 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDM-GRPO: Stable and Efficient Group Relative Policy Optimization for Uniform Discrete Diffusion Models
Apr 21, 2026Uniform Discrete Diffusion Model (UDM) has recently emerged as a promising paradigm for discrete generative modeling; however, its integration with reinforcement learning remains largely unexplored. We observe that naively applying GRPO to UDM leads to training instability and marginal performance gains. To address this, we propose UDM-GRPO, the first framework to integrate UDM with RL. Our method is guided by two key insights: (i) treating the final clean sample as the action provides more accurate and stable optimization signals; and (ii) reconstructing trajectories via the diffusion forward process better aligns probability paths with the pretraining distribution. Additionally, we introduce two strategies, Reduced-Step and CFG-Free, to further improve training efficiency. UDM-GRPO significantly improves base model performance across multiple T2I tasks. Notably, GenEval accuracy improves from $69\%$ to $96\%$ and PickScore increases from $20.46$ to $23.81$, achieving state-of-the-art performance in both continuous and discrete settings. On the OCR benchmark, accuracy rises from $8\%$ to $57\%$, further validating the generalization ability of our method. Code is available at https://github.com/Yovecent/UDM-GRPO.
LINA: Linear Autoregressive Image Generative Models with Continuous Tokens
Jan 30, 2026Autoregressive models with continuous tokens form a promising paradigm for visual generation, especially for text-to-image (T2I) synthesis, but they suffer from high computational cost. We study how to design compute-efficient linear attention within this framework. Specifically, we conduct a systematic empirical analysis of scaling behavior with respect to parameter counts under different design choices, focusing on (1) normalization paradigms in linear attention (division-based vs. subtraction-based) and (2) depthwise convolution for locality augmentation. Our results show that although subtraction-based normalization is effective for image classification, division-based normalization scales better for linear generative transformers. In addition, incorporating convolution for locality modeling plays a crucial role in autoregressive generation, consistent with findings in diffusion models. We further extend gating mechanisms, commonly used in causal linear attention, to the bidirectional setting and propose a KV gate. By introducing data-independent learnable parameters to the key and value states, the KV gate assigns token-wise memory weights, enabling flexible memory management similar to forget gates in language models. Based on these findings, we present LINA, a simple and compute-efficient T2I model built entirely on linear attention, capable of generating high-fidelity 1024x1024 images from user instructions. LINA achieves competitive performance on both class-conditional and T2I benchmarks, obtaining 2.18 FID on ImageNet (about 1.4B parameters) and 0.74 on GenEval (about 1.5B parameters). A single linear attention module reduces FLOPs by about 61 percent compared to softmax attention. Code and models are available at: https://github.com/techmonsterwang/LINA.
Emu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
PiCo: Jailbreaking Multimodal Large Language Models via $\textbf{Pi}$ctorial $\textbf{Co}$de Contextualization
Apr 02, 2025Multimodal Large Language Models (MLLMs), which integrate vision and other modalities into Large Language Models (LLMs), significantly enhance AI capabilities but also introduce new security vulnerabilities. By exploiting the vulnerabilities of the visual modality and the long-tail distribution characteristic of code training data, we present PiCo, a novel jailbreaking framework designed to progressively bypass multi-tiered defense mechanisms in advanced MLLMs. PiCo employs a tier-by-tier jailbreak strategy, using token-level typographic attacks to evade input filtering and embedding harmful intent within programming context instructions to bypass runtime monitoring. To comprehensively assess the impact of attacks, a new evaluation metric is further proposed to assess both the toxicity and helpfulness of model outputs post-attack. By embedding harmful intent within code-style visual instructions, PiCo achieves an average Attack Success Rate (ASR) of 84.13% on Gemini-Pro Vision and 52.66% on GPT-4, surpassing previous methods. Experimental results highlight the critical gaps in current defenses, underscoring the need for more robust strategies to secure advanced MLLMs.
