 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianGrow: Geometry-aware Gaussian Growing from 3D Point Clouds with Text Guidance
Apr 07, 20263D Gaussian Splatting has demonstrated superior performance in rendering efficiency and quality, yet the generation of 3D Gaussians still remains a challenge without proper geometric priors. Existing methods have explored predicting point maps as geometric references for inferring Gaussian primitives, while the unreliable estimated geometries may lead to poor generations. In this work, we introduce GaussianGrow, a novel approach that generates 3D Gaussians by learning to grow them from easily accessible 3D point clouds, naturally enforcing geometric accuracy in Gaussian generation. Specifically, we design a text-guided Gaussian growing scheme that leverages a multi-view diffusion model to synthesize consistent appearances from input point clouds for supervision. To mitigate artifacts caused by fusing neighboring views, we constrain novel views generated at non-preset camera poses identified in overlapping regions across different views. For completing the hard-to-observe regions, we propose to iteratively detect the camera pose by observing the largest un-grown regions in point clouds and inpainting them by inpainting the rendered view with a pretrained 2D diffusion model. The process continues until complete Gaussians are generated. We extensively evaluate GaussianGrow on text-guided Gaussian generation from synthetic and even real-scanned point clouds. Project Page: https://weiqi-zhang.github.io/GaussianGrow
4C4D: 4 Camera 4D Gaussian Splatting
Apr 05, 2026This paper tackles the challenge of recovering 4D dynamic scenes from videos captured by as few as four portable cameras. Learning to model scene dynamics for temporally consistent novel-view rendering is a foundational task in computer graphics, where previous works often require dense multi-view captures using camera arrays of dozens or even hundreds of views. We propose \textbf{4C4D}, a novel framework that enables high-fidelity 4D Gaussian Splatting from video captures of extremely sparse cameras. Our key insight lies that the geometric learning under sparse settings is substantially more difficult than modeling appearance. Driven by this observation, we introduce a Neural Decaying Function on Gaussian opacities for enhancing the geometric modeling capability of 4D Gaussians. This design mitigates the inherent imbalance between geometry and appearance modeling in 4DGS by encouraging the 4DGS gradients to focus more on geometric learning. Extensive experiments across sparse-view datasets with varying camera overlaps show that 4C4D achieves superior performance over prior art. Project page at: https://junshengzhou.github.io/4C4D.
AnchoredDream: Zero-Shot 360° Indoor Scene Generation from a Single View via Geometric Grounding
Jan 26, 2026Single-view indoor scene generation plays a crucial role in a range of real-world applications. However, generating a complete 360° scene from a single image remains a highly ill-posed and challenging problem. Recent approaches have made progress by leveraging diffusion models and depth estimation networks, yet they still struggle to maintain appearance consistency and geometric plausibility under large viewpoint changes, limiting their effectiveness in full-scene generation. To address this, we propose AnchoredDream, a novel zero-shot pipeline that anchors 360° scene generation on high-fidelity geometry via an appearance-geometry mutual boosting mechanism. Given a single-view image, our method first performs appearance-guided geometry generation to construct a reliable 3D scene layout. Then, we progressively generate the complete scene through a series of modules: warp-and-inpaint, warp-and-refine, post-optimization, and a novel Grouting Block, which ensures seamless transitions between the input view and generated regions. Extensive experiments demonstrate that AnchoredDream outperforms existing methods by a large margin in both appearance consistency and geometric plausibility--all in a zero-shot manner. Our results highlight the potential of geometric grounding for high-quality, zero-shot single-view scene generation.
GAP: Gaussianize Any Point Clouds with Text Guidance
Aug 07, 20253D Gaussian Splatting (3DGS) has demonstrated its advantages in achieving fast and high-quality rendering. As point clouds serve as a widely-used and easily accessible form of 3D representation, bridging the gap between point clouds and Gaussians becomes increasingly important. Recent studies have explored how to convert the colored points into Gaussians, but directly generating Gaussians from colorless 3D point clouds remains an unsolved challenge. In this paper, we propose GAP, a novel approach that gaussianizes raw point clouds into high-fidelity 3D Gaussians with text guidance. Our key idea is to design a multi-view optimization framework that leverages a depth-aware image diffusion model to synthesize consistent appearances across different viewpoints. To ensure geometric accuracy, we introduce a surface-anchoring mechanism that effectively constrains Gaussians to lie on the surfaces of 3D shapes during optimization. Furthermore, GAP incorporates a diffuse-based inpainting strategy that specifically targets at completing hard-to-observe regions. We evaluate GAP on the Point-to-Gaussian generation task across varying complexity levels, from synthetic point clouds to challenging real-world scans, and even large-scale scenes. Project Page: https://weiqi-zhang.github.io/GAP.
