 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-speaker Emotion Transfer Based on Speaker Condition Layer Normalization and Semi-Supervised Training in Text-To-Speech
Oct 11, 2021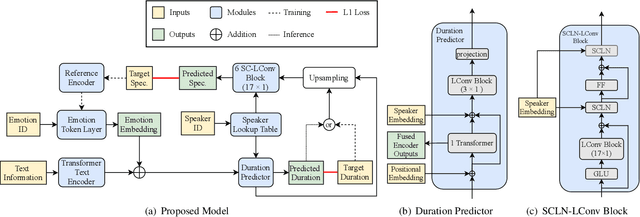

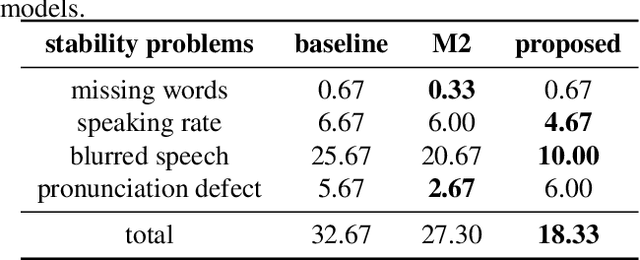
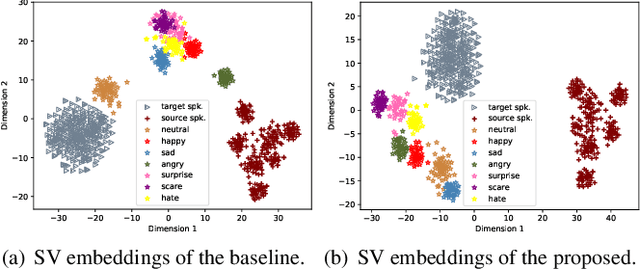
In expressive speech synthesis, there are high requirements for emotion interpretation. However, it is time-consuming to acquire emotional audio corpus for arbitrary speakers due to their deduction ability. In response to this problem, this paper proposes a cross-speaker emotion transfer method that can realize the transfer of emotions from source speaker to target speaker. A set of emotion tokens is firstly defined to represent various categories of emotions. They are trained to be highly correlated with corresponding emotions for controllable synthesis by cross-entropy loss and semi-supervised training strategy. Meanwhile, to eliminate the down-gradation to the timbre similarity from cross-speaker emotion transfer, speaker condition layer normalization is implemented to model speaker characteristics. Experimental results show that the proposed method outperforms the multi-reference based baseline in terms of timbre similarity, stability and emotion perceive evaluations.