 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVC-LLM: Automated Advertisement Video Creation from Raw Footage using Multi-modal LLMs
Apr 08, 2025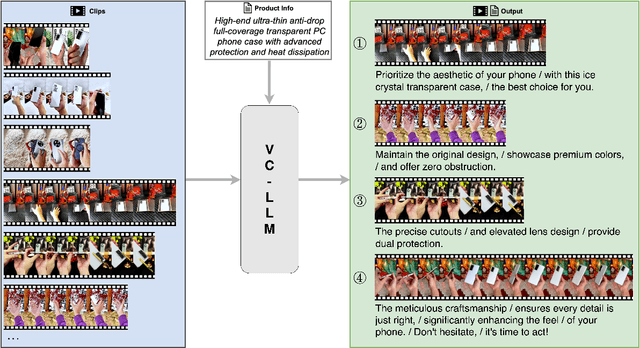
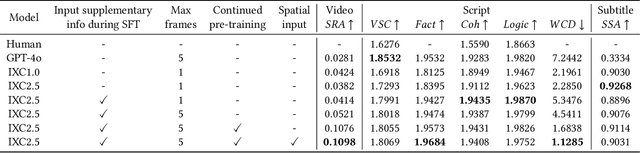
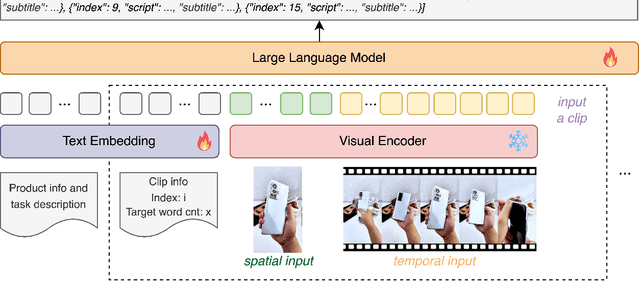

As short videos have risen in popularity, the role of video content in advertising has become increasingly significant. Typically, advertisers record a large amount of raw footage about the product and then create numerous different short-form advertisement videos based on this raw footage. Creating such videos mainly involves editing raw footage and writing advertisement scripts, which requires a certain level of creative ability. It is usually challenging to create many different video contents for the same product, and manual efficiency is often low. In this paper, we present VC-LLM, a framework powered by Large Language Models for the automatic creation of high-quality short-form advertisement videos. Our approach leverages high-resolution spatial input and low-resolution temporal input to represent video clips more effectively, capturing both fine-grained visual details and broader temporal dynamics. In addition, during training, we incorporate supplementary information generated by rewriting the ground truth text, ensuring that all key output information can be directly traced back to the input, thereby reducing model hallucinations. We also designed a benchmark to evaluate the quality of the created videos. Experiments show that VC-LLM based on GPT-4o can produce videos comparable to those created by humans. Furthermore, we collected numerous high-quality short advertisement videos to create a pre-training dataset and manually cleaned a portion of the data to construct a high-quality fine-tuning dataset. Experiments indicate that, on the benchmark, the VC-LLM based on fine-tuned LLM can produce videos with superior narrative logic compared to those created by the VC-LLM based on GPT-4o.
