 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALIVE: Animate Your World with Lifelike Audio-Video Generation
Feb 09, 2026Video generation is rapidly evolving towards unified audio-video generation. In this paper, we present ALIVE, a generation model that adapts a pretrained Text-to-Video (T2V) model to Sora-style audio-video generation and animation. In particular, the model unlocks the Text-to-Video&Audio (T2VA) and Reference-to-Video&Audio (animation) capabilities compared to the T2V foundation models. To support the audio-visual synchronization and reference animation, we augment the popular MMDiT architecture with a joint audio-video branch which includes TA-CrossAttn for temporally-aligned cross-modal fusion and UniTemp-RoPE for precise audio-visual alignment. Meanwhile, a comprehensive data pipeline consisting of audio-video captioning, quality control, etc., is carefully designed to collect high-quality finetuning data. Additionally, we introduce a new benchmark to perform a comprehensive model test and comparison. After continue pretraining and finetuning on million-level high-quality data, ALIVE demonstrates outstanding performance, consistently outperforming open-source models and matching or surpassing state-of-the-art commercial solutions. With detailed recipes and benchmarks, we hope ALIVE helps the community develop audio-video generation models more efficiently. Official page: https://github.com/FoundationVision/Alive.
InfinityStar: Unified Spacetime AutoRegressive Modeling for Visual Generation
Nov 06, 2025We introduce InfinityStar, a unified spacetime autoregressive framework for high-resolution image and dynamic video synthesis. Building on the recent success of autoregressive modeling in both vision and language, our purely discrete approach jointly captures spatial and temporal dependencies within a single architecture. This unified design naturally supports a variety of generation tasks such as text-to-image, text-to-video, image-to-video, and long interactive video synthesis via straightforward temporal autoregression. Extensive experiments demonstrate that InfinityStar scores 83.74 on VBench, outperforming all autoregressive models by large margins, even surpassing some diffusion competitors like HunyuanVideo. Without extra optimizations, our model generates a 5s, 720p video approximately 10x faster than leading diffusion-based methods. To our knowledge, InfinityStar is the first discrete autoregressive video generator capable of producing industrial level 720p videos. We release all code and models to foster further research in efficient, high-quality video generation.
HLLM-Creator: Hierarchical LLM-based Personalized Creative Generation
Aug 25, 2025AI-generated content technologies are widely used in content creation. However, current AIGC systems rely heavily on creators' inspiration, rarely generating truly user-personalized content. In real-world applications such as online advertising, a single product may have multiple selling points, with different users focusing on different features. This underscores the significant value of personalized, user-centric creative generation. Effective personalized content generation faces two main challenges: (1) accurately modeling user interests and integrating them into the content generation process while adhering to factual constraints, and (2) ensuring high efficiency and scalability to handle the massive user base in industrial scenarios. Additionally, the scarcity of personalized creative data in practice complicates model training, making data construction another key hurdle. We propose HLLM-Creator, a hierarchical LLM framework for efficient user interest modeling and personalized content generation. During inference, a combination of user clustering and a user-ad-matching-prediction based pruning strategy is employed to significantly enhance generation efficiency and reduce computational overhead, making the approach suitable for large-scale deployment. Moreover, we design a data construction pipeline based on chain-of-thought reasoning, which generates high-quality, user-specific creative titles and ensures factual consistency despite limited personalized data. This pipeline serves as a critical foundation for the effectiveness of our model. Extensive experiments on personalized title generation for Douyin Search Ads show the effectiveness of HLLM-Creator. Online A/B test shows a 0.476% increase on Adss, paving the way for more effective and efficient personalized generation in industrial scenarios. Codes for academic dataset are available at https://github.com/bytedance/HLLM.
VC-LLM: Automated Advertisement Video Creation from Raw Footage using Multi-modal LLMs
Apr 08, 2025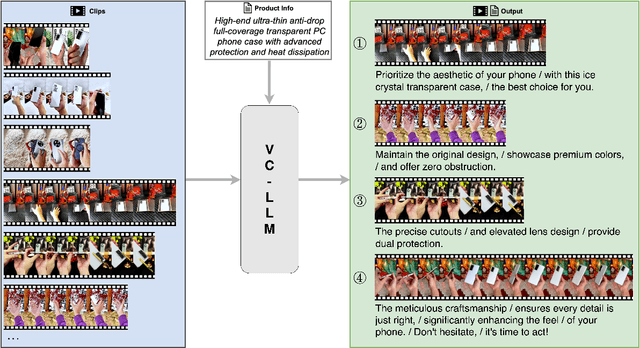
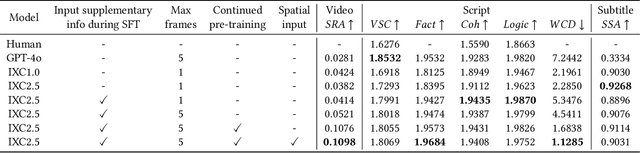
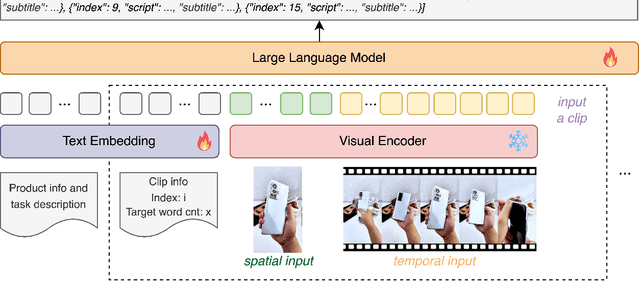

