 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAMR: Geometric-Aware Manifold Regularization with Virtual Outlier Synthesis for Learning with Noisy Labels
May 20, 2026Deep neural networks (DNNs) experience significant performance degradation when processing noisy labels, primarily due to overfitting on mislabeled data. Current mainstream approaches attempt to mitigate this issue by passively filtering clean samples during training. However, simple sample filtering within feature spaces degraded by noise struggles to distinguish between challenging samples and noisy samples, creating a bottleneck for model performance. We highlight for the first time the fundamental importance of actively reshaping feature space geometry for learning from noisy data. We propose a novel Geometry-aware Manifold Regularization Paradigm whose core idea is to explicitly construct energy barriers between data manifolds by actively synthesizing virtual outlier samples. By imposing geometric constraints that promote intra-class compactness and inter-class separation, this approach enhances the discriminability between hard and noisy samples, leading to the learning of more robust representations. Our regularization mechanism exhibits high universality, with effectiveness independent of any prior assumptions about noise patterns. It can be integrated as a standalone mechanism into existing sample selection frameworks, providing stronger robustness against diverse noisy environments. Experiments demonstrate that our paradigm achieves performance surpassing current state-of-the-art (SOTA) methods on multiple benchmarks, including CIFAR-10, with particularly pronounced advantages under more challenging asymmetric noise conditions. Furthermore, this paradigm significantly enhances the model's capability in Out-of-Distribution (OOD) detection, ensuring superior reliability and safety for deployment in open-world scenarios.
Early High-Frequency Injection for Geometry-Sensitive OOD Detection
May 20, 2026Post-hoc OOD detectors score logits or features after training, so their success depends on the geometry already encoded in the representation. We revisit this assumption through a band-wise MMD^2 analysis across CE, SimCLR, SupCon, and the OOD-oriented representation method PALM. In our diagnostic, low-frequency input bands induce weaker ID/OOD feature discrepancy, whereas higher-frequency bands tend to provide stronger separability. This observation motivates EIHF, an input-side intervention that exposes high-frequency evidence before the first convolution without changing the training objective. EIHF is strongest for geometry-sensitive OOD detection: under matched training and scoring settings, it reshapes class-conditional feature geometry and reduces ID/OOD Mahalanobis score overlap. Experiments on CIFAR-100 and ImageNet-100 show gains on CIFAR-100 and the best average FPR95 with second-best average AUROC on ImageNet-100, while also revealing a limitation on the scene-centric Places shift. Code is available at https://anonymous.4open.science/r/EIHF.
Holistic Reliability Propagation: Decoupling Annotation and Prediction for Robust Noisy-Label
May 20, 2026Learning with noisy labels in multimedia classification often combines external annotations and model predictions into a single reliability weight, even though the two sources can fail for different reasons. We instead estimate disentangled reliabilities: bilevel meta-learning produces two batch-normalized scalars per sample, alpha for the given label and beta for the pseudo-label, without constraining them to sum to one. Holistic Reliability Propagation (HRP) then routes them to different objectives, using reliability-aware Mixup with global gating on the input branch and beta-gated pseudo-label positives on the contrastive branch. On synthetic and real-world benchmarks, HRP improves average accuracy over strong baselines and remains competitive at the highest noise rates.
PIS: A Physics-Informed System for Accurate State Partitioning of $Aβ_{42}$ Protein Trajectories
Feb 23, 2026Understanding the conformational evolution of $β$-amyloid ($Aβ$), particularly the $Aβ_{42}$ isoform, is fundamental to elucidating the pathogenic mechanisms underlying Alzheimer's disease. However, existing end-to-end deep learning models often struggle to capture subtle state transitions in protein trajectories due to a lack of explicit physical constraints. In this work, we introduce PIS, a Physics-Informed System designed for robust metastable state partitioning. By integrating pre-computed physical priors, such as the radius of gyration and solvent-accessible surface area, into the extraction of topological features, our model achieves superior performance on the $Aβ_{42}$ dataset. Furthermore, PIS provides an interactive platform that features dynamic monitoring of physical characteristics and multi-dimensional result validation. This system offers biological researchers a powerful set of analytical tools with physically grounded interpretability. A demonstration video of PIS is available on https://youtu.be/AJHGzUtRCg0.