iDiT-HOI: Inpainting-based Hand Object Interaction Reenactment via Video Diffusion Transformer
Jun 15, 2025Digital human video generation is gaining traction in fields like education and e-commerce, driven by advancements in head-body animation and lip-syncing technologies. However, realistic Hand-Object Interaction (HOI) - the complex dynamics between human hands and objects - continues to pose challenges. Generating natural and believable HOI reenactments is difficult due to issues such as occlusion between hands and objects, variations in object shapes and orientations, and the necessity for precise physical interactions, and importantly, the ability to generalize to unseen humans and objects. This paper presents a novel framework iDiT-HOI that enables in-the-wild HOI reenactment generation. Specifically, we propose a unified inpainting-based token process method, called Inp-TPU, with a two-stage video diffusion transformer (DiT) model. The first stage generates a key frame by inserting the designated object into the hand region, providing a reference for subsequent frames. The second stage ensures temporal coherence and fluidity in hand-object interactions. The key contribution of our method is to reuse the pretrained model's context perception capabilities without introducing additional parameters, enabling strong generalization to unseen objects and scenarios, and our proposed paradigm naturally supports long video generation. Comprehensive evaluations demonstrate that our approach outperforms existing methods, particularly in challenging real-world scenes, offering enhanced realism and more seamless hand-object interactions.
DFEN: Dual Feature Equalization Network for Medical Image Segmentation
May 09, 2025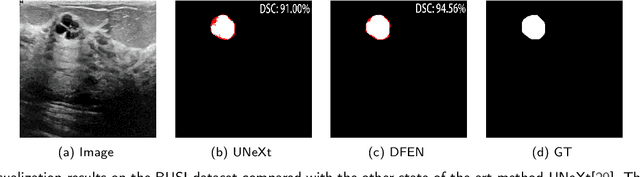
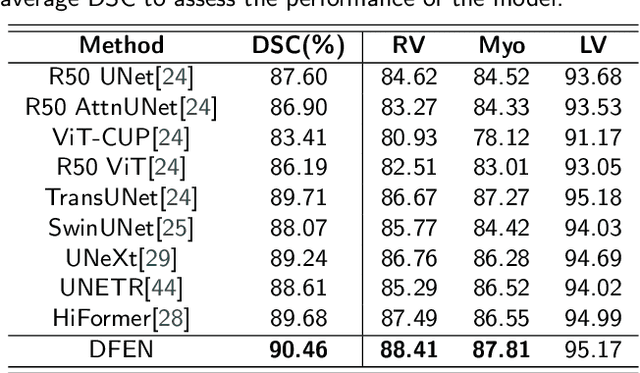
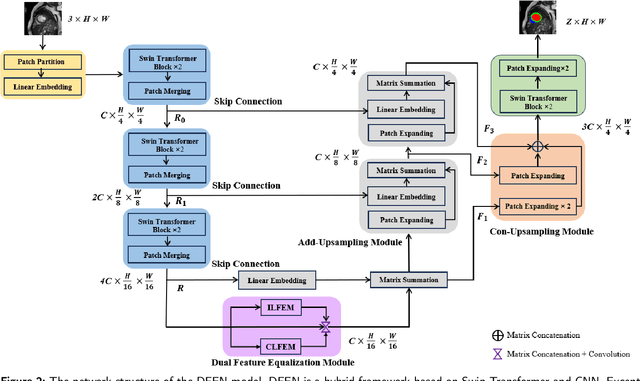
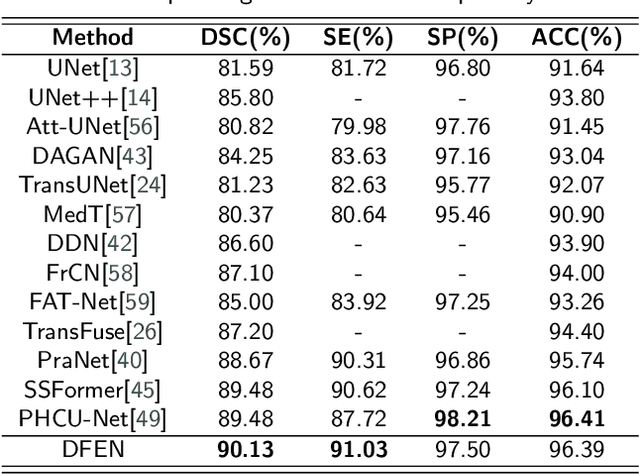
