 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangle Object and Non-object Infrared Features via Language Guidance
Jan 14, 2026Infrared object detection focuses on identifying and locating objects in complex environments (\eg, dark, snow, and rain) where visible imaging cameras are disabled by poor illumination. However, due to low contrast and weak edge information in infrared images, it is challenging to extract discriminative object features for robust detection. To deal with this issue, we propose a novel vision-language representation learning paradigm for infrared object detection. An additional textual supervision with rich semantic information is explored to guide the disentanglement of object and non-object features. Specifically, we propose a Semantic Feature Alignment (SFA) module to align the object features with the corresponding text features. Furthermore, we develop an Object Feature Disentanglement (OFD) module that disentangles text-aligned object features and non-object features by minimizing their correlation. Finally, the disentangled object features are entered into the detection head. In this manner, the detection performance can be remarkably enhanced via more discriminative and less noisy features. Extensive experimental results demonstrate that our approach achieves superior performance on two benchmarks: M\textsuperscript{3}FD (83.7\% mAP), FLIR (86.1\% mAP). Our code will be publicly available once the paper is accepted.
Chain-of-Talkers (CoTalk): Fast Human Annotation of Dense Image Captions
May 28, 2025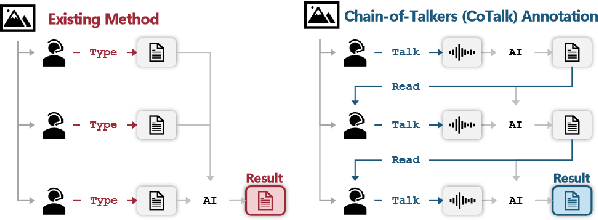

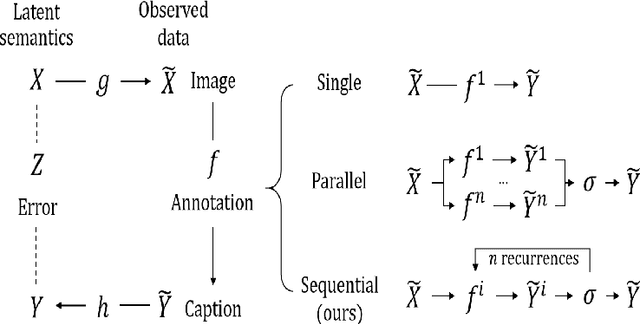
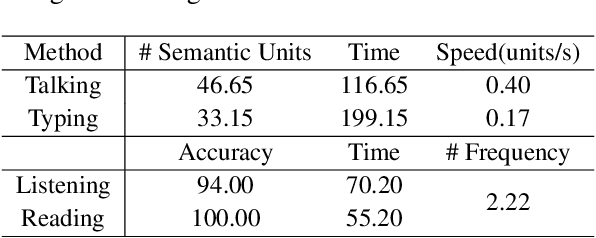
While densely annotated image captions significantly facilitate the learning of robust vision-language alignment, methodologies for systematically optimizing human annotation efforts remain underexplored. We introduce Chain-of-Talkers (CoTalk), an AI-in-the-loop methodology designed to maximize the number of annotated samples and improve their comprehensiveness under fixed budget constraints (e.g., total human annotation time). The framework is built upon two key insights. First, sequential annotation reduces redundant workload compared to conventional parallel annotation, as subsequent annotators only need to annotate the ``residual'' -- the missing visual information that previous annotations have not covered. Second, humans process textual input faster by reading while outputting annotations with much higher throughput via talking; thus a multimodal interface enables optimized efficiency. We evaluate our framework from two aspects: intrinsic evaluations that assess the comprehensiveness of semantic units, obtained by parsing detailed captions into object-attribute trees and analyzing their effective connections; extrinsic evaluation measures the practical usage of the annotated captions in facilitating vision-language alignment. Experiments with eight participants show our Chain-of-Talkers (CoTalk) improves annotation speed (0.42 vs. 0.30 units/sec) and retrieval performance (41.13\% vs. 40.52\%) over the parallel method.
