 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLINA: Linear Autoregressive Image Generative Models with Continuous Tokens
Jan 30, 2026Autoregressive models with continuous tokens form a promising paradigm for visual generation, especially for text-to-image (T2I) synthesis, but they suffer from high computational cost. We study how to design compute-efficient linear attention within this framework. Specifically, we conduct a systematic empirical analysis of scaling behavior with respect to parameter counts under different design choices, focusing on (1) normalization paradigms in linear attention (division-based vs. subtraction-based) and (2) depthwise convolution for locality augmentation. Our results show that although subtraction-based normalization is effective for image classification, division-based normalization scales better for linear generative transformers. In addition, incorporating convolution for locality modeling plays a crucial role in autoregressive generation, consistent with findings in diffusion models. We further extend gating mechanisms, commonly used in causal linear attention, to the bidirectional setting and propose a KV gate. By introducing data-independent learnable parameters to the key and value states, the KV gate assigns token-wise memory weights, enabling flexible memory management similar to forget gates in language models. Based on these findings, we present LINA, a simple and compute-efficient T2I model built entirely on linear attention, capable of generating high-fidelity 1024x1024 images from user instructions. LINA achieves competitive performance on both class-conditional and T2I benchmarks, obtaining 2.18 FID on ImageNet (about 1.4B parameters) and 0.74 on GenEval (about 1.5B parameters). A single linear attention module reduces FLOPs by about 61 percent compared to softmax attention. Code and models are available at: https://github.com/techmonsterwang/LINA.
Emu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
CI-VID: A Coherent Interleaved Text-Video Dataset
Jul 02, 2025Text-to-video (T2V) generation has recently attracted considerable attention, resulting in the development of numerous high-quality datasets that have propelled progress in this area. However, existing public datasets are primarily composed of isolated text-video (T-V) pairs and thus fail to support the modeling of coherent multi-clip video sequences. To address this limitation, we introduce CI-VID, a dataset that moves beyond isolated text-to-video (T2V) generation toward text-and-video-to-video (TV2V) generation, enabling models to produce coherent, multi-scene video sequences. CI-VID contains over 340,000 samples, each featuring a coherent sequence of video clips with text captions that capture both the individual content of each clip and the transitions between them, enabling visually and textually grounded generation. To further validate the effectiveness of CI-VID, we design a comprehensive, multi-dimensional benchmark incorporating human evaluation, VLM-based assessment, and similarity-based metrics. Experimental results demonstrate that models trained on CI-VID exhibit significant improvements in both accuracy and content consistency when generating video sequences. This facilitates the creation of story-driven content with smooth visual transitions and strong temporal coherence, underscoring the quality and practical utility of the CI-VID dataset We release the CI-VID dataset and the accompanying code for data construction and evaluation at: https://github.com/ymju-BAAI/CI-VID
OmniGen2: Exploration to Advanced Multimodal Generation
Jun 23, 2025In this work, we introduce OmniGen2, a versatile and open-source generative model designed to provide a unified solution for diverse generation tasks, including text-to-image, image editing, and in-context generation. Unlike OmniGen v1, OmniGen2 features two distinct decoding pathways for text and image modalities, utilizing unshared parameters and a decoupled image tokenizer. This design enables OmniGen2 to build upon existing multimodal understanding models without the need to re-adapt VAE inputs, thereby preserving the original text generation capabilities. To facilitate the training of OmniGen2, we developed comprehensive data construction pipelines, encompassing image editing and in-context generation data. Additionally, we introduce a reflection mechanism tailored for image generation tasks and curate a dedicated reflection dataset based on OmniGen2. Despite its relatively modest parameter size, OmniGen2 achieves competitive results on multiple task benchmarks, including text-to-image and image editing. To further evaluate in-context generation, also referred to as subject-driven tasks, we introduce a new benchmark named OmniContext. OmniGen2 achieves state-of-the-art performance among open-source models in terms of consistency. We will release our models, training code, datasets, and data construction pipeline to support future research in this field. Project Page: https://vectorspacelab.github.io/OmniGen2; GitHub Link: https://github.com/VectorSpaceLab/OmniGen2
EVEv2: Improved Baselines for Encoder-Free Vision-Language Models
Feb 10, 2025



Existing encoder-free vision-language models (VLMs) are rapidly narrowing the performance gap with their encoder-based counterparts, highlighting the promising potential for unified multimodal systems with structural simplicity and efficient deployment. We systematically clarify the performance gap between VLMs using pre-trained vision encoders, discrete tokenizers, and minimalist visual layers from scratch, deeply excavating the under-examined characteristics of encoder-free VLMs. We develop efficient strategies for encoder-free VLMs that rival mainstream encoder-based ones. After an in-depth investigation, we launch EVEv2.0, a new and improved family of encoder-free VLMs. We show that: (i) Properly decomposing and hierarchically associating vision and language within a unified model reduces interference between modalities. (ii) A well-designed training strategy enables effective optimization for encoder-free VLMs. Through extensive evaluation, our EVEv2.0 represents a thorough study for developing a decoder-only architecture across modalities, demonstrating superior data efficiency and strong vision-reasoning capability. Code is publicly available at: https://github.com/baaivision/EVE.
