corresponding emotions for controllable synthesis by cross-entropy loss and semi-supervised training strategy. Meanwhile, to eliminate the down-gradation to the timbre similarity from cross-speaker emotion transfer, speaker condition layer normalization is implemented to model speaker characteristics. Experimental results show that the proposed method outperforms the multi-reference based baseline in terms of timbre similarity, stability and emotion perceive evaluations.