 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRRT*former: Environment-Aware Sampling-Based Motion Planning using Transformer
Nov 19, 2025We investigate the sampling-based optimal path planning problem for robotics in complex and dynamic environments. Most existing sampling-based algorithms neglect environmental information or the information from previous samples. Yet, these pieces of information are highly informative, as leveraging them can provide better heuristics when sampling the next state. In this paper, we propose a novel sampling-based planning algorithm, called \emph{RRT*former}, which integrates the standard RRT* algorithm with a Transformer network in a novel way. Specifically, the Transformer is used to extract features from the environment and leverage information from previous samples to better guide the sampling process. Our extensive experiments demonstrate that, compared to existing sampling-based approaches such as RRT*, Neural RRT*, and their variants, our algorithm achieves considerable improvements in both the optimality of the path and sampling efficiency. The code for our implementation is available on https://github.com/fengmingyang666/RRTformer.
Bridging Perception and Planning: Towards End-to-End Planning for Signal Temporal Logic Tasks
Sep 16, 2025We investigate the task and motion planning problem for Signal Temporal Logic (STL) specifications in robotics. Existing STL methods rely on pre-defined maps or mobility representations, which are ineffective in unstructured real-world environments. We propose the \emph{Structured-MoE STL Planner} (\textbf{S-MSP}), a differentiable framework that maps synchronized multi-view camera observations and an STL specification directly to a feasible trajectory. S-MSP integrates STL constraints within a unified pipeline, trained with a composite loss that combines trajectory reconstruction and STL robustness. A \emph{structure-aware} Mixture-of-Experts (MoE) model enables horizon-aware specialization by projecting sub-tasks into temporally anchored embeddings. We evaluate S-MSP using a high-fidelity simulation of factory-logistics scenarios with temporally constrained tasks. Experiments show that S-MSP outperforms single-expert baselines in STL satisfaction and trajectory feasibility. A rule-based \emph{safety filter} at inference improves physical executability without compromising logical correctness, showcasing the practicality of the approach.
UniTalker: Conversational Speech-Visual Synthesis
Aug 06, 2025Conversational Speech Synthesis (CSS) is a key task in the user-agent interaction area, aiming to generate more expressive and empathetic speech for users. However, it is well-known that "listening" and "eye contact" play crucial roles in conveying emotions during real-world interpersonal communication. Existing CSS research is limited to perceiving only text and speech within the dialogue context, which restricts its effectiveness. Moreover, speech-only responses further constrain the interactive experience. To address these limitations, we introduce a Conversational Speech-Visual Synthesis (CSVS) task as an extension of traditional CSS. By leveraging multimodal dialogue context, it provides users with coherent audiovisual responses. To this end, we develop a CSVS system named UniTalker, which is a unified model that seamlessly integrates multimodal perception and multimodal rendering capabilities. Specifically, it leverages a large-scale language model to comprehensively understand multimodal cues in the dialogue context, including speaker, text, speech, and the talking-face animations. After that, it employs multi-task sequence prediction to first infer the target utterance's emotion and then generate empathetic speech and natural talking-face animations. To ensure that the generated speech-visual content remains consistent in terms of emotion, content, and duration, we introduce three key optimizations: 1) Designing a specialized neural landmark codec to tokenize and reconstruct facial expression sequences. 2) Proposing a bimodal speech-visual hard alignment decoding strategy. 3) Applying emotion-guided rendering during the generation stage. Comprehensive objective and subjective experiments demonstrate that our model synthesizes more empathetic speech and provides users with more natural and emotionally consistent talking-face animations.
Chain-Talker: Chain Understanding and Rendering for Empathetic Conversational Speech Synthesis
May 19, 2025Conversational Speech Synthesis (CSS) aims to align synthesized speech with the emotional and stylistic context of user-agent interactions to achieve empathy. Current generative CSS models face interpretability limitations due to insufficient emotional perception and redundant discrete speech coding. To address the above issues, we present Chain-Talker, a three-stage framework mimicking human cognition: Emotion Understanding derives context-aware emotion descriptors from dialogue history; Semantic Understanding generates compact semantic codes via serialized prediction; and Empathetic Rendering synthesizes expressive speech by integrating both components. To support emotion modeling, we develop CSS-EmCap, an LLM-driven automated pipeline for generating precise conversational speech emotion captions. Experiments on three benchmark datasets demonstrate that Chain-Talker produces more expressive and empathetic speech than existing methods, with CSS-EmCap contributing to reliable emotion modeling. The code and demos are available at: https://github.com/AI-S2-Lab/Chain-Talker.
