 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
Building Explicit World Model for Zero-Shot Open-World Object Manipulation
Mar 14, 2026Open-world object manipulation remains a fundamental challenge in robotics. While Vision-Language-Action (VLA) models have demonstrated promising results, they rely heavily on large-scale robot action demonstrations, which are costly to collect and can hinder out-of-distribution generalization. In this paper, we propose an explicit-world-model-based framework for open-world manipulation that achieves zero-shot generalization by constructing a physically grounded digital twin of the environment. The framework integrates open-set perception, digital-twin reconstruction, sampling and evaluation of interaction strategies. By constructing a digital twin of the environment, our approach efficiently explores and evaluates manipulation strategies in physic-enabled simulator and reliably deploys the chosen strategy to the real world. Experimentally, the proposed framework is able to perform multiple open-set manipulation tasks without any task-specific action demonstrations, proving strong zero-shot generalization on both the task and object levels. Project Page: https://bojack-bj.github.io/projects/thesis/
Hierarchical Direction Perception via Atomic Dot-Product Operators for Rotation-Invariant Point Clouds Learning
Nov 11, 2025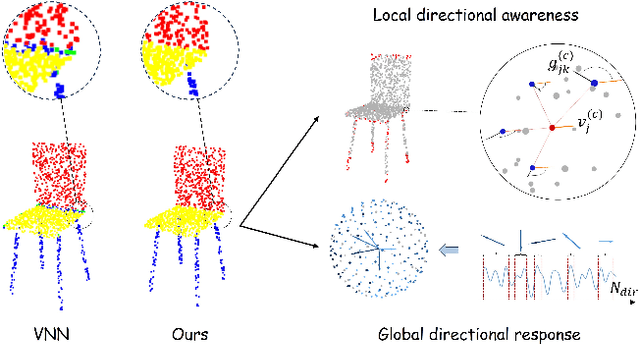
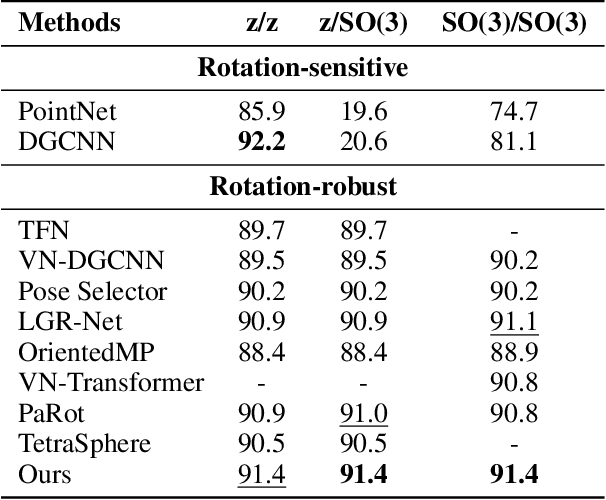
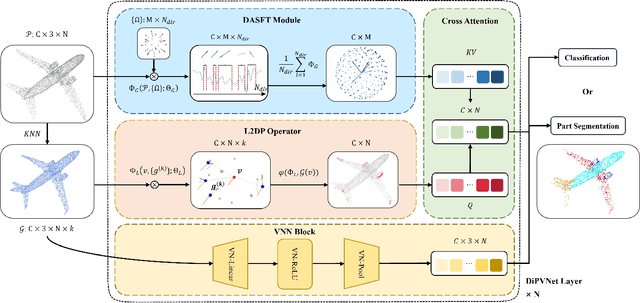
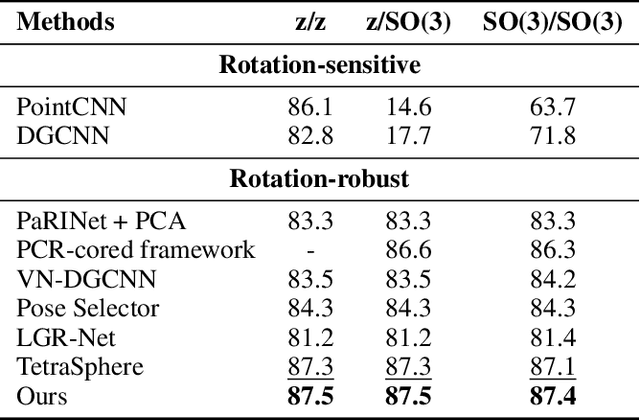
Point cloud processing has become a cornerstone technology in many 3D vision tasks. However, arbitrary rotations introduce variations in point cloud orientations, posing a long-standing challenge for effective representation learning. The core of this issue is the disruption of the point cloud's intrinsic directional characteristics caused by rotational perturbations. Recent methods attempt to implicitly model rotational equivariance and invariance, preserving directional information and propagating it into deep semantic spaces. Yet, they often fall short of fully exploiting the multiscale directional nature of point clouds to enhance feature representations. To address this, we propose the Direction-Perceptive Vector Network (DiPVNet). At its core is an atomic dot-product operator that simultaneously encodes directional selectivity and rotation invariance--endowing the network with both rotational symmetry modeling and adaptive directional perception. At the local level, we introduce a Learnable Local Dot-Product (L2DP) Operator, which enables interactions between a center point and its neighbors to adaptively capture the non-uniform local structures of point clouds. At the global level, we leverage generalized harmonic analysis to prove that the dot-product between point clouds and spherical sampling vectors is equivalent to a direction-aware spherical Fourier transform (DASFT). This leads to the construction of a global directional response spectrum for modeling holistic directional structures. We rigorously prove the rotation invariance of both operators. Extensive experiments on challenging scenarios involving noise and large-angle rotations demonstrate that DiPVNet achieves state-of-the-art performance on point cloud classification and segmentation tasks. Our code is available at https://github.com/wxszreal0/DiPVNet.