Current methods for medical image segmentation primarily focus on extracting contextual feature information from the perspective of the whole image. While these methods have shown effective performance, none of them take into account the fact that pixels at the boundary and regions with a low number of class pixels capture more contextual feature information from other classes, leading to misclassification of pixels by unequal contextual feature information. In this paper, we propose a dual feature equalization network based on the hybrid architecture of Swin Transformer and Convolutional Neural Network, aiming to augment the pixel feature representations by image-level equalization feature information and class-level equalization feature information. Firstly, the image-level feature equalization module is designed to equalize the contextual information of pixels within the image. Secondly, we aggregate regions of the same class to equalize the pixel feature representations of the corresponding class by class-level feature equalization module. Finally, the pixel feature representations are enhanced by learning weights for image-level equalization feature information and class-level equalization feature information. In addition, Swin Transformer is utilized as both the encoder and decoder, thereby bolstering the ability of the model to capture long-range dependencies and spatial correlations. We conducted extensive experiments on Breast Ultrasound Images (BUSI), International Skin Imaging Collaboration (ISIC2017), Automated Cardiac Diagnosis Challenge (ACDC) and PH$^2$ datasets. The experimental results demonstrate that our method have achieved state-of-the-art performance. Our code is publicly available at https://github.com/JianJianYin/DFEN.
Learning Bijective Surface Parameterization for Inferring Signed Distance Functions from Sparse Point Clouds with Grid Deformation
Mar 31, 2025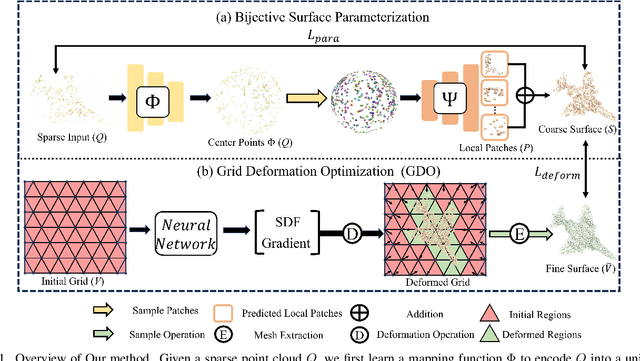
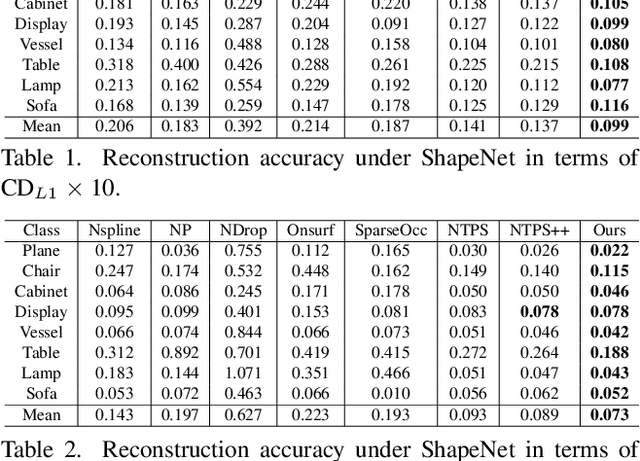
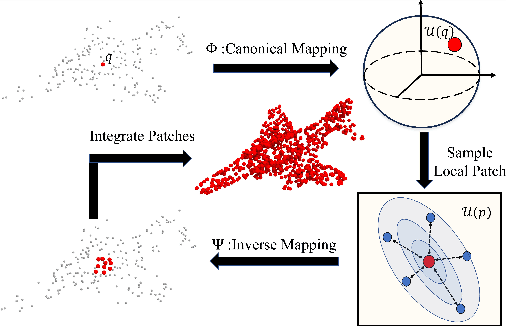
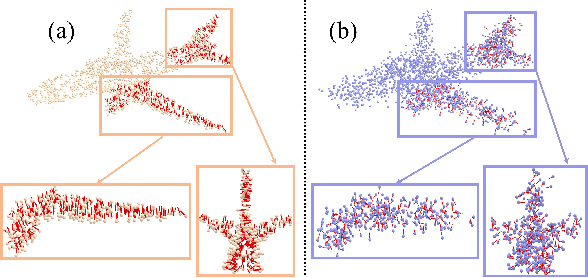
