 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of World: World Model Thinking in Latent Motion
Mar 03, 2026Vision-Language-Action (VLA) models are a promising path toward embodied intelligence, yet they often overlook the predictive and temporal-causal structure underlying visual dynamics. World-model VLAs address this by predicting future frames, but waste capacity reconstructing redundant backgrounds. Latent-action VLAs encode frame-to-frame transitions compactly, but lack temporally continuous dynamic modeling and world knowledge. To overcome these limitations, we introduce CoWVLA (Chain-of-World VLA), a new "Chain of World" paradigm that unifies world-model temporal reasoning with a disentangled latent motion representation. First, a pretrained video VAE serves as a latent motion extractor, explicitly factorizing video segments into structure and motion latents. Then, during pre-training, the VLA learns from an instruction and an initial frame to infer a continuous latent motion chain and predict the segment's terminal frame. Finally, during co-fine-tuning, this latent dynamic is aligned with discrete action prediction by jointly modeling sparse keyframes and action sequences in a unified autoregressive decoder. This design preserves the world-model benefits of temporal reasoning and world knowledge while retaining the compactness and interpretability of latent actions, enabling efficient visuomotor learning. Extensive experiments on robotic simulation benchmarks show that CoWVLA outperforms existing world-model and latent-action approaches and achieves moderate computational efficiency, highlighting its potential as a more effective VLA pretraining paradigm. The project website can be found at https://fx-hit.github.io/cowvla-io.
MetricAnything: Scaling Metric Depth Pretraining with Noisy Heterogeneous Sources
Jan 29, 2026Scaling has powered recent advances in vision foundation models, yet extending this paradigm to metric depth estimation remains challenging due to heterogeneous sensor noise, camera-dependent biases, and metric ambiguity in noisy cross-source 3D data. We introduce Metric Anything, a simple and scalable pretraining framework that learns metric depth from noisy, diverse 3D sources without manually engineered prompts, camera-specific modeling, or task-specific architectures. Central to our approach is the Sparse Metric Prompt, created by randomly masking depth maps, which serves as a universal interface that decouples spatial reasoning from sensor and camera biases. Using about 20M image-depth pairs spanning reconstructed, captured, and rendered 3D data across 10000 camera models, we demonstrate-for the first time-a clear scaling trend in the metric depth track. The pretrained model excels at prompt-driven tasks such as depth completion, super-resolution and Radar-camera fusion, while its distilled prompt-free student achieves state-of-the-art results on monocular depth estimation, camera intrinsics recovery, single/multi-view metric 3D reconstruction, and VLA planning. We also show that using pretrained ViT of Metric Anything as a visual encoder significantly boosts Multimodal Large Language Model capabilities in spatial intelligence. These results show that metric depth estimation can benefit from the same scaling laws that drive modern foundation models, establishing a new path toward scalable and efficient real-world metric perception. We open-source MetricAnything at http://metric-anything.github.io/metric-anything-io/ to support community research.
TIGaussian: Disentangle Gaussians for Spatial-Awared Text-Image-3D Alignment
Jan 27, 2026While visual-language models have profoundly linked features between texts and images, the incorporation of 3D modality data, such as point clouds and 3D Gaussians, further enables pretraining for 3D-related tasks, e.g., cross-modal retrieval, zero-shot classification, and scene recognition. As challenges remain in extracting 3D modal features and bridging the gap between different modalities, we propose TIGaussian, a framework that harnesses 3D Gaussian Splatting (3DGS) characteristics to strengthen cross-modality alignment through multi-branch 3DGS tokenizer and modality-specific 3D feature alignment strategies. Specifically, our multi-branch 3DGS tokenizer decouples the intrinsic properties of 3DGS structures into compact latent representations, enabling more generalizable feature extraction. To further bridge the modality gap, we develop a bidirectional cross-modal alignment strategies: a multi-view feature fusion mechanism that leverages diffusion priors to resolve perspective ambiguity in image-3D alignment, while a text-3D projection module adaptively maps 3D features to text embedding space for better text-3D alignment. Extensive experiments on various datasets demonstrate the state-of-the-art performance of TIGaussian in multiple tasks.