Beyond Entropy: Region Confidence Proxy for Wild Test-Time Adaptation
May 27, 2025Wild Test-Time Adaptation (WTTA) is proposed to adapt a source model to unseen domains under extreme data scarcity and multiple shifts. Previous approaches mainly focused on sample selection strategies, while overlooking the fundamental problem on underlying optimization. Initially, we critically analyze the widely-adopted entropy minimization framework in WTTA and uncover its significant limitations in noisy optimization dynamics that substantially hinder adaptation efficiency. Through our analysis, we identify region confidence as a superior alternative to traditional entropy, however, its direct optimization remains computationally prohibitive for real-time applications. In this paper, we introduce a novel region-integrated method ReCAP that bypasses the lengthy process. Specifically, we propose a probabilistic region modeling scheme that flexibly captures semantic changes in embedding space. Subsequently, we develop a finite-to-infinite asymptotic approximation that transforms the intractable region confidence into a tractable and upper-bounded proxy. These innovations significantly unlock the overlooked potential dynamics in local region in a concise solution. Our extensive experiments demonstrate the consistent superiority of ReCAP over existing methods across various datasets and wild scenarios.
Composite Indicator-Guided Infilling Sampling for Expensive Multi-Objective Optimization
Mar 28, 2025In expensive multi-objective optimization, where the evaluation budget is strictly limited, selecting promising candidate solutions for expensive fitness evaluations is critical for accelerating convergence and improving algorithmic performance. However, designing an optimization strategy that effectively balances convergence, diversity, and distribution remains a challenge. To tackle this issue, we propose a composite indicator-based evolutionary algorithm (CI-EMO) for expensive multi-objective optimization. In each generation of the optimization process, CI-EMO first employs NSGA-III to explore the solution space based on fitness values predicted by surrogate models, generating a candidate population. Subsequently, we design a novel composite performance indicator to guide the selection of candidates for real fitness evaluation. This indicator simultaneously considers convergence, diversity, and distribution to improve the efficiency of identifying promising candidate solutions, which significantly improves algorithm performance. The composite indicator-based candidate selection strategy is easy to achieve and computes efficiency. Component analysis experiments confirm the effectiveness of each element in the composite performance indicator. Comparative experiments on benchmark problems demonstrate that the proposed algorithm outperforms five state-of-the-art expensive multi-objective optimization algorithms.