Inferring signed distance functions (SDFs) from sparse point clouds remains a challenge in surface reconstruction. The key lies in the lack of detailed geometric information in sparse point clouds, which is essential for learning a continuous field. To resolve this issue, we present a novel approach that learns a dynamic deformation network to predict SDFs in an end-to-end manner. To parameterize a continuous surface from sparse points, we propose a bijective surface parameterization (BSP) that learns the global shape from local patches. Specifically, we construct a bijective mapping for sparse points from the parametric domain to 3D local patches, integrating patches into the global surface. Meanwhile, we introduce grid deformation optimization (GDO) into the surface approximation to optimize the deformation of grid points and further refine the parametric surfaces. Experimental results on synthetic and real scanned datasets demonstrate that our method significantly outperforms the current state-of-the-art methods. Project page: https://takeshie.github.io/Bijective-SDF
Uncertainty-Participation Context Consistency Learning for Semi-supervised Semantic Segmentation
Dec 24, 2024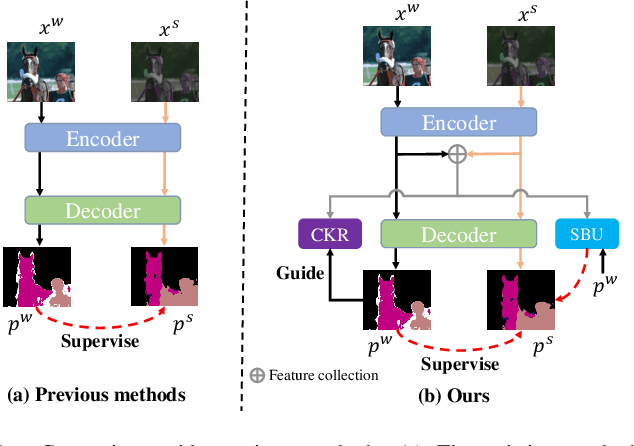
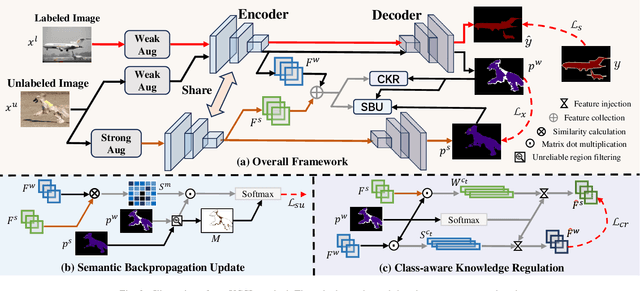
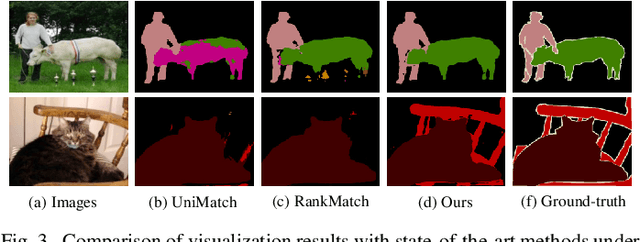
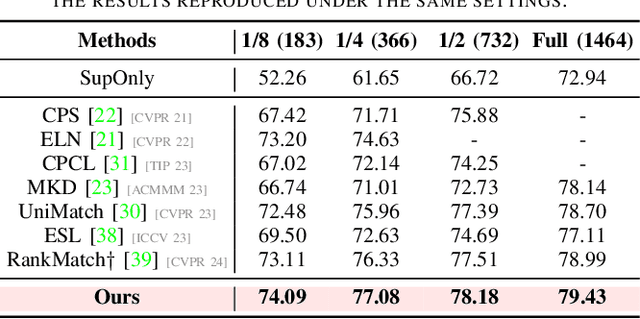
Semi-supervised semantic segmentation has attracted considerable attention for its ability to mitigate the reliance on extensive labeled data. However, existing consistency regularization methods only utilize high certain pixels with prediction confidence surpassing a fixed threshold for training, failing to fully leverage the potential supervisory information within the network. Therefore, this paper proposes the Uncertainty-participation Context Consistency Learning (UCCL) method to explore richer supervisory signals. Specifically, we first design the semantic backpropagation update (SBU) strategy to fully exploit the knowledge from uncertain pixel regions, enabling the model to learn consistent pixel-level semantic information from those