RemoteSAM: Towards Segment Anything for Earth Observation
May 23, 2025
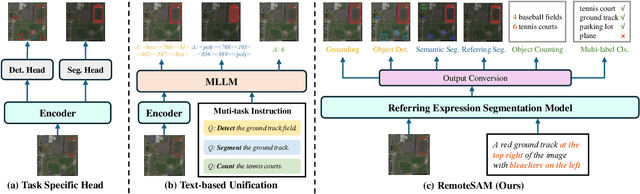
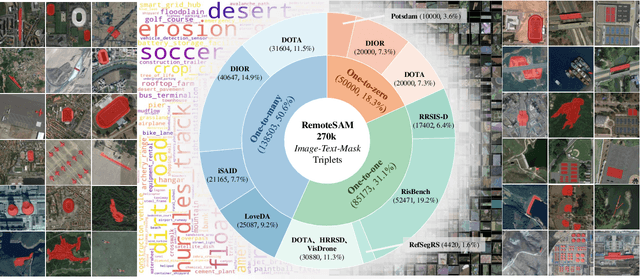
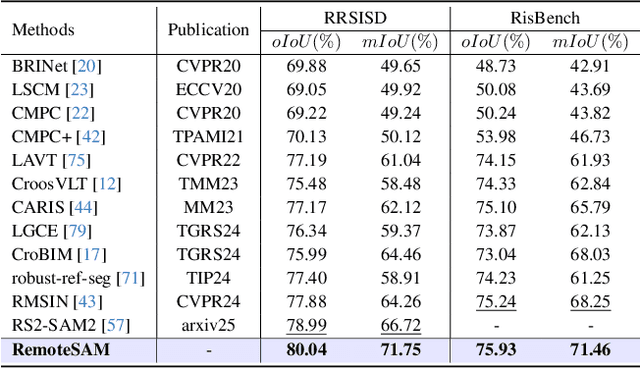
We aim to develop a robust yet flexible visual foundation model for Earth observation. It should possess strong capabilities in recognizing and localizing diverse visual targets while providing compatibility with various input-output interfaces required across different task scenarios. Current systems cannot meet these requirements, as they typically utilize task-specific architecture trained on narrow data domains with limited semantic coverage. Our study addresses these limitations from two aspects: data and modeling. We first introduce an automatic data engine that enjoys significantly better scalability compared to previous human annotation or rule-based approaches. It has enabled us to create the largest dataset of its kind to date, comprising 270K image-text-mask triplets covering an unprecedented range of diverse semantic categories and attribute specifications. Based on this data foundation, we further propose a task unification paradigm that centers around referring expression segmentation. It effectively handles a wide range of vision-centric perception tasks, including classification, detection, segmentation, grounding, etc, using a single model without any task-specific heads. Combining these innovations on data and modeling, we present RemoteSAM, a foundation model that establishes new SoTA on several earth observation perception benchmarks, outperforming other foundation models such as Falcon, GeoChat, and LHRS-Bot with significantly higher efficiency. Models and data are publicly available at https://github.com/1e12Leon/RemoteSAM.
RemoteTrimmer: Adaptive Structural Pruning for Remote Sensing Image Classification
Dec 17, 2024
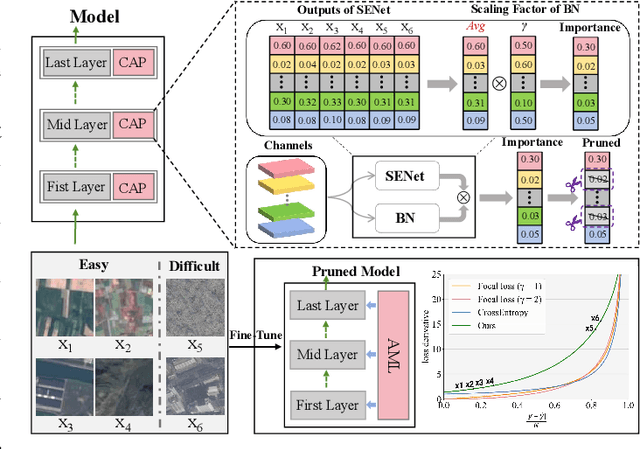
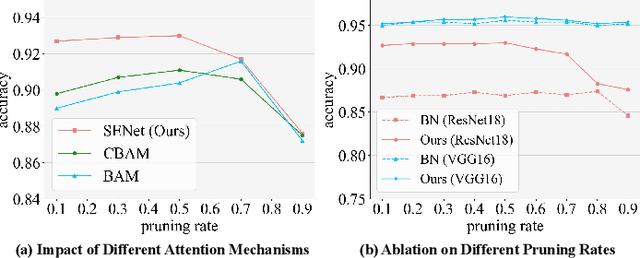
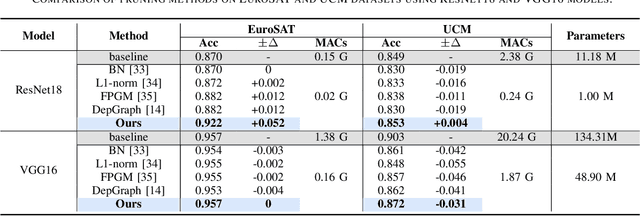
Since high resolution remote sensing image classification often requires a relatively high computation complexity, lightweight models tend to be practical and efficient. Model pruning is an effective method for model compression. However, existing methods rarely take into account the specificity of remote sensing images, resulting in significant accuracy loss after pruning. To this end, we propose an effective structural pruning approach for remote sensing image classification. Specifically, a pruning strategy that amplifies the differences in channel importance of the model is introduced. Then an adaptive mining loss function is designed for the fine-tuning process of the pruned model. Finally, we conducted experiments on two remote sensing classification datasets. The experimental results demonstrate that our method achieves minimal accuracy loss after compressing remote sensing classification models, achieving state-of-the-art (SoTA) performance.
Robust Noisy Correspondence Learning via Self-Drop and Dual-Weight
Dec 09, 2024