Online Synthesis of Control Barrier Functions with Local Occupancy Grid Maps for Safe Navigation in Unknown Environments
May 17, 2025Control Barrier Functions (CBFs) have emerged as an effective and non-invasive safety filter for ensuring the safety of autonomous systems in dynamic environments with formal guarantees. However, most existing works on CBF synthesis focus on fully known settings. Synthesizing CBFs online based on perception data in unknown environments poses particular challenges. Specifically, this requires the construction of CBFs from high-dimensional data efficiently in real time. This paper proposes a new approach for online synthesis of CBFs directly from local Occupancy Grid Maps (OGMs). Inspired by steady-state thermal fields, we show that the smoothness requirement of CBFs corresponds to the solution of the steady-state heat conduction equation with suitably chosen boundary conditions. By leveraging the sparsity of the coefficient matrix in Laplace's equation, our approach allows for efficient computation of safety values for each grid cell in the map. Simulation and real-world experiments demonstrate the effectiveness of our approach. Specifically, the results show that our CBFs can be synthesized in an average of milliseconds on a 200 * 200 grid map, highlighting its real-time applicability.
Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
Feb 26, 2025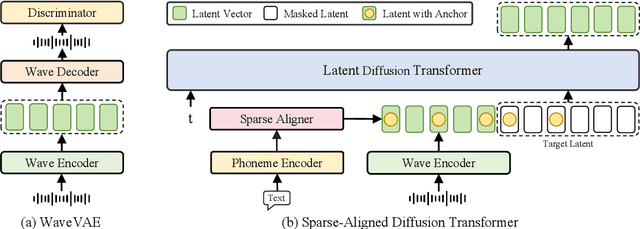
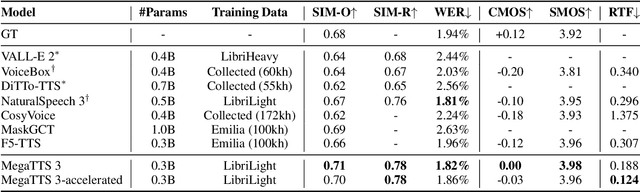
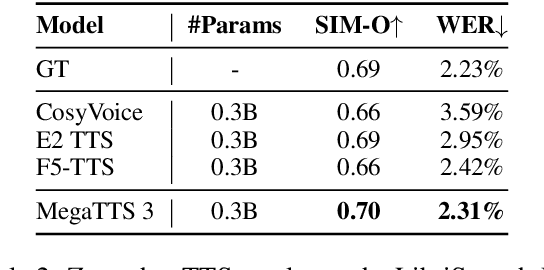

While recent zero-shot text-to-speech (TTS) models have significantly improved speech quality and expressiveness, mainstream systems still suffer from issues related to speech-text alignment modeling: 1) models without explicit speech-text alignment modeling exhibit less robustness, especially for hard sentences in practical applications; 2) predefined alignment-based models suffer from naturalness constraints of forced alignments. This paper introduces \textit{S-DiT}, a TTS system featuring an innovative sparse alignment algorithm that guides the latent diffusion transformer (DiT). Specifically, we provide sparse alignment boundaries to S-DiT to reduce the difficulty of alignment learning without limiting the search space, thereby achieving high naturalness. Moreover, we employ a multi-condition classifier-free guidance strategy for accent intensity adjustment and adopt the piecewise rectified flow technique to accelerate the generation process. Experiments demonstrate that S-DiT achieves state-of-the-art zero-shot TTS speech quality and supports highly flexible control over accent intensity. Notably, our system can generate high-quality one-minute speech with only 8 sampling steps. Audio samples are available at https://sditdemo.github.io/sditdemo/.