Incorporating Domain Knowledge Graph into Multimodal Movie Genre Classification with Self-Supervised Attention and Contrastive Learning
Oct 12, 2023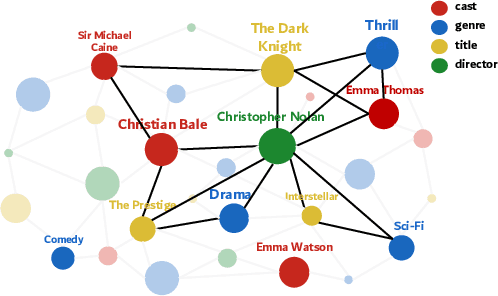
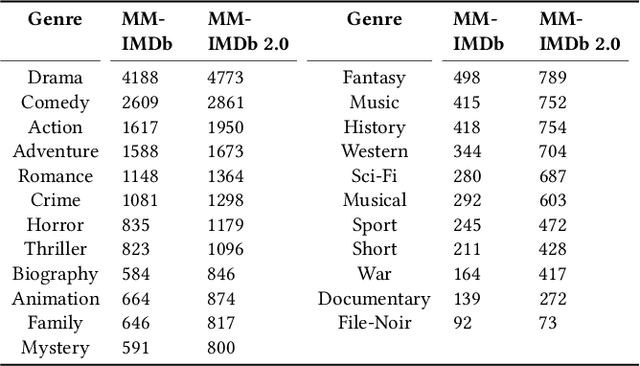
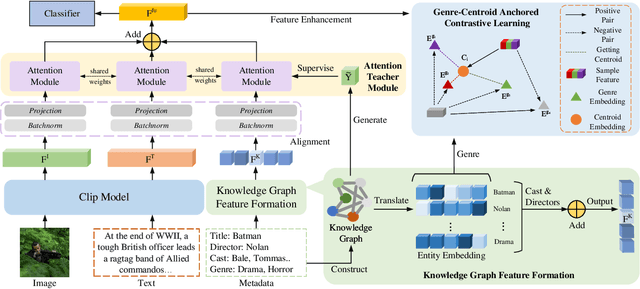
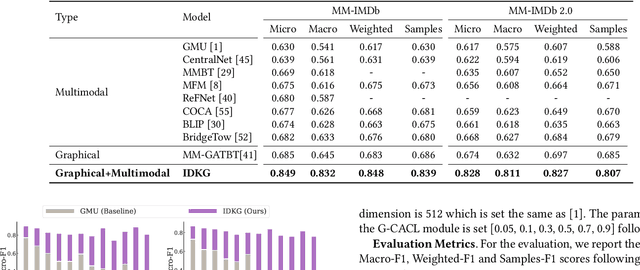
Multimodal movie genre classification has always been regarded as a demanding multi-label classification task due to the diversity of multimodal data such as posters, plot summaries, trailers and metadata. Although existing works have made great progress in modeling and combining each modality, they still face three issues: 1) unutilized group relations in metadata, 2) unreliable attention allocation, and 3) indiscriminative fused features. Given that the knowledge graph has been proven to contain rich information, we present a novel framework that exploits the knowledge graph from various perspectives to address the above problems. As a preparation, the metadata is processed into a domain knowledge graph. A translate model for knowledge graph embedding is adopted to capture the relations between entities. Firstly we retrieve the relevant embedding from the knowledge graph by utilizing group relations in metadata and then integrate it with other modalities. Next, we introduce an Attention Teacher module for reliable attention allocation based on self-supervised learning. It learns the distribution of the knowledge graph and produces rational attention weights. Finally, a Genre-Centroid Anchored Contrastive Learning module is proposed to strengthen the discriminative ability of fused features. The embedding space of anchors is initialized from the genre entities in the knowledge graph. To verify the effectiveness of our framework, we collect a larger and more challenging dataset named MM-IMDb 2.0 compared with the MM-IMDb dataset. The experimental results on two datasets demonstrate that our model is superior to the state-of-the-art methods. We will release the code in the near future.
Evaluation of ChatGPT as a Question Answering System for Answering Complex Questions
Mar 14, 2023ChatGPT is a powerful large language model (LLM) that has made remarkable progress in natural language understanding. Nevertheless, the performance and limitations of the model still need to be extensively evaluated. As ChatGPT covers resources such as Wikipedia and supports natural language question answering, it has garnered attention as a potential replacement for traditional knowledge based question answering (KBQA) models. Complex question answering is a challenge task of KBQA, which comprehensively tests the ability of models in semantic parsing and reasoning. To assess the performance of ChatGPT as a question answering system (QAS) using its own knowledge, we present a framework that evaluates its ability to answer complex questions. Our approach involves categorizing the potential features of complex questions and describing each test question with multiple labels to identify combinatorial reasoning. Following the black-box testing specifications of CheckList proposed by Ribeiro et.al, we develop an evaluation method to measure the functionality and reliability of ChatGPT in reasoning for answering complex questions. We use the proposed framework to evaluate the performance of ChatGPT in question answering on 8 real-world KB-based CQA datasets, including 6 English and 2 multilingual datasets, with a total of approximately 190,000 test cases. We compare the evaluation results of ChatGPT, GPT-3.5, GPT-3, and FLAN-T5 to identify common long-term problems in LLMs. The dataset and code are available at https://github.com/tan92hl/Complex-Question-Answering-Evaluation-of-ChatGPT.