Many researchers collect data from the internet through crowd-sourcing or web crawling to alleviate the data-hungry challenge associated with cross-modal matching. Although such practice does not require expensive annotations, it inevitably introduces mismatched pairs and results in a noisy correspondence problem. Current approaches leverage the memorization effect of deep neural networks to distinguish noise and perform re-weighting. However, briefly lowering the weight of noisy pairs cannot eliminate the negative impact of noisy correspondence in the training process. In this paper, we propose a novel self-drop and dual-weight approach, which achieves elaborate data processing by qua-partitioning the data. Specifically, our approach partitions all data into four types: clean and significant, clean yet insignificant, vague, and noisy. We analyze the effect of noisy and clean data pairs and find that for vision-language pre-training models, a small number of clean samples is more valuable than a majority of noisy ones. Based on this observation, we employ self-drop to discard noisy samples to effectively mitigate the impact of noise. In addition, we adopt a dual-weight strategy to ensure that the model focuses more on significant samples while appropriately leveraging vague samples. Compared to the prior works, our approach is more robust and demonstrates relatively more stable performance on noisy datasets, especially under a high noise ratio. Extensive experiments on three widely used datasets, including Flickr30K, MS-COCO, and Conceptual Captions, validate the effectiveness of our approach. The source code is available at https://github.com/DongChenwei2000/SDD.
Prompting DirectSAM for Semantic Contour Extraction in Remote Sensing Images
Oct 08, 2024
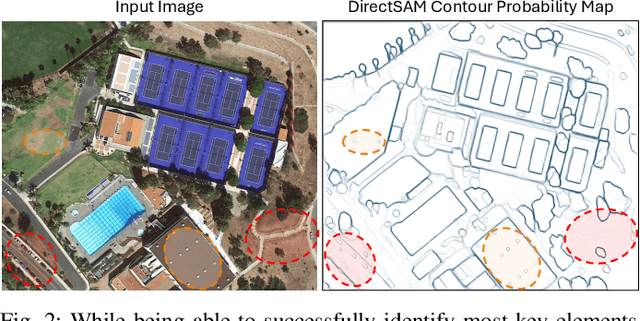


The Direct Segment Anything Model (DirectSAM) excels in class-agnostic contour extraction. In this paper, we explore its use by applying it to optical remote sensing imagery, where semantic contour extraction-such as identifying buildings, road networks, and coastlines-holds significant practical value. Those applications are currently handled via training specialized small models separately on small datasets in each domain. We introduce a foundation model derived from DirectSAM, termed DirectSAM-RS, which not only inherits the strong segmentation capability acquired from natural images, but also benefits from a large-scale dataset we created for remote sensing semantic contour extraction. This dataset comprises over 34k image-text-contour triplets, making it at least 30 times larger than individual dataset. DirectSAM-RS integrates a prompter module: a text encoder and cross-attention layers attached to the DirectSAM architecture, which allows flexible conditioning on target class labels or referring expressions. We evaluate the DirectSAM-RS in both zero-shot and fine-tuning setting, and demonstrate that it achieves state-of-the-art performance across several downstream benchmarks.