EVEv2: Improved Baselines for Encoder-Free Vision-Language Models
Feb 10, 2025



Existing encoder-free vision-language models (VLMs) are rapidly narrowing the performance gap with their encoder-based counterparts, highlighting the promising potential for unified multimodal systems with structural simplicity and efficient deployment. We systematically clarify the performance gap between VLMs using pre-trained vision encoders, discrete tokenizers, and minimalist visual layers from scratch, deeply excavating the under-examined characteristics of encoder-free VLMs. We develop efficient strategies for encoder-free VLMs that rival mainstream encoder-based ones. After an in-depth investigation, we launch EVEv2.0, a new and improved family of encoder-free VLMs. We show that: (i) Properly decomposing and hierarchically associating vision and language within a unified model reduces interference between modalities. (ii) A well-designed training strategy enables effective optimization for encoder-free VLMs. Through extensive evaluation, our EVEv2.0 represents a thorough study for developing a decoder-only architecture across modalities, demonstrating superior data efficiency and strong vision-reasoning capability. Code is publicly available at: https://github.com/baaivision/EVE.
InstructBioMol: Advancing Biomolecule Understanding and Design Following Human Instructions
Oct 10, 2024Understanding and designing biomolecules, such as proteins and small molecules, is central to advancing drug discovery, synthetic biology, and enzyme engineering. Recent breakthroughs in Artificial Intelligence (AI) have revolutionized biomolecular research, achieving remarkable accuracy in biomolecular prediction and design. However, a critical gap remains between AI's computational power and researchers' intuition, using natural language to align molecular complexity with human intentions. Large Language Models (LLMs) have shown potential to interpret human intentions, yet their application to biomolecular research remains nascent due to challenges including specialized knowledge requirements, multimodal data integration, and semantic alignment between natural language and biomolecules. To address these limitations, we present InstructBioMol, a novel LLM designed to bridge natural language and biomolecules through a comprehensive any-to-any alignment of natural language, molecules, and proteins. This model can integrate multimodal biomolecules as input, and enable researchers to articulate design goals in natural language, providing biomolecular outputs that meet precise biological needs. Experimental results demonstrate InstructBioMol can understand and design biomolecules following human instructions. Notably, it can generate drug molecules with a 10% improvement in binding affinity and design enzymes that achieve an ESP Score of 70.4, making it the only method to surpass the enzyme-substrate interaction threshold of 60.0 recommended by the ESP developer. This highlights its potential to transform real-world biomolecular research.
Toward Scalable Image Feature Compression: A Content-Adaptive and Diffusion-Based Approach
Oct 08, 2024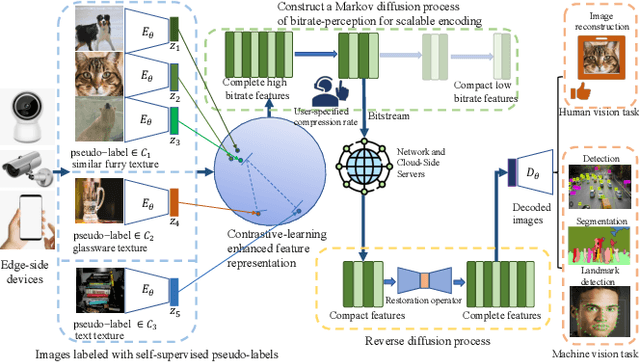
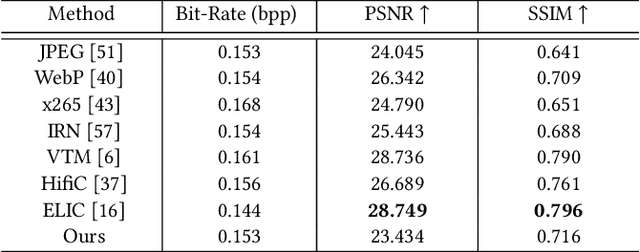