Autoregressive Video Generation without Vector Quantization
Dec 18, 2024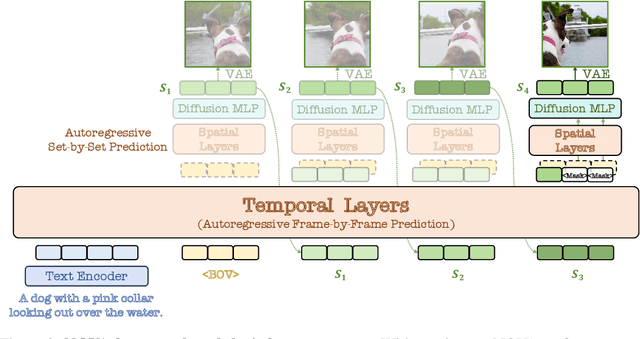
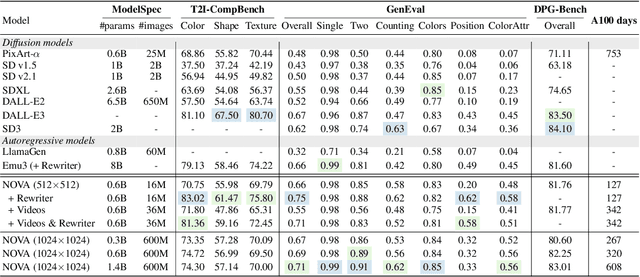
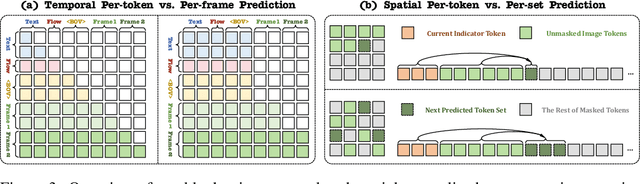
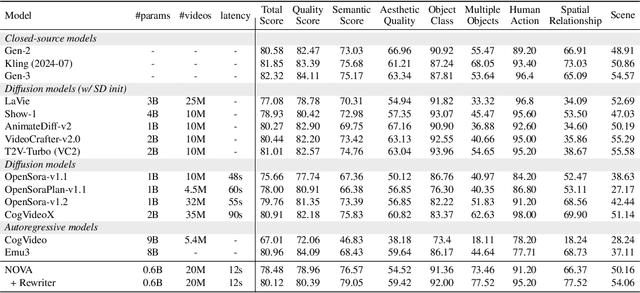
This paper presents a novel approach that enables autoregressive video generation with high efficiency. We propose to reformulate the video generation problem as a non-quantized autoregressive modeling of temporal frame-by-frame prediction and spatial set-by-set prediction. Unlike raster-scan prediction in prior autoregressive models or joint distribution modeling of fixed-length tokens in diffusion models, our approach maintains the causal property of GPT-style models for flexible in-context capabilities, while leveraging bidirectional modeling within individual frames for efficiency. With the proposed approach, we train a novel video autoregressive model without vector quantization, termed NOVA. Our results demonstrate that NOVA surpasses prior autoregressive video models in data efficiency, inference speed, visual fidelity, and video fluency, even with a much smaller model capacity, i.e., 0.6B parameters. NOVA also outperforms state-of-the-art image diffusion models in text-to-image generation tasks, with a significantly lower training cost. Additionally, NOVA generalizes well across extended video durations and enables diverse zero-shot applications in one unified model. Code and models are publicly available at https://github.com/baaivision/NOVA.