HumanDiT: Pose-Guided Diffusion Transformer for Long-form Human Motion Video Generation
Feb 10, 2025



Human motion video generation has advanced significantly, while existing methods still struggle with accurately rendering detailed body parts like hands and faces, especially in long sequences and intricate motions. Current approaches also rely on fixed resolution and struggle to maintain visual consistency. To address these limitations, we propose HumanDiT, a pose-guided Diffusion Transformer (DiT)-based framework trained on a large and wild dataset containing 14,000 hours of high-quality video to produce high-fidelity videos with fine-grained body rendering. Specifically, (i) HumanDiT, built on DiT, supports numerous video resolutions and variable sequence lengths, facilitating learning for long-sequence video generation; (ii) we introduce a prefix-latent reference strategy to maintain personalized characteristics across extended sequences. Furthermore, during inference, HumanDiT leverages Keypoint-DiT to generate subsequent pose sequences, facilitating video continuation from static images or existing videos. It also utilizes a Pose Adapter to enable pose transfer with given sequences. Extensive experiments demonstrate its superior performance in generating long-form, pose-accurate videos across diverse scenarios.
MimicTalk: Mimicking a personalized and expressive 3D talking face in minutes
Oct 09, 2024



Talking face generation (TFG) aims to animate a target identity's face to create realistic talking videos. Personalized TFG is a variant that emphasizes the perceptual identity similarity of the synthesized result (from the perspective of appearance and talking style). While previous works typically solve this problem by learning an individual neural radiance field (NeRF) for each identity to implicitly store its static and dynamic information, we find it inefficient and non-generalized due to the per-identity-per-training framework and the limited training data. To this end, we propose MimicTalk, the first attempt that exploits the rich knowledge from a NeRF-based person-agnostic generic model for improving the efficiency and robustness of personalized TFG. To be specific, (1) we first come up with a person-agnostic 3D TFG model as the base model and propose to adapt it into a specific identity; (2) we propose a static-dynamic-hybrid adaptation pipeline to help the model learn the personalized static appearance and facial dynamic features; (3) To generate the facial motion of the personalized talking style, we propose an in-context stylized audio-to-motion model that mimics the implicit talking style provided in the reference video without information loss by an explicit style representation. The adaptation process to an unseen identity can be performed in 15 minutes, which is 47 times faster than previous person-dependent methods. Experiments show that our MimicTalk surpasses previous baselines regarding video quality, efficiency, and expressiveness. Source code and video samples are available at https://mimictalk.github.io .
Applying Attribution Explanations in Truth-Discovery Quantitative Bipolar Argumentation Frameworks
Sep 09, 2024



Explaining the strength of arguments under gradual semantics is receiving increasing attention. For example, various studies in the literature offer explanations by computing the attribution scores of arguments or edges in Quantitative Bipolar Argumentation Frameworks (QBAFs). These explanations, known as Argument Attribution Explanations (AAEs) and Relation Attribution Explanations (RAEs), commonly employ removal-based and Shapley-based techniques for computing the attribution scores. While AAEs and RAEs have proven useful in several applications with acyclic QBAFs, they remain largely unexplored for cyclic QBAFs. Furthermore, existing applications tend to focus solely on either AAEs or RAEs, but do not compare them directly. In this paper, we apply both AAEs and RAEs, to Truth Discovery QBAFs (TD-QBAFs), which assess the trustworthiness of sources (e.g., websites) and their claims (e.g., the severity of a virus), and feature complex cycles. We find that both AAEs and RAEs can provide interesting explanations and can give non-trivial and surprising insights.
MulliVC: Multi-lingual Voice Conversion With Cycle Consistency
Aug 08, 2024Voice conversion aims to modify the source speaker's voice to resemble the target speaker while preserving the original speech content. Despite notable advancements in voice conversion these days, multi-lingual voice conversion (including both monolingual and cross-lingual scenarios) has yet to be extensively studied. It faces two main challenges: 1) the considerable variability in prosody and articulation habits across languages; and 2) the rarity of paired multi-lingual datasets from the same speaker. In this paper, we propose MulliVC, a novel voice conversion system that only converts timbre and keeps original content and source language prosody without multi-lingual paired data. Specifically, each training step of MulliVC contains three substeps: In step one the model is trained with monolingual speech data; then, steps two and three take inspiration from back translation, construct a cyclical process to disentangle the timbre and other information (content, prosody, and other language-related information) in the absence of multi-lingual data from the same speaker. Both objective and subjective results indicate that MulliVC significantly surpasses other methods in both monolingual and cross-lingual contexts, demonstrating the system's efficacy and the viability of the three-step approach with cycle consistency. Audio samples can be found on our demo page (mullivc.github.io).