Domain-invariant Progressive Knowledge Distillation for UAV-based Object Detection
Aug 21, 2024
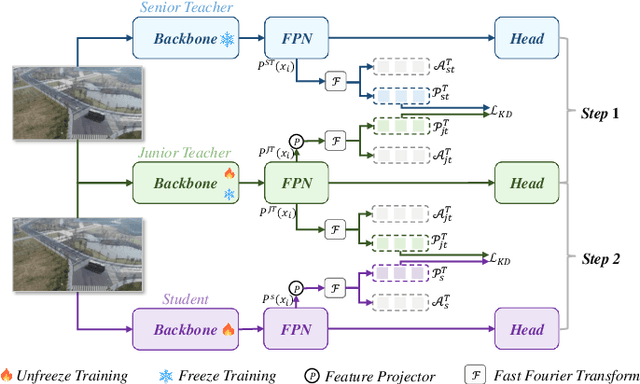
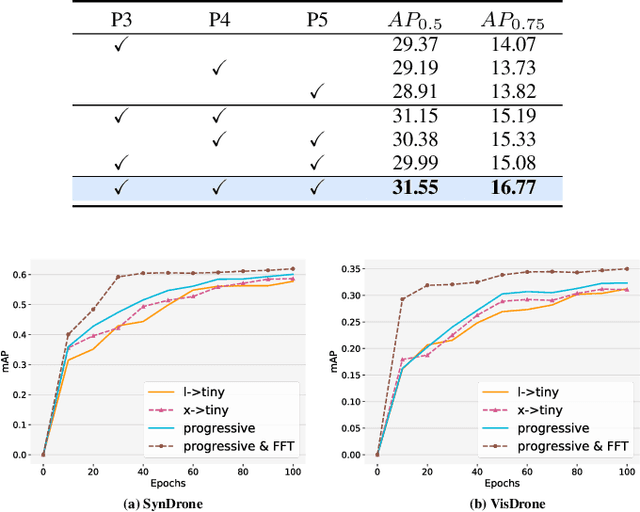
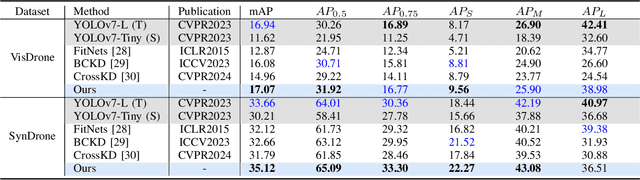
Knowledge distillation (KD) is an effective method for compressing models in object detection tasks. Due to limited computational capability, UAV-based object detection (UAV-OD) widely adopt the KD technique to obtain lightweight detectors. Existing methods often overlook the significant differences in feature space caused by the large gap in scale between the teacher and student models. This limitation hampers the efficiency of knowledge transfer during the distillation process. Furthermore, the complex backgrounds in UAV images make it challenging for the student model to efficiently learn the object features. In this paper, we propose a novel knowledge distillation framework for UAV-OD. Specifically, a progressive distillation approach is designed to alleviate the feature gap between teacher and student models. Then a new feature alignment method is provided to extract object-related features for enhancing student model's knowledge reception efficiency. Finally, extensive experiments are conducted to validate the effectiveness of our proposed approach. The results demonstrate that our proposed method achieves state-of-the-art (SoTA) performance in two UAV-OD datasets.
