 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Unsigned Distance Functions from Multi-view Images with Volume Rendering Priors
Jul 23, 2024
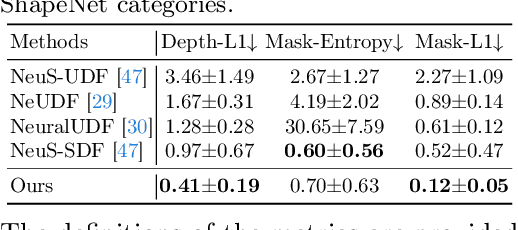
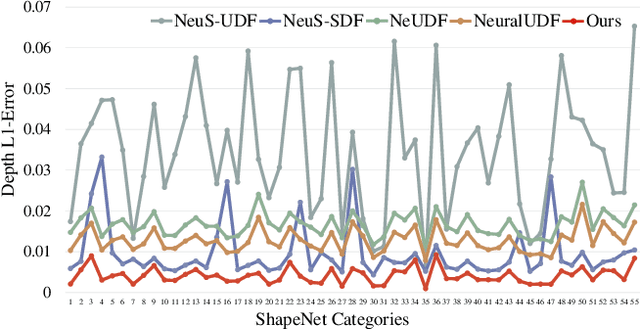

Unsigned distance functions (UDFs) have been a vital representation for open surfaces. With different differentiable renderers, current methods are able to train neural networks to infer a UDF by minimizing the rendering errors on the UDF to the multi-view ground truth. However, these differentiable renderers are mainly handcrafted, which makes them either biased on ray-surface intersections, or sensitive to unsigned distance outliers, or not scalable to large scale scenes. To resolve these issues, we present a novel differentiable renderer to infer UDFs more accurately. Instead of using handcrafted equations, our differentiable renderer is a neural network which is pre-trained in a data-driven manner. It learns how to render unsigned distances into depth images, leading to a prior knowledge, dubbed volume rendering priors. To infer a UDF for an unseen scene from multiple RGB images, we generalize the learned volume rendering priors to map inferred unsigned distances in alpha blending for RGB image rendering. Our results show that the learned volume rendering priors are unbiased, robust, scalable, 3D aware, and more importantly, easy to learn. We evaluate our method on both widely used benchmarks and real scenes, and report superior performance over the state-of-the-art methods.
UDiFF: Generating Conditional Unsigned Distance Fields with Optimal Wavelet Diffusion
Apr 10, 2024Diffusion models have shown remarkable results for image generation, editing and inpainting. Recent works explore diffusion models for 3D shape generation with neural implicit functions, i.e., signed distance function and occupancy function. However, they are limited to shapes with closed surfaces, which prevents them from generating diverse 3D real-world contents containing open surfaces. In this work, we present UDiFF, a 3D diffusion model for unsigned distance fields (UDFs) which is capable to generate textured 3D shapes with open surfaces from text conditions or unconditionally. Our key idea is to generate UDFs in spatial-frequency domain with an optimal wavelet transformation, which produces a compact representation space for UDF generation. Specifically, instead of selecting an appropriate wavelet transformation which requires expensive manual efforts and still leads to large information loss, we propose a data-driven approach to learn the optimal wavelet transformation for UDFs. We evaluate UDiFF to show our advantages by numerical and visual comparisons with the latest methods on widely used benchmarks. Page: https://weiqi-zhang.github.io/UDiFF.
Agents meet OKR: An Object and Key Results Driven Agent System with Hierarchical Self-Collaboration and Self-Evaluation
Nov 28, 2023



