 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVC-LLM: Automated Advertisement Video Creation from Raw Footage using Multi-modal LLMs
Apr 08, 2025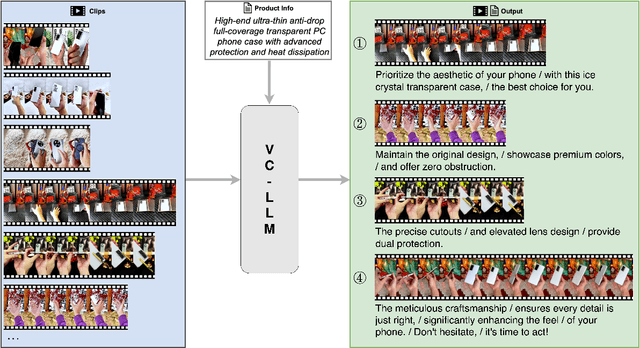
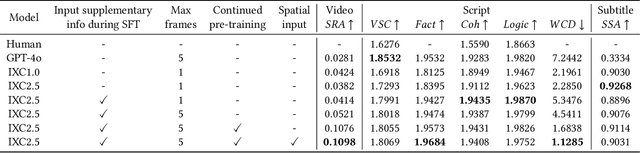
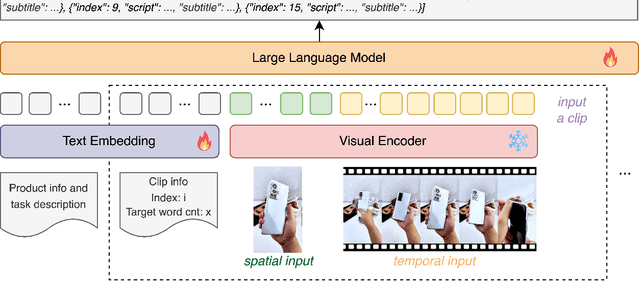

As short videos have risen in popularity, the role of video content in advertising has become increasingly significant. Typically, advertisers record a large amount of raw footage about the product and then create numerous different short-form advertisement videos based on this raw footage. Creating such videos mainly involves editing raw footage and writing advertisement scripts, which requires a certain level of creative ability. It is usually challenging to create many different video contents for the same product, and manual efficiency is often low. In this paper, we present VC-LLM, a framework powered by Large Language Models for the automatic creation of high-quality short-form advertisement videos. Our approach leverages high-resolution spatial input and low-resolution temporal input to represent video clips more effectively, capturing both fine-grained visual details and broader temporal dynamics. In addition, during training, we incorporate supplementary information generated by rewriting the ground truth text, ensuring that all key output information can be directly traced back to the input, thereby reducing model hallucinations. We also designed a benchmark to evaluate the quality of the created videos. Experiments show that VC-LLM based on GPT-4o can produce videos comparable to those created by humans. Furthermore, we collected numerous high-quality short advertisement videos to create a pre-training dataset and manually cleaned a portion of the data to construct a high-quality fine-tuning dataset. Experiments indicate that, on the benchmark, the VC-LLM based on fine-tuned LLM can produce videos with superior narrative logic compared to those created by the VC-LLM based on GPT-4o.
Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
Jan 10, 2023



We identify and overcome two key obstacles in extending the success of BERT-style pre-training, or the masked image modeling, to convolutional networks (convnets): (i) convolution operation cannot handle irregular, random-masked input images; (ii) the single-scale nature of BERT pre-training is inconsistent with convnet's hierarchical structure. For (i), we treat unmasked pixels as sparse voxels of 3D point clouds and use sparse convolution to encode. This is the first use of sparse convolution for 2D masked modeling. For (ii), we develop a hierarchical decoder to reconstruct images from multi-scale encoded features. Our method called Sparse masKed modeling (SparK) is general: it can be used directly on any convolutional model without backbone modifications. We validate it on both classical (ResNet) and modern (ConvNeXt) models: on three downstream tasks, it surpasses both state-of-the-art contrastive learning and transformer-based masked modeling by similarly large margins (around +1.0%). Improvements on object detection and instance segmentation are more substantial (up to +3.5%), verifying the strong transferability of features learned. We also find its favorable scaling behavior by observing more gains on larger models. All this evidence reveals a promising future of generative pre-training on convnets. Codes and models are released at https://github.com/keyu-tian/SparK.
MetaFormer: A Unified Meta Framework for Fine-Grained Recognition
Mar 05, 2022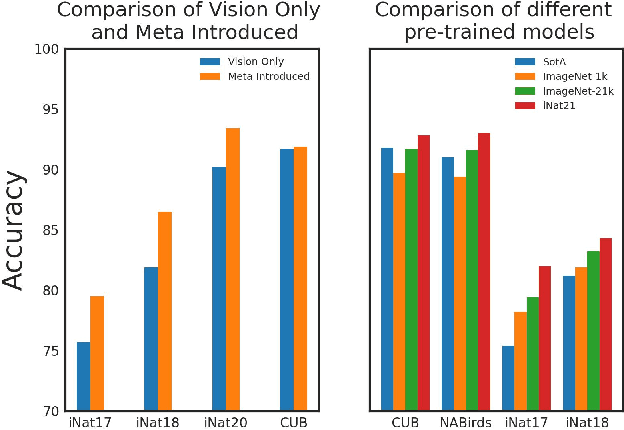
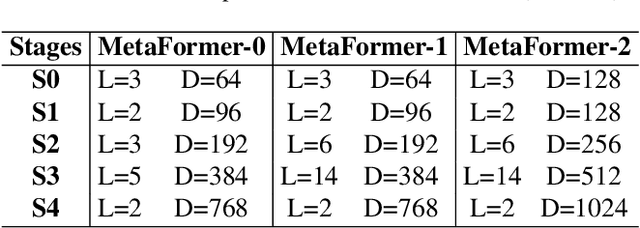


Fine-Grained Visual Classification(FGVC) is the task that requires recognizing the objects belonging to multiple subordinate categories of a super-category. Recent state-of-the-art methods usually design sophisticated learning pipelines to tackle this task. However, visual information alone is often not sufficient to accurately differentiate between fine-grained visual categories. Nowadays, the meta-information (e.g., spatio-temporal prior, attribute, and text description) usually appears along with the images. This inspires us to ask the question: Is it possible to use a unified and simple framework to utilize various meta-information to assist in fine-grained identification? To answer this problem, we explore a unified and strong meta-framework(MetaFormer) for fine-grained visual classification. In practice, MetaFormer provides a simple yet effective approach to address the joint learning of vision and various meta-information. Moreover, MetaFormer also provides a strong baseline for FGVC without bells and whistles. Extensive experiments demonstrate that MetaFormer can effectively use various meta-information to improve the performance of fine-grained recognition. In a fair comparison, MetaFormer can outperform the current SotA approaches with only vision information on the iNaturalist2017 and iNaturalist2018 datasets. Adding meta-information, MetaFormer can exceed the current SotA approaches by 5.9% and 5.3%, respectively. Moreover, MetaFormer can achieve 92.3% and 92.7% on CUB-200-2011 and NABirds, which significantly outperforms the SotA approaches. The source code and pre-trained models are released athttps://github.com/dqshuai/MetaFormer.