SEE4D: Pose-Free 4D Generation via Auto-Regressive Video Inpainting
Oct 30, 2025Immersive applications call for synthesizing spatiotemporal 4D content from casual videos without costly 3D supervision. Existing video-to-4D methods typically rely on manually annotated camera poses, which are labor-intensive and brittle for in-the-wild footage. Recent warp-then-inpaint approaches mitigate the need for pose labels by warping input frames along a novel camera trajectory and using an inpainting model to fill missing regions, thereby depicting the 4D scene from diverse viewpoints. However, this trajectory-to-trajectory formulation often entangles camera motion with scene dynamics and complicates both modeling and inference. We introduce SEE4D, a pose-free, trajectory-to-camera framework that replaces explicit trajectory prediction with rendering to a bank of fixed virtual cameras, thereby separating camera control from scene modeling. A view-conditional video inpainting model is trained to learn a robust geometry prior by denoising realistically synthesized warped images and to inpaint occluded or missing regions across virtual viewpoints, eliminating the need for explicit 3D annotations. Building on this inpainting core, we design a spatiotemporal autoregressive inference pipeline that traverses virtual-camera splines and extends videos with overlapping windows, enabling coherent generation at bounded per-step complexity. We validate See4D on cross-view video generation and sparse reconstruction benchmarks. Across quantitative metrics and qualitative assessments, our method achieves superior generalization and improved performance relative to pose- or trajectory-conditioned baselines, advancing practical 4D world modeling from casual videos.
You See it, You Got it: Learning 3D Creation on Pose-Free Videos at Scale
Dec 09, 2024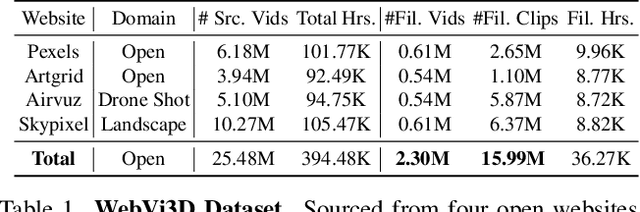
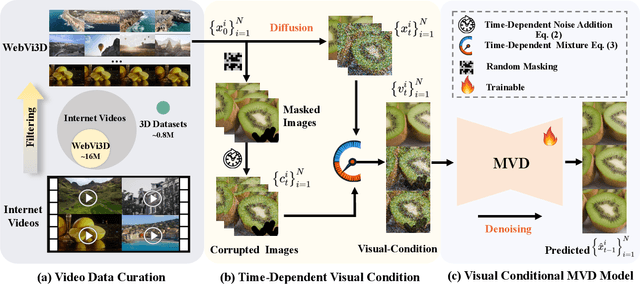
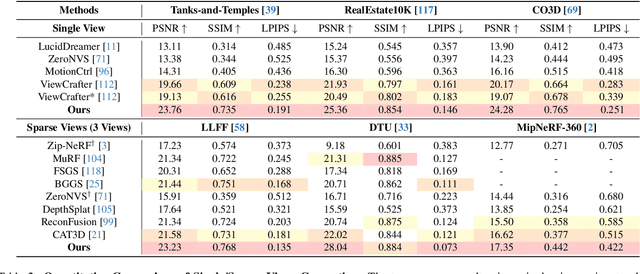

Recent 3D generation models typically rely on limited-scale 3D `gold-labels' or 2D diffusion priors for 3D content creation. However, their performance is upper-bounded by constrained 3D priors due to the lack of scalable learning paradigms. In this work, we present See3D, a visual-conditional multi-view diffusion model trained on large-scale Internet videos for open-world 3D creation. The model aims to Get 3D knowledge by solely Seeing the visual contents from the vast and rapidly growing video data -- You See it, You Got it. To achieve this, we first scale up the training data using a proposed data curation pipeline that automatically filters out multi-view inconsistencies and insufficient observations from source videos. This results in a high-quality, richly diverse, large-scale dataset of multi-view images, termed WebVi3D, containing 320M frames from 16M video clips. Nevertheless, learning generic 3D priors from videos without explicit 3D geometry or camera pose annotations is nontrivial, and annotating poses for web-scale videos is prohibitively expensive. To eliminate the need for pose conditions, we introduce an innovative visual-condition - a purely 2D-inductive visual signal generated by adding time-dependent noise to the masked video data. Finally, we introduce a novel