In this study, we introduce the concept of OKR-Agent designed to enhance the capabilities of Large Language Models (LLMs) in task-solving. Our approach utilizes both self-collaboration and self-correction mechanism, facilitated by hierarchical agents, to address the inherent complexities in task-solving. Our key observations are two-fold: first, effective task-solving demands in-depth domain knowledge and intricate reasoning, for which deploying specialized agents for individual sub-tasks can markedly enhance LLM performance. Second, task-solving intrinsically adheres to a hierarchical execution structure, comprising both high-level strategic planning and detailed task execution. Towards this end, our OKR-Agent paradigm aligns closely with this hierarchical structure, promising enhanced efficacy and adaptability across a range of scenarios. Specifically, our framework includes two novel modules: hierarchical Objects and Key Results generation and multi-level evaluation, each contributing to more efficient and robust task-solving. In practical, hierarchical OKR generation decomposes Objects into multiple sub-Objects and assigns new agents based on key results and agent responsibilities. These agents subsequently elaborate on their designated tasks and may further decompose them as necessary. Such generation operates recursively and hierarchically, culminating in a comprehensive set of detailed solutions. The multi-level evaluation module of OKR-Agent refines solution by leveraging feedback from all associated agents, optimizing each step of the process. This ensures solution is accurate, practical, and effectively address intricate task requirements, enhancing the overall reliability and quality of the outcome. Experimental results also show our method outperforms the previous methods on several tasks. Code and demo are available at https://okr-agent.github.io/
NeuralGF: Unsupervised Point Normal Estimation by Learning Neural Gradient Function
Nov 01, 2023Normal estimation for 3D point clouds is a fundamental task in 3D geometry processing. The state-of-the-art methods rely on priors of fitting local surfaces learned from normal supervision. However, normal supervision in benchmarks comes from synthetic shapes and is usually not available from real scans, thereby limiting the learned priors of these methods. In addition, normal orientation consistency across shapes remains difficult to achieve without a separate post-processing procedure. To resolve these issues, we propose a novel method for estimating oriented normals directly from point clouds without using ground truth normals as supervision. We achieve this by introducing a new paradigm for learning neural gradient functions, which encourages the neural network to fit the input point clouds and yield unit-norm gradients at the points. Specifically, we introduce loss functions to facilitate query points to iteratively reach the moving targets and aggregate onto the approximated surface, thereby learning a global surface representation of the data. Meanwhile, we incorporate gradients into the surface approximation to measure the minimum signed deviation of queries, resulting in a consistent gradient field associated with the surface. These techniques lead to our deep unsupervised oriented normal estimator that is robust to noise, outliers and density variations. Our excellent results on widely used benchmarks demonstrate that our method can learn more accurate normals for both unoriented and oriented normal estimation tasks than the latest methods. The source code and pre-trained model are publicly available at https://github.com/LeoQLi/NeuralGF.
Neural Gradient Learning and Optimization for Oriented Point Normal Estimation
Sep 17, 2023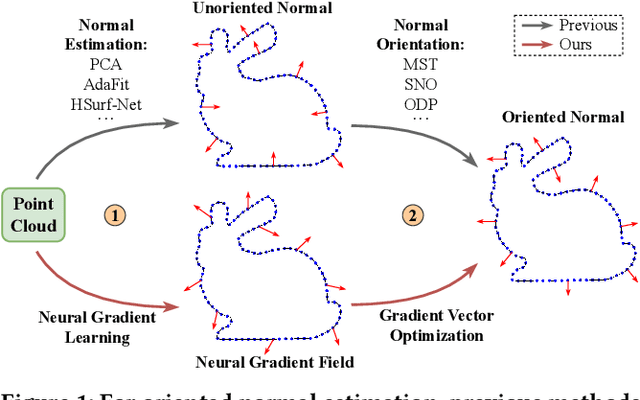
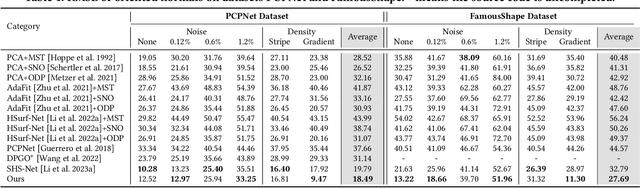

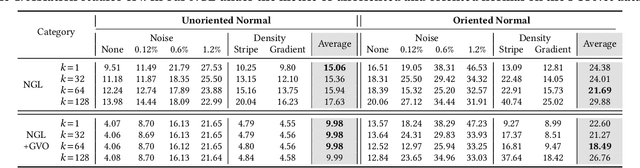
We propose Neural Gradient Learning (NGL), a deep learning approach to learn gradient vectors with consistent orientation from 3D point clouds for normal estimation. It has excellent gradient approximation properties for the underlying geometry of the data. We utilize a simple neural network to parameterize the objective function to produce gradients at points using a global implicit representation. However, the derived gradients usually drift away from the ground-truth oriented normals due to the lack of local detail descriptions. Therefore, we introduce Gradient Vector Optimization (GVO) to learn an angular distance field based on local plane geometry to refine the coarse gradient vectors. Finally, we formulate our method with a two-phase pipeline of coarse estimation followed by refinement. Moreover, we integrate two weighting functions, i.e., anisotropic kernel and inlier score, into the optimization to improve the robust and detail-preserving performance. Our method efficiently conducts global gradient approximation while achieving better accuracy and generalization ability of local feature description. This leads to a state-of-the-art normal estimator that is robust to noise, outliers and point density variations. Extensive evaluations show that our method outperforms previous works in both unoriented and oriented normal estimation on widely used benchmarks. The source code and pre-trained models are available at https://github.com/LeoQLi/NGLO.
SHS-Net: Learning Signed Hyper Surfaces for Oriented Normal Estimation of Point Clouds
May 10, 2023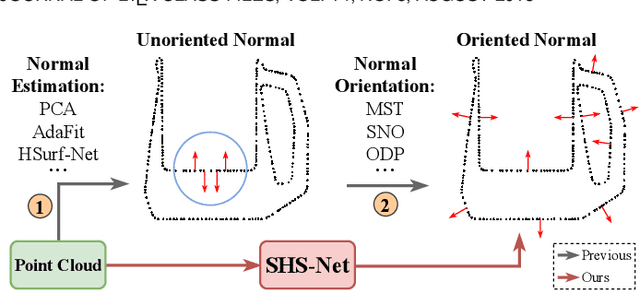
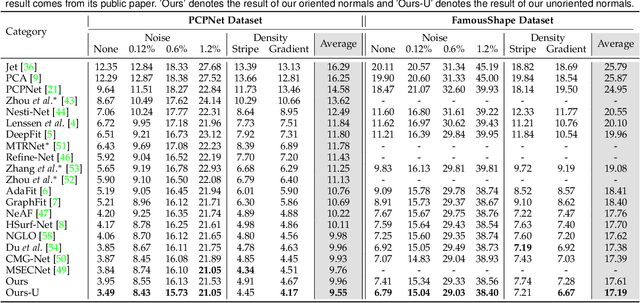
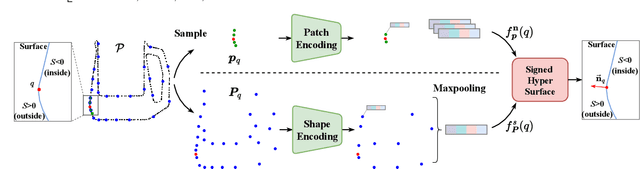