areas. Furthermore, we propose the class-aware knowledge regulation (CKR) module to facilitate the regulation of class-level semantic features across different augmented views, promoting consistent learning of class-level semantic information within the encoder. Experimental results on two public benchmarks demonstrate that our proposed method achieves state-of-the-art performance. Our code is available at https://github.com/YUKEKEJAN/UCCL.
DiffGS: Functional Gaussian Splatting Diffusion
Oct 25, 2024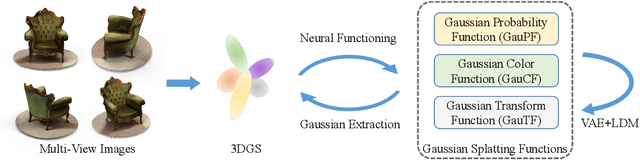
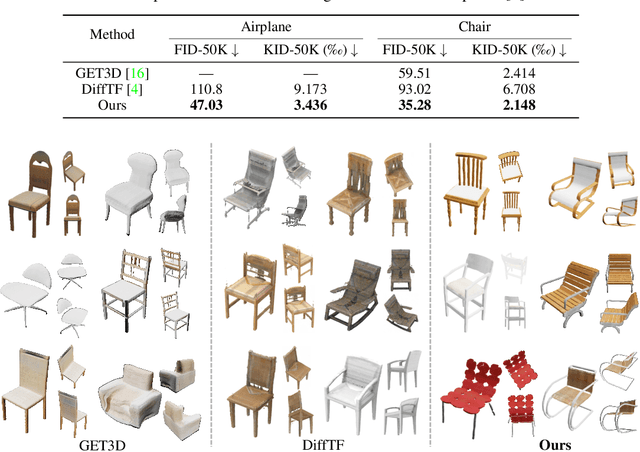
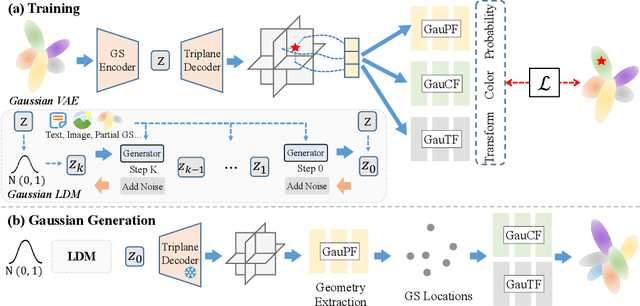
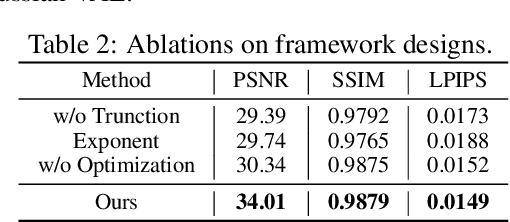
3D Gaussian Splatting (3DGS) has shown convincing performance in rendering speed and fidelity, yet the generation of Gaussian Splatting remains a challenge due to its discreteness and unstructured nature. In this work, we propose DiffGS, a general Gaussian generator based on latent diffusion models. DiffGS is a powerful and efficient 3D generative model which is capable of generating Gaussian primitives at arbitrary numbers for high-fidelity rendering with rasterization. The key insight is to represent Gaussian Splatting in a disentangled manner via three novel functions to model Gaussian probabilities, colors and transforms. Through the novel disentanglement of 3DGS, we represent the discrete and unstructured 3DGS with continuous Gaussian Splatting functions, where we then train a latent diffusion model with the target of generating these Gaussian Splatting functions both unconditionally and conditionally. Meanwhile, we introduce a discretization algorithm to extract Gaussians at arbitrary numbers from the generated functions via octree-guided sampling and optimization. We explore DiffGS for various tasks, including unconditional generation, conditional generation from text, image, and partial 3DGS, as well as Point-to-Gaussian generation. We believe that DiffGS provides a new direction for flexibly modeling and generating Gaussian Splatting.