visual-conditional 3D generation framework by integrating See3D into a warping-based pipeline for high-fidelity 3D generation. Our numerical and visual comparisons on single and sparse reconstruction benchmarks show that See3D, trained on cost-effective and scalable video data, achieves notable zero-shot and open-world generation capabilities, markedly outperforming models trained on costly and constrained 3D datasets. Please refer to our project page at: https://vision.baai.ac.cn/see3d
UDiFF: Generating Conditional Unsigned Distance Fields with Optimal Wavelet Diffusion
Apr 10, 2024Diffusion models have shown remarkable results for image generation, editing and inpainting. Recent works explore diffusion models for 3D shape generation with neural implicit functions, i.e., signed distance function and occupancy function. However, they are limited to shapes with closed surfaces, which prevents them from generating diverse 3D real-world contents containing open surfaces. In this work, we present UDiFF, a 3D diffusion model for unsigned distance fields (UDFs) which is capable to generate textured 3D shapes with open surfaces from text conditions or unconditionally. Our key idea is to generate UDFs in spatial-frequency domain with an optimal wavelet transformation, which produces a compact representation space for UDF generation. Specifically, instead of selecting an appropriate wavelet transformation which requires expensive manual efforts and still leads to large information loss, we propose a data-driven approach to learn the optimal wavelet transformation for UDFs. We evaluate UDiFF to show our advantages by numerical and visual comparisons with the latest methods on widely used benchmarks. Page: https://weiqi-zhang.github.io/UDiFF.
Learning Continuous Implicit Field with Local Distance Indicator for Arbitrary-Scale Point Cloud Upsampling
Dec 23, 2023Point cloud upsampling aims to generate dense and uniformly distributed point sets from a sparse point cloud, which plays a critical role in 3D computer vision. Previous methods typically split a sparse point cloud into several local patches, upsample patch points, and merge all upsampled patches. However, these methods often produce holes, outliers or nonuniformity due to the splitting and merging process which does not maintain consistency among local patches. To address these issues, we propose a novel approach that learns an unsigned distance field guided by local priors for point cloud upsampling. Specifically, we train a local distance indicator (LDI) that predicts the unsigned distance from a query point to a local implicit surface. Utilizing the learned LDI, we learn an unsigned distance field to represent the sparse point cloud with patch consistency. At inference time, we randomly sample queries around the sparse point cloud, and project these query points onto the zero-level set of the learned implicit field to generate a dense point cloud. We justify that the implicit field is naturally continuous, which inherently enables the application of arbitrary-scale upsampling without necessarily retraining for various scales. We conduct comprehensive experiments on both synthetic data and real scans, and report state-of-the-art results under widely used benchmarks.