As short videos have risen in popularity, the role of video content in advertising has become increasingly significant. Typically, advertisers record a large amount of raw footage about the product and then create numerous different short-form advertisement videos based on this raw footage. Creating such videos mainly involves editing raw footage and writing advertisement scripts, which requires a certain level of creative ability. It is usually challenging to create many different video contents for the same product, and manual efficiency is often low. In this paper, we present VC-LLM, a framework powered by Large Language Models for the automatic creation of high-quality short-form advertisement videos. Our approach leverages high-resolution spatial input and low-resolution temporal input to represent video clips more effectively, capturing both fine-grained visual details and broader temporal dynamics. In addition, during training, we incorporate supplementary information generated by rewriting the ground truth text, ensuring that all key output information can be directly traced back to the input, thereby reducing model hallucinations. We also designed a benchmark to evaluate the quality of the created videos. Experiments show that VC-LLM based on GPT-4o can produce videos comparable to those created by humans. Furthermore, we collected numerous high-quality short advertisement videos to create a pre-training dataset and manually cleaned a portion of the data to construct a high-quality fine-tuning dataset. Experiments indicate that, on the benchmark, the VC-LLM based on fine-tuned LLM can produce videos with superior narrative logic compared to those created by the VC-LLM based on GPT-4o.
UniTok: A Unified Tokenizer for Visual Generation and Understanding
Feb 27, 2025



The representation disparity between visual generation and understanding imposes a critical gap in integrating these capabilities into a single framework. To bridge this gap, we introduce UniTok, a discrete visual tokenizer that encodes fine-grained details for generation while also capturing high-level semantics for understanding. Despite recent studies have shown that these objectives could induce loss conflicts in training, we reveal that the underlying bottleneck stems from limited representational capacity of discrete tokens. We address this by introducing multi-codebook quantization, which divides vector quantization with several independent sub-codebooks to expand the latent feature space, while avoiding training instability caused by overlarge codebooks. Our method significantly raises the upper limit of unified discrete tokenizers to match or even surpass domain-specific continuous tokenizers. For instance, UniTok achieves a remarkable rFID of 0.38 (versus 0.87 for SD-VAE) and a zero-shot accuracy of 78.6% (versus 76.2% for CLIP) on ImageNet. Our code is available at https://github.com/FoundationVision/UniTok.
HumanDiT: Pose-Guided Diffusion Transformer for Long-form Human Motion Video Generation
Feb 10, 2025



Human motion video generation has advanced significantly, while existing methods still struggle with accurately rendering detailed body parts like hands and faces, especially in long sequences and intricate motions. Current approaches also rely on fixed resolution and struggle to maintain visual consistency. To address these limitations, we propose HumanDiT, a pose-guided Diffusion Transformer (DiT)-based framework trained on a large and wild dataset containing 14,000 hours of high-quality video to produce high-fidelity videos with fine-grained body rendering. Specifically, (i) HumanDiT, built on DiT, supports numerous video resolutions and variable sequence lengths, facilitating learning for long-sequence video generation; (ii) we introduce a prefix-latent reference strategy to maintain personalized characteristics across extended sequences. Furthermore, during inference, HumanDiT leverages Keypoint-DiT to generate subsequent pose sequences, facilitating video continuation from static images or existing videos. It also utilizes a Pose Adapter to enable pose transfer with given sequences. Extensive experiments demonstrate its superior performance in generating long-form, pose-accurate videos across diverse scenarios.
Goku: Flow Based Video Generative Foundation Models
Feb 10, 2025



This paper introduces Goku, a state-of-the-art family of joint image-and-video generation models leveraging rectified flow Transformers to achieve industry-leading performance. We detail the foundational elements enabling high-quality visual generation, including the data curation pipeline, model architecture design, flow formulation, and advanced infrastructure for efficient and robust large-scale training. The Goku models demonstrate superior performance in both qualitative and quantitative evaluations, setting new benchmarks across major tasks. Specifically, Goku achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks. We believe that this work provides valuable insights and practical advancements for the research community in developing joint image-and-video generation models.
Text-to-Edit: Controllable End-to-End Video Ad Creation via Multimodal LLMs
Jan 10, 2025