EVEv2: Improved Baselines for Encoder-Free Vision-Language Models
Feb 10, 2025



Existing encoder-free vision-language models (VLMs) are rapidly narrowing the performance gap with their encoder-based counterparts, highlighting the promising potential for unified multimodal systems with structural simplicity and efficient deployment. We systematically clarify the performance gap between VLMs using pre-trained vision encoders, discrete tokenizers, and minimalist visual layers from scratch, deeply excavating the under-examined characteristics of encoder-free VLMs. We develop efficient strategies for encoder-free VLMs that rival mainstream encoder-based ones. After an in-depth investigation, we launch EVEv2.0, a new and improved family of encoder-free VLMs. We show that: (i) Properly decomposing and hierarchically associating vision and language within a unified model reduces interference between modalities. (ii) A well-designed training strategy enables effective optimization for encoder-free VLMs. Through extensive evaluation, our EVEv2.0 represents a thorough study for developing a decoder-only architecture across modalities, demonstrating superior data efficiency and strong vision-reasoning capability. Code is publicly available at: https://github.com/baaivision/EVE.
Autoregressive Video Generation without Vector Quantization
Dec 18, 2024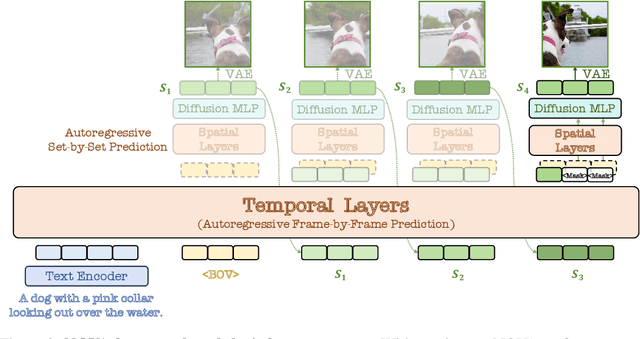
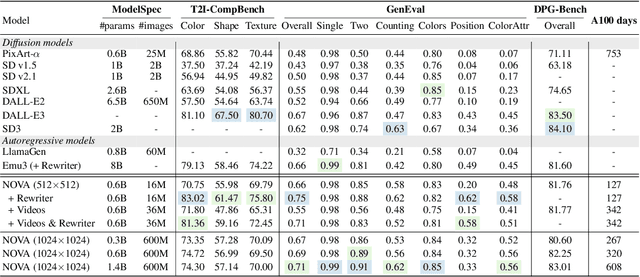
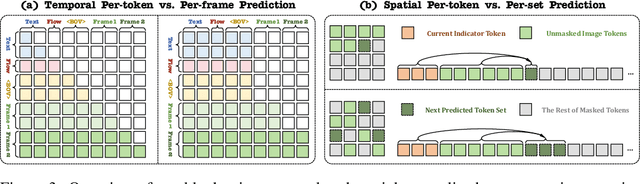
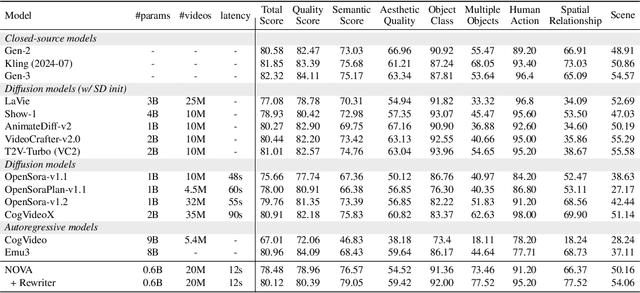
This paper presents a novel approach that enables autoregressive video generation with high efficiency. We propose to reformulate the video generation problem as a non-quantized autoregressive modeling of temporal frame-by-frame prediction and spatial set-by-set prediction. Unlike raster-scan prediction in prior autoregressive models or joint distribution modeling of fixed-length tokens in diffusion models, our approach maintains the causal property of GPT-style models for flexible in-context capabilities, while leveraging bidirectional modeling within individual frames for efficiency. With the proposed approach, we train a novel video autoregressive model without vector quantization, termed NOVA. Our results demonstrate that NOVA surpasses prior autoregressive video models in data efficiency, inference speed, visual fidelity, and video fluency, even with a much smaller model capacity, i.e., 0.6B parameters. NOVA also outperforms state-of-the-art image diffusion models in text-to-image generation tasks, with a significantly lower training cost. Additionally, NOVA generalizes well across extended video durations and enables diverse zero-shot applications in one unified model. Code and models are publicly available at https://github.com/baaivision/NOVA.