Halt the Hallucination: Decoupling Signal and Semantic OOD Detection Based on Cascaded Early Rejection
Feb 06, 2026Efficient and robust Out-of-Distribution (OOD) detection is paramount for safety-critical applications.However, existing methods still execute full-scale inference on low-level statistical noise. This computational mismatch not only incurs resource waste but also induces semantic hallucination, where deep networks forcefully interpret physical anomalies as high-confidence semantic features.To address this, we propose the Cascaded Early Rejection (CER) framework, which realizes hierarchical filtering for anomaly detection via a coarse-to-fine logic.CER comprises two core modules: 1)Structural Energy Sieve (SES), which establishes a non-parametric barrier at the network entry using the Laplacian operator to efficiently intercept physical signal anomalies; and 2) the Semantically-aware Hyperspherical Energy (SHE) detector, which decouples feature magnitude from direction in intermediate layers to identify fine-grained semantic deviations. Experimental results demonstrate that CER not only reduces computational overhead by 32% but also achieves a significant performance leap on the CIFAR-100 benchmark:the average FPR95 drastically decreases from 33.58% to 22.84%, and AUROC improves to 93.97%. Crucially, in real-world scenarios simulating sensor failures, CER exhibits performance far exceeding state-of-the-art methods. As a universal plugin, CER can be seamlessly integrated into various SOTA models to provide performance gains.
Don't Break the Boundary: Continual Unlearning for OOD Detection Based on Free Energy Repulsion
Feb 06, 2026Deploying trustworthy AI in open-world environments faces a dual challenge: the necessity for robust Out-of-Distribution (OOD) detection to ensure system safety, and the demand for flexible machine unlearning to satisfy privacy compliance and model rectification. However, this objective encounters a fundamental geometric contradiction: current OOD detectors rely on a static and compact data manifold, whereas traditional classification-oriented unlearning methods disrupt this delicate structure, leading to a catastrophic loss of the model's capability to discriminate anomalies while erasing target classes. To resolve this dilemma, we first define the problem of boundary-preserving class unlearning and propose a pivotal conceptual shift: in the context of OOD detection, effective unlearning is mathematically equivalent to transforming the target class into OOD samples. Based on this, we propose the TFER (Total Free Energy Repulsion) framework. Inspired by the free energy principle, TFER constructs a novel Push-Pull game mechanism: it anchors retained classes within a low-energy ID manifold through a pull mechanism, while actively expelling forgotten classes to high-energy OOD regions using a free energy repulsion force. This approach is implemented via parameter-efficient fine-tuning, circumventing the prohibitive cost of full retraining. Extensive experiments demonstrate that TFER achieves precise unlearning while maximally preserving the model's discriminative performance on remaining classes and external OOD data. More importantly, our study reveals that the unique Push-Pull equilibrium of TFER endows the model with inherent structural stability, allowing it to effectively resist catastrophic forgetting without complex additional constraints, thereby demonstrating exceptional potential in continual unlearning tasks.