We propose a novel method called SHS-Net for oriented normal estimation of point clouds by learning signed hyper surfaces, which can accurately predict normals with global consistent orientation from various point clouds. Almost all existing methods estimate oriented normals through a two-stage pipeline, i.e., unoriented normal estimation and normal orientation, and each step is implemented by a separate algorithm. However, previous methods are sensitive to parameter settings, resulting in poor results from point clouds with noise, density variations and complex geometries. In this work, we introduce signed hyper surfaces (SHS), which are parameterized by multi-layer perceptron (MLP) layers, to learn to estimate oriented normals from point clouds in an end-to-end manner. The signed hyper surfaces are implicitly learned in a high-dimensional feature space where the local and global information is aggregated. Specifically, we introduce a patch encoding module and a shape encoding module to encode a 3D point cloud into a local latent code and a global latent code, respectively. Then, an attention-weighted normal prediction module is proposed as a decoder, which takes the local and global latent codes as input to predict oriented normals. Experimental results show that our SHS-Net outperforms the state-of-the-art methods in both unoriented and oriented normal estimation on the widely used benchmarks. The code, data and pretrained models are publicly available.
Fast Learning Radiance Fields by Shooting Much Fewer Rays
Aug 14, 2022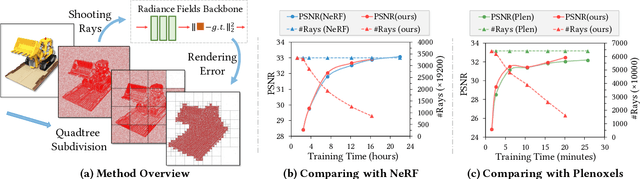


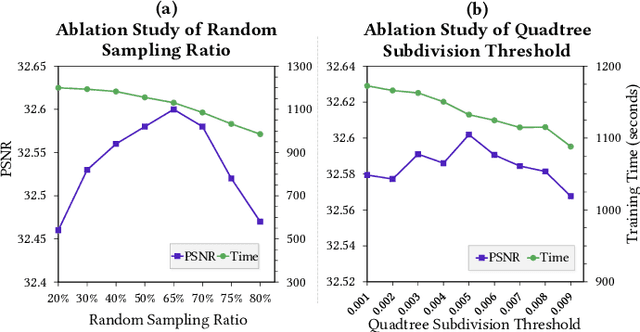
Learning radiance fields has shown remarkable results for novel view synthesis. The learning procedure usually costs lots of time, which motivates the latest methods to speed up the learning procedure by learning without neural networks or using more efficient data structures. However, these specially designed approaches do not work for most of radiance fields based methods. To resolve this issue, we introduce a general strategy to speed up the learning procedure for almost all radiance fields based methods. Our key idea is to reduce the redundancy by shooting much fewer rays in the multi-view volume rendering procedure which is the base for almost all radiance fields based methods. We find that shooting rays at pixels with dramatic color change not only significantly reduces the training burden but also barely affects the accuracy of the learned radiance fields. In addition, we also adaptively subdivide each view into a quadtree according to the average rendering error in each node in the tree, which makes us dynamically shoot more rays in more complex regions with larger rendering error. We evaluate our method with different radiance fields based methods under the widely used benchmarks. Experimental results show that our method achieves comparable accuracy to the state-of-the-art with much faster training.