You See it, You Got it: Learning 3D Creation on Pose-Free Videos at Scale
Dec 09, 2024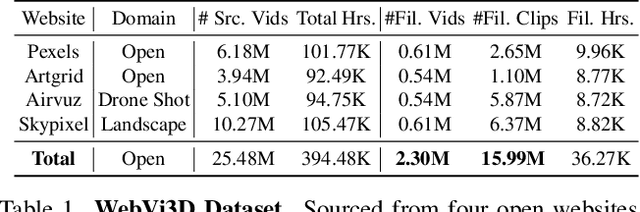
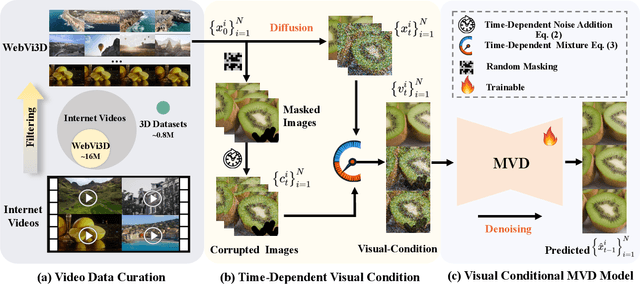
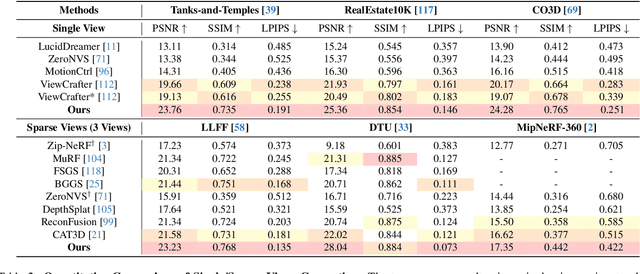

Recent 3D generation models typically rely on limited-scale 3D `gold-labels' or 2D diffusion priors for 3D content creation. However, their performance is upper-bounded by constrained 3D priors due to the lack of scalable learning paradigms. In this work, we present See3D, a visual-conditional multi-view diffusion model trained on large-scale Internet videos for open-world 3D creation. The model aims to Get 3D knowledge by solely Seeing the visual contents from the vast and rapidly growing video data -- You See it, You Got it. To achieve this, we first scale up the training data using a proposed data curation pipeline that automatically filters out multi-view inconsistencies and insufficient observations from source videos. This results in a high-quality, richly diverse, large-scale dataset of multi-view images, termed WebVi3D, containing 320M frames from 16M video clips. Nevertheless, learning generic 3D priors from videos without explicit 3D geometry or camera pose annotations is nontrivial, and annotating poses for web-scale videos is prohibitively expensive. To eliminate the need for pose conditions, we introduce an innovative visual-condition - a purely 2D-inductive visual signal generated by adding time-dependent noise to the masked video data. Finally, we introduce a novel visual-conditional 3D generation framework by integrating See3D into a warping-based pipeline for high-fidelity 3D generation. Our numerical and visual comparisons on single and sparse reconstruction benchmarks show that See3D, trained on cost-effective and scalable video data, achieves notable zero-shot and open-world generation capabilities, markedly outperforming models trained on costly and constrained 3D datasets. Please refer to our project page at: https://vision.baai.ac.cn/see3d
GeoDream: Disentangling 2D and Geometric Priors for High-Fidelity and Consistent 3D Generation
Dec 01, 2023



Text-to-3D generation by distilling pretrained large-scale text-to-image diffusion models has shown great promise but still suffers from inconsistent 3D geometric structures (Janus problems) and severe artifacts. The aforementioned problems mainly stem from 2D diffusion models lacking 3D awareness during the lifting. In this work, we present GeoDream, a novel method that incorporates explicit generalized 3D priors with 2D diffusion priors to enhance the capability of obtaining unambiguous 3D consistent geometric structures without sacrificing diversity or fidelity. Specifically, we first utilize a multi-view diffusion model to generate posed images and then construct cost volume from the predicted image, which serves as native 3D geometric priors, ensuring spatial consistency in 3D space. Subsequently, we further propose to harness 3D geometric priors to unlock the great potential of 3D awareness in 2D diffusion priors via a disentangled design. Notably, disentangling 2D and 3D priors allows us to refine 3D geometric priors further. We justify that the refined 3D geometric priors aid in the 3D-aware capability of 2D diffusion priors, which in turn provides superior guidance for the refinement of 3D geometric priors. Our numerical and visual comparisons demonstrate that GeoDream generates more 3D consistent textured meshes with high-resolution realistic renderings (i.e., 1024 $\times$ 1024) and adheres more closely to semantic coherence.