Learning with Adaptive Prototype Manifolds for Out-of-Distribution Detection
Feb 05, 2026Out-of-distribution (OOD) detection is a critical task for the safe deployment of machine learning models in the real world. Existing prototype-based representation learning methods have demonstrated exceptional performance. Specifically, we identify two fundamental flaws that universally constrain these methods: the Static Homogeneity Assumption (fixed representational resources for all classes) and the Learning-Inference Disconnect (discarding rich prototype quality knowledge at inference). These flaws fundamentally limit the model's capacity and performance. To address these issues, we propose APEX (Adaptive Prototype for eXtensive OOD Detection), a novel OOD detection framework designed via a Two-Stage Repair process to optimize the learned feature manifold. APEX introduces two key innovations to address these respective flaws: (1) an Adaptive Prototype Manifold (APM), which leverages the Minimum Description Length (MDL) principle to automatically determine the optimal prototype complexity $K_c^*$ for each class, thereby fundamentally resolving prototype collision; and (2) a Posterior-Aware OOD Scoring (PAOS) mechanism, which quantifies prototype quality (cohesion and separation) to bridge the learning-inference disconnect. Comprehensive experiments on benchmarks such as CIFAR-100 validate the superiority of our method, where APEX achieves new state-of-the-art performance.
Breaking Semantic Hegemony: Decoupling Principal and Residual Subspaces for Generalized OOD Detection
Feb 05, 2026While feature-based post-hoc methods have made significant strides in Out-of-Distribution (OOD) detection, we uncover a counter-intuitive Simplicity Paradox in existing state-of-the-art (SOTA) models: these models exhibit keen sensitivity in distinguishing semantically subtle OOD samples but suffer from severe Geometric Blindness when confronting structurally distinct yet semantically simple samples or high-frequency sensor noise. We attribute this phenomenon to Semantic Hegemony within the deep feature space and reveal its mathematical essence through the lens of Neural Collapse. Theoretical analysis demonstrates that the spectral concentration bias, induced by the high variance of the principal subspace, numerically masks the structural distribution shift signals that should be significant in the residual subspace. To address this issue, we propose D-KNN, a training-free, plug-and-play geometric decoupling framework. This method utilizes orthogonal decomposition to explicitly separate semantic components from structural residuals and introduces a dual-space calibration mechanism to reactivate the model's sensitivity to weak residual signals. Extensive experiments demonstrate that D-KNN effectively breaks Semantic Hegemony, establishing new SOTA performance on both CIFAR and ImageNet benchmarks. Notably, in resolving the Simplicity Paradox, it reduces the FPR95 from 31.3% to 2.3%; when addressing sensor failures such as Gaussian noise, it boosts the detection performance (AUROC) from a baseline of 79.7% to 94.9%.
VMF-GOS: Geometry-guided virtual Outlier Synthesis for Long-Tailed OOD Detection
Feb 05, 2026Out-of-Distribution (OOD) detection under long-tailed distributions is a highly challenging task because the scarcity of samples in tail classes leads to blurred decision boundaries in the feature space. Current state-of-the-art (sota) methods typically employ Outlier Exposure (OE) strategies, relying on large-scale real external datasets (such as 80 Million Tiny Images) to regularize the feature space. However, this dependence on external data often becomes infeasible in practical deployment due to high data acquisition costs and privacy sensitivity. To this end, we propose a novel data-free framework aimed at completely eliminating reliance on external datasets while maintaining superior detection performance. We introduce a Geometry-guided virtual Outlier Synthesis (GOS) strategy that models statistical properties using the von Mises-Fisher (vMF) distribution on a hypersphere. Specifically, we locate a low-likelihood annulus in the feature space and perform directional sampling of virtual outliers in this region. Simultaneously, we introduce a new Dual-Granularity Semantic Loss (DGS) that utilizes contrastive learning to maximize the distinction between in-distribution (ID) features and these synthesized boundary outliers. Extensive experiments on benchmarks such as CIFAR-LT demonstrate that our method outperforms sota approaches that utilize external real images.