The exponential growth of short-video content has ignited a surge in the necessity for efficient, automated solutions to video editing, with challenges arising from the need to understand videos and tailor the editing according to user requirements. Addressing this need, we propose an innovative end-to-end foundational framework, ultimately actualizing precise control over the final video content editing. Leveraging the flexibility and generalizability of Multimodal Large Language Models (MLLMs), we defined clear input-output mappings for efficient video creation. To bolster the model's capability in processing and comprehending video content, we introduce a strategic combination of a denser frame rate and a slow-fast processing technique, significantly enhancing the extraction and understanding of both temporal and spatial video information. Furthermore, we introduce a text-to-edit mechanism that allows users to achieve desired video outcomes through textual input, thereby enhancing the quality and controllability of the edited videos. Through comprehensive experimentation, our method has not only showcased significant effectiveness within advertising datasets, but also yields universally applicable conclusions on public datasets.
LatentSync: Audio Conditioned Latent Diffusion Models for Lip Sync
Dec 12, 2024We present LatentSync, an end-to-end lip sync framework based on audio conditioned latent diffusion models without any intermediate motion representation, diverging from previous diffusion-based lip sync methods based on pixel space diffusion or two-stage generation. Our framework can leverage the powerful capabilities of Stable Diffusion to directly model complex audio-visual correlations. Additionally, we found that the diffusion-based lip sync methods exhibit inferior temporal consistency due to the inconsistency in the diffusion process across different frames. We propose Temporal REPresentation Alignment (TREPA) to enhance temporal consistency while preserving lip-sync accuracy. TREPA uses temporal representations extracted by large-scale self-supervised video models to align the generated frames with the ground truth frames. Furthermore, we observe the commonly encountered SyncNet convergence issue and conduct comprehensive empirical studies, identifying key factors affecting SyncNet convergence in terms of model architecture, training hyperparameters, and data preprocessing methods. We significantly improve the accuracy of SyncNet from 91% to 94% on the HDTF test set. Since we did not change the overall training framework of SyncNet, our experience can also be applied to other lip sync and audio-driven portrait animation methods that utilize SyncNet. Based on the above innovations, our method outperforms state-of-the-art lip sync methods across various metrics on the HDTF and VoxCeleb2 datasets.
Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis
Dec 05, 2024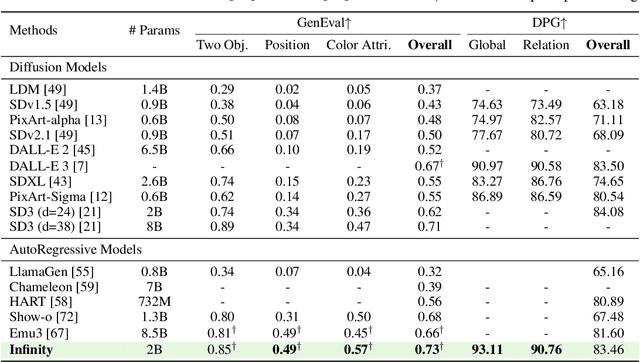

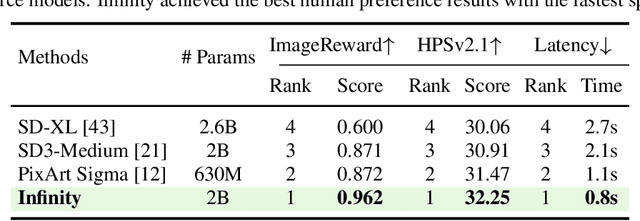

We present Infinity, a Bitwise Visual AutoRegressive Modeling capable of generating high-resolution, photorealistic images following language instruction. Infinity redefines visual autoregressive model under a bitwise token prediction framework with an infinite-vocabulary tokenizer & classifier and bitwise self-correction mechanism, remarkably improving the generation capacity and details. By theoretically scaling the tokenizer vocabulary size to infinity and concurrently scaling the transformer size, our method significantly unleashes powerful scaling capabilities compared to vanilla VAR. Infinity sets a new record for autoregressive text-to-image models, outperforming top-tier diffusion models like SD3-Medium and SDXL. Notably, Infinity surpasses SD3-Medium by improving the GenEval benchmark score from 0.62 to 0.73 and the ImageReward benchmark score from 0.87 to 0.96, achieving a win rate of 66%. Without extra optimization, Infinity generates a high-quality 1024x1024 image in 0.8 seconds, making it 2.6x faster than SD3-Medium and establishing it as the fastest text-to-image model. Models and codes will be released to promote further exploration of Infinity for visual generation and unified tokenizer modeling.