Binocular-Guided 3D Gaussian Splatting with View Consistency for Sparse View Synthesis
Oct 24, 2024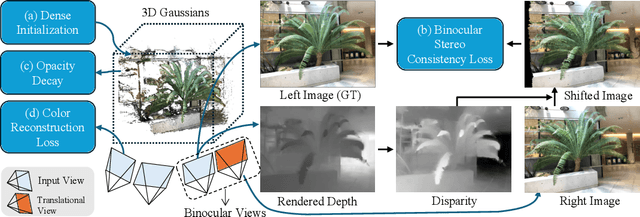
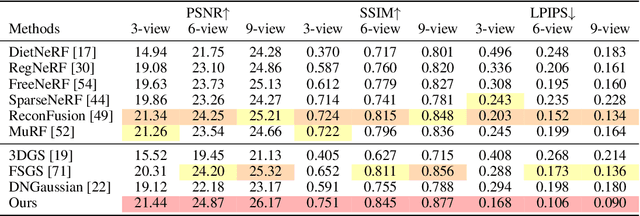
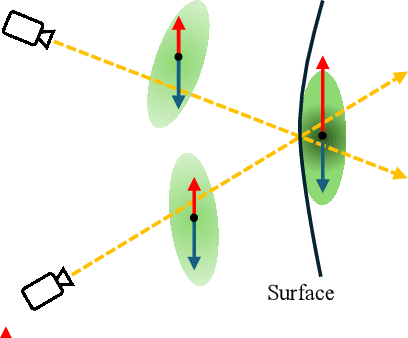
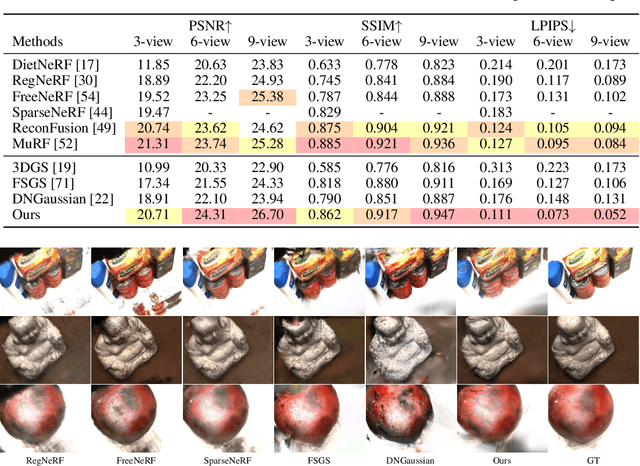
Novel view synthesis from sparse inputs is a vital yet challenging task in 3D computer vision. Previous methods explore 3D Gaussian Splatting with neural priors (e.g. depth priors) as an additional supervision, demonstrating promising quality and efficiency compared to the NeRF based methods. However, the neural priors from 2D pretrained models are often noisy and blurry, which struggle to precisely guide the learning of radiance fields. In this paper, We propose a novel method for synthesizing novel views from sparse views with Gaussian Splatting that does not require external prior as supervision. Our key idea lies in exploring the self-supervisions inherent in the binocular stereo consistency between each pair of binocular images constructed with disparity-guided image warping. To this end, we additionally introduce a Gaussian opacity constraint which regularizes the Gaussian locations and avoids Gaussian redundancy for improving the robustness and efficiency of inferring 3D Gaussians from sparse views. Extensive experiments on the LLFF, DTU, and Blender datasets demonstrate that our method significantly outperforms the state-of-the-art methods.