Tokenize Anything via Prompting
Dec 14, 2023We present a unified, promptable model capable of simultaneously segmenting, recognizing, and captioning anything. Unlike SAM, we aim to build a versatile region representation in the wild via visual prompting. To achieve this, we train a generalizable model with massive segmentation masks, e.g., SA-1B masks, and semantic priors from a pre-trained CLIP model with 5 billion parameters. Specifically, we construct a promptable image decoder by adding a semantic token to each mask token. The semantic token is responsible for learning the semantic priors in a predefined concept space. Through joint optimization of segmentation on mask tokens and concept prediction on semantic tokens, our model exhibits strong regional recognition and localization capabilities. For example, an additional 38M-parameter causal text decoder trained from scratch sets a new record with a CIDEr score of 150.7 on the Visual Genome region captioning task. We believe this model can be a versatile region-level image tokenizer, capable of encoding general-purpose region context for a broad range of perception tasks. Code and models are available at https://github.com/baaivision/tokenize-anything.
Representation Learning on Heterostructures via Heterogeneous Anonymous Walks
Jan 18, 2022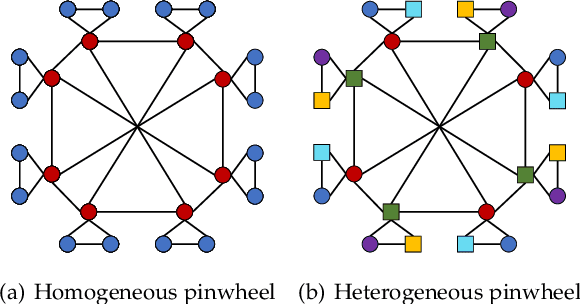
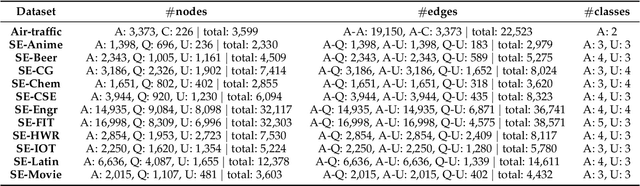
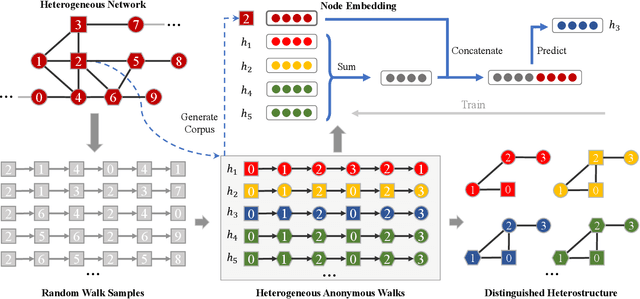
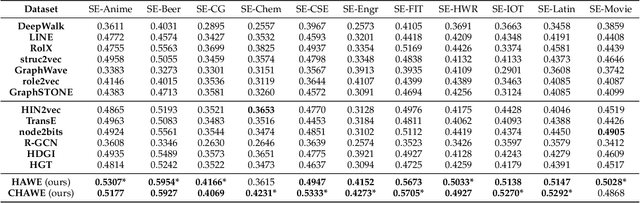
Capturing structural similarity has been a hot topic in the field of network embedding recently due to its great help in understanding the node functions and behaviors. However, existing works have paid very much attention to learning structures on homogeneous networks while the related study on heterogeneous networks is still a void. In this paper, we try to take the first step for representation learning on heterostructures, which is very challenging due to their highly diverse combinations of node types and underlying structures. To effectively distinguish diverse heterostructures, we firstly propose a theoretically guaranteed technique called heterogeneous anonymous walk (HAW) and its variant coarse HAW (CHAW). Then, we devise the heterogeneous anonymous walk embedding (HAWE) and its variant coarse HAWE in a data-driven manner to circumvent using an extremely large number of possible walks and train embeddings by predicting occurring walks in the neighborhood of each node. Finally, we design and apply extensive and illustrative experiments on synthetic and real-world networks to build a benchmark on heterostructure learning and evaluate the effectiveness of our methods. The results demonstrate our methods achieve outstanding performance compared with both homogeneous and heterogeneous classic methods, and can be applied on large-scale networks.