Making Large Vision Language Models to be Good Few-shot Learners
Aug 21, 2024



Few-shot classification (FSC) is a fundamental yet challenging task in computer vision that involves recognizing novel classes from limited data. While previous methods have focused on enhancing visual features or incorporating additional modalities, Large Vision Language Models (LVLMs) offer a promising alternative due to their rich knowledge and strong visual perception. However, LVLMs risk learning specific response formats rather than effectively extracting useful information from support data in FSC tasks. In this paper, we investigate LVLMs' performance in FSC and identify key issues such as insufficient learning and the presence of severe positional biases. To tackle the above challenges, we adopt the meta-learning strategy to teach models "learn to learn". By constructing a rich set of meta-tasks for instruction fine-tuning, LVLMs enhance the ability to extract information from few-shot support data for classification. Additionally, we further boost LVLM's few-shot learning capabilities through label augmentation and candidate selection in the fine-tuning and inference stage, respectively. Label augmentation is implemented via a character perturbation strategy to ensure the model focuses on support information. Candidate selection leverages attribute descriptions to filter out unreliable candidates and simplify the task. Extensive experiments demonstrate that our approach achieves superior performance on both general and fine-grained datasets. Furthermore, our candidate selection strategy has been proven beneficial for training-free LVLMs.
UEMM-Air: A Synthetic Multi-modal Dataset for Unmanned Aerial Vehicle Object Detection
Jun 10, 2024



The development of multi-modal object detection for Unmanned Aerial Vehicles (UAVs) typically relies on a large amount of pixel-aligned multi-modal image data. However, existing datasets face challenges such as limited modalities, high construction costs, and imprecise annotations. To this end, we propose a synthetic multi-modal UAV-based object detection dataset, UEMM-Air. Specially, we simulate various UAV flight scenarios and object types using the Unreal Engine (UE). Then we design the UAV's flight logic to automatically collect data from different scenarios, perspectives, and altitudes. Finally, we propose a novel heuristic automatic annotation algorithm to generate accurate object detection labels. In total, our UEMM-Air consists of 20k pairs of images with 5 modalities and precise annotations. Moreover, we conduct numerous experiments and establish new benchmark results on our dataset. We found that models pre-trained on UEMM-Air exhibit better performance on downstream tasks compared to other similar datasets. The dataset is publicly available (https://github.com/1e12Leon/UEMM-Air) to support the research of multi-modal UAV object detection models.
Scale-Invariant Feature Disentanglement via Adversarial Learning for UAV-based Object Detection
May 24, 2024
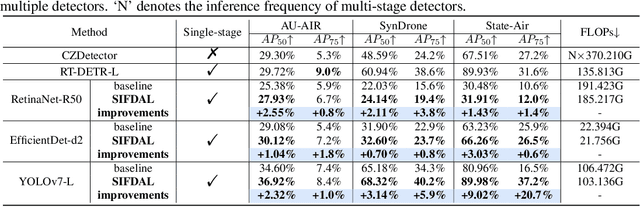
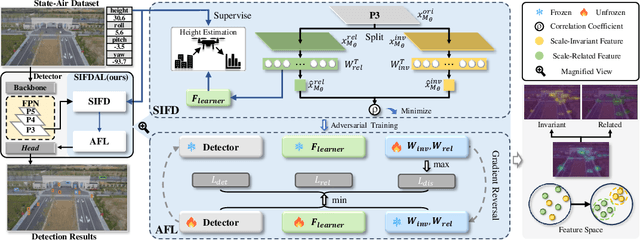

Detecting objects from Unmanned Aerial Vehicles (UAV) is often hindered by a large number of small objects, resulting in low detection accuracy. To address this issue, mainstream approaches typically utilize multi-stage inferences. Despite their remarkable detecting accuracies, real-time efficiency is sacrificed, making them less practical to handle real applications. To this end, we propose to improve the single-stage inference accuracy through learning scale-invariant features. Specifically, a Scale-Invariant Feature Disentangling module is designed to disentangle scale-related and scale-invariant features. Then an Adversarial Feature Learning scheme is employed to enhance disentanglement. Finally, scale-invariant features are leveraged for robust UAV-based object detection. Furthermore, we construct a multi-modal UAV object detection dataset, State-Air, which incorporates annotated UAV state parameters. We apply our approach to three state-of-the-art lightweight detection frameworks on three benchmark datasets, including State-Air. Extensive experiments demonstrate that our approach can effectively improve model accuracy. Our code and dataset are provided in Supplementary Materials and will be publicly available once the paper is accepted.