Differentiable Registration of Images and LiDAR Point Clouds with VoxelPoint-to-Pixel Matching
Dec 07, 2023



Cross-modality registration between 2D images from cameras and 3D point clouds from LiDARs is a crucial task in computer vision and robotic. Previous methods estimate 2D-3D correspondences by matching point and pixel patterns learned by neural networks, and use Perspective-n-Points (PnP) to estimate rigid transformation during post-processing. However, these methods struggle to map points and pixels to a shared latent space robustly since points and pixels have very different characteristics with patterns learned in different manners (MLP and CNN), and they also fail to construct supervision directly on the transformation since the PnP is non-differentiable, which leads to unstable registration results. To address these problems, we propose to learn a structured cross-modality latent space to represent pixel features and 3D features via a differentiable probabilistic PnP solver. Specifically, we design a triplet network to learn VoxelPoint-to-Pixel matching, where we represent 3D elements using both voxels and points to learn the cross-modality latent space with pixels. We design both the voxel and pixel branch based on CNNs to operate convolutions on voxels/pixels represented in grids, and integrate an additional point branch to regain the information lost during voxelization. We train our framework end-to-end by imposing supervisions directly on the predicted pose distribution with a probabilistic PnP solver. To explore distinctive patterns of cross-modality features, we design a novel loss with adaptive-weighted optimization for cross-modality feature description. The experimental results on KITTI and nuScenes datasets show significant improvements over the state-of-the-art methods. The code and models are available at https://github.com/junshengzhou/VP2P-Match.
GeoDream: Disentangling 2D and Geometric Priors for High-Fidelity and Consistent 3D Generation
Dec 01, 2023



Text-to-3D generation by distilling pretrained large-scale text-to-image diffusion models has shown great promise but still suffers from inconsistent 3D geometric structures (Janus problems) and severe artifacts. The aforementioned problems mainly stem from 2D diffusion models lacking 3D awareness during the lifting. In this work, we present GeoDream, a novel method that incorporates explicit generalized 3D priors with 2D diffusion priors to enhance the capability of obtaining unambiguous 3D consistent geometric structures without sacrificing diversity or fidelity. Specifically, we first utilize a multi-view diffusion model to generate posed images and then construct cost volume from the predicted image, which serves as native 3D geometric priors, ensuring spatial consistency in 3D space. Subsequently, we further propose to harness 3D geometric priors to unlock the great potential of 3D awareness in 2D diffusion priors via a disentangled design. Notably, disentangling 2D and 3D priors allows us to refine 3D geometric priors further. We justify that the refined 3D geometric priors aid in the 3D-aware capability of 2D diffusion priors, which in turn provides superior guidance for the refinement of 3D geometric priors. Our numerical and visual comparisons demonstrate that GeoDream generates more 3D consistent textured meshes with high-resolution realistic renderings (i.e., 1024 $\times$ 1024) and adheres more closely to semantic coherence.
Uni3D: Exploring Unified 3D Representation at Scale
Oct 10, 2023


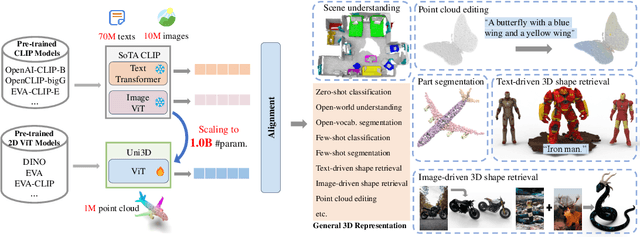
Scaling up representations for images or text has been extensively investigated in the past few years and has led to revolutions in learning vision and language. However, scalable representation for 3D objects and scenes is relatively unexplored. In this work, we present Uni3D, a 3D foundation model to explore the unified 3D representation at scale. Uni3D uses a 2D initialized ViT end-to-end pretrained to align the 3D point cloud features with the image-text aligned features. Via the simple architecture and pretext task, Uni3D can leverage abundant 2D pretrained models as initialization and image-text aligned models as the target, unlocking the great potential of 2D models and scaling-up strategies to the 3D world. We efficiently scale up Uni3D to one billion parameters, and set new records on a broad range of 3D tasks, such as zero-shot classification, few-shot classification, open-world understanding and part segmentation. We show that the strong Uni3D representation also enables applications such as 3D painting and retrieval in the wild. We believe that Uni3D provides a new direction for exploring both scaling up and efficiency of the representation in 3D domain.