Iterative Self-consistent Parallel Magnetic Resonance Imaging Reconstruction based on Nonlocal Low-Rank Regularization
Aug 10, 2021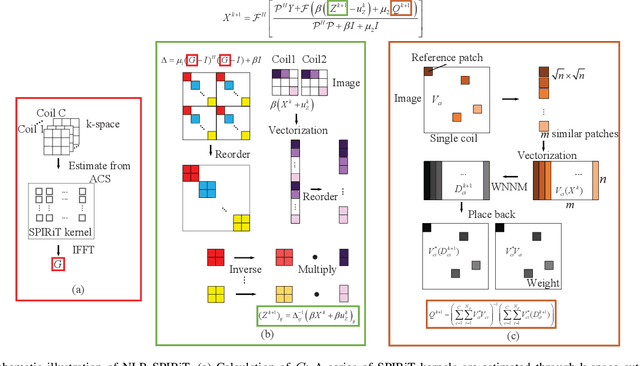
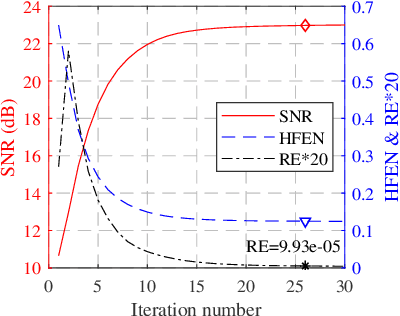
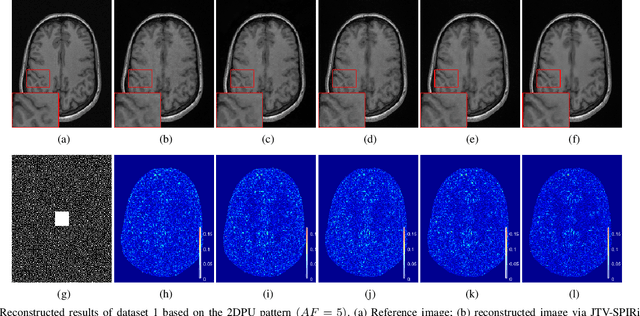
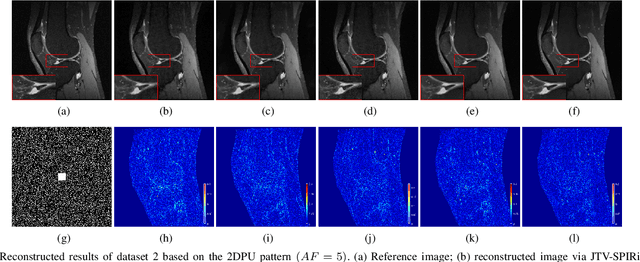
Iterative self-consistent parallel imaging reconstruction (SPIRiT) is an effective self-calibrated reconstruction model for parallel magnetic resonance imaging (PMRI). The joint L1 norm of wavelet coefficients and joint total variation (TV) regularization terms are incorporated into the SPIRiT model to improve the reconstruction performance. The simultaneous two-directional low-rankness (STDLR) in k-space data is incorporated into SPIRiT to realize improved reconstruction. Recent methods have exploited the nonlocal self-similarity (NSS) of images by imposing nonlocal low-rankness of similar patches to achieve a superior performance. To fully utilize both the NSS in Magnetic resonance (MR) images and calibration consistency in the k-space domain, we propose a nonlocal low-rank (NLR)-SPIRiT model by incorporating NLR regularization into the SPIRiT model. We apply the weighted nuclear norm (WNN) as a surrogate of the rank and employ the Nash equilibrium (NE) formulation and alternating direction method of multipliers (ADMM) to efficiently solve the NLR-SPIRiT model. The experimental results demonstrate the superior performance of NLR-SPIRiT over the state-of-the-art methods via three objective metrics and visual comparison.