DFEN: Dual Feature Equalization Network for Medical Image Segmentation
May 09, 2025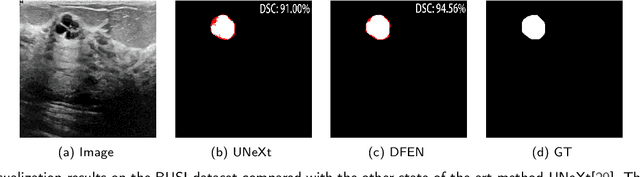
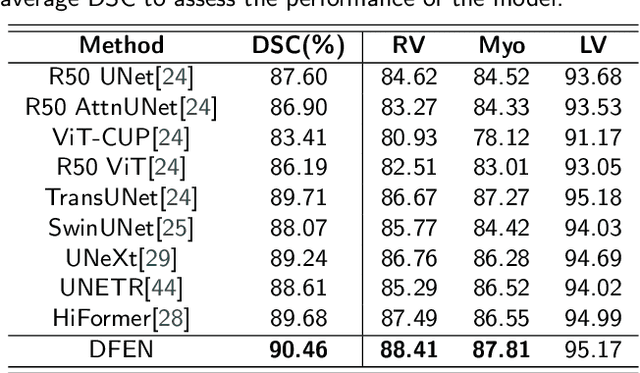
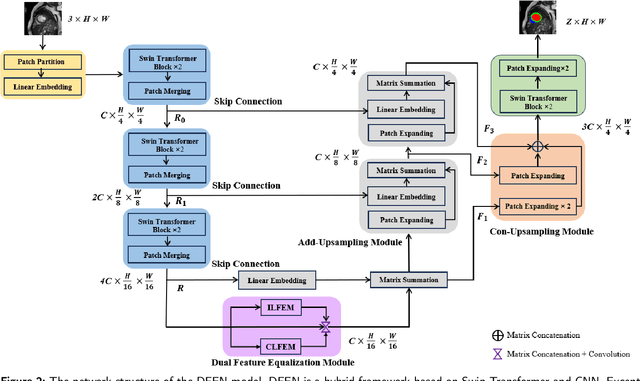
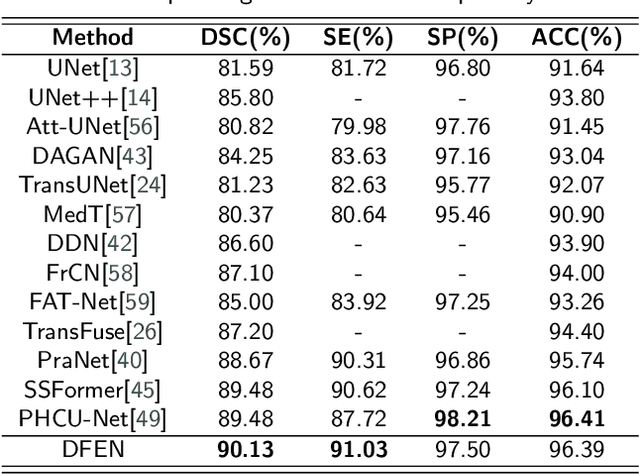
Current methods for medical image segmentation primarily focus on extracting contextual feature information from the perspective of the whole image. While these methods have shown effective performance, none of them take into account the fact that pixels at the boundary and regions with a low number of class pixels capture more contextual feature information from other classes, leading to misclassification of pixels by unequal contextual feature information. In this paper, we propose a dual feature equalization network based on the hybrid architecture of Swin Transformer and Convolutional Neural Network, aiming to augment the pixel feature representations by image-level equalization feature information and class-level equalization feature information. Firstly, the image-level feature equalization module is designed to equalize the contextual information of pixels within the image. Secondly, we aggregate regions of the same class to equalize the pixel feature representations of the corresponding class by class-level feature equalization module. Finally, the pixel feature representations are enhanced by learning weights for image-level equalization feature information and class-level equalization feature information. In addition, Swin Transformer is utilized as both the encoder and decoder, thereby bolstering the ability of the model to capture long-range dependencies and spatial correlations. We conducted extensive experiments on Breast Ultrasound Images (BUSI), International Skin Imaging Collaboration (ISIC2017), Automated Cardiac Diagnosis Challenge (ACDC) and PH$^2$ datasets. The experimental results demonstrate that our method have achieved state-of-the-art performance. Our code is publicly available at https://github.com/JianJianYin/DFEN.