A Survey on Role-Oriented Network Embedding
Jul 18, 2021
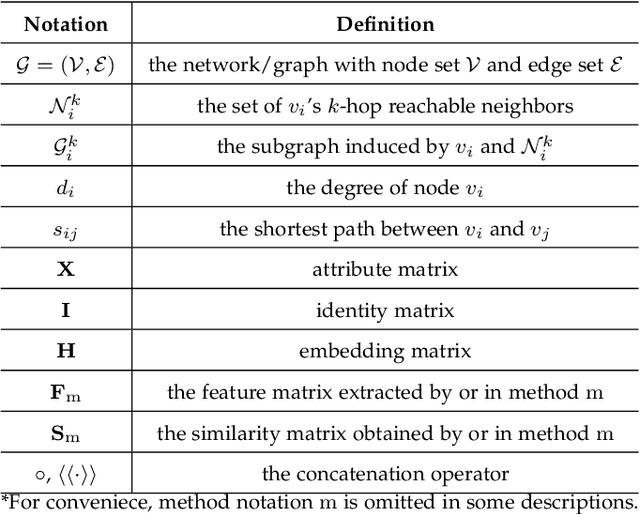
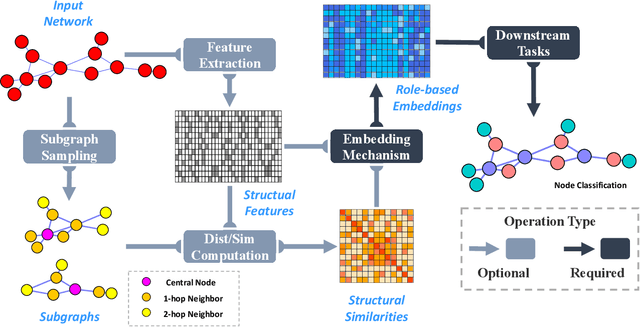
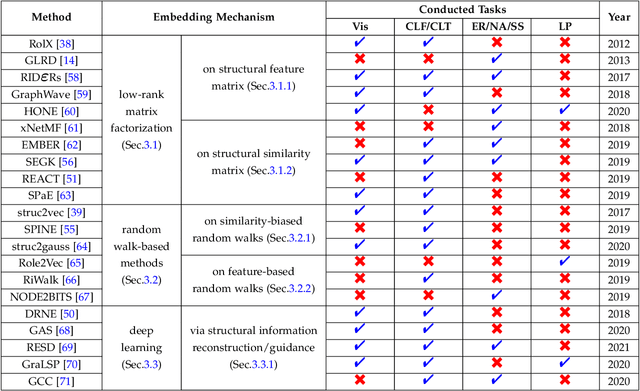
Recently, Network Embedding (NE) has become one of the most attractive research topics in machine learning and data mining. NE approaches have achieved promising performance in various of graph mining tasks including link prediction and node clustering and classification. A wide variety of NE methods focus on the proximity of networks. They learn community-oriented embedding for each node, where the corresponding representations are similar if two nodes are closer to each other in the network. Meanwhile, there is another type of structural similarity, i.e., role-based similarity, which is usually complementary and completely different from the proximity. In order to preserve the role-based structural similarity, the problem of role-oriented NE is raised. However, compared to community-oriented NE problem, there are only a few role-oriented embedding approaches proposed recently. Although less explored, considering the importance of roles in analyzing networks and many applications that role-oriented NE can shed light on, it is necessary and timely to provide a comprehensive overview of existing role-oriented NE methods. In this review, we first clarify the differences between community-oriented and role-oriented network embedding. Afterwards, we propose a general framework for understanding role-oriented NE and a two-level categorization to better classify existing methods. Then, we select some representative methods according to the proposed categorization and briefly introduce them by discussing their motivation, development and differences. Moreover, we conduct comprehensive experiments to empirically evaluate these methods on a variety of role-related tasks including node classification and clustering (role discovery), top-k similarity search and visualization using some widely used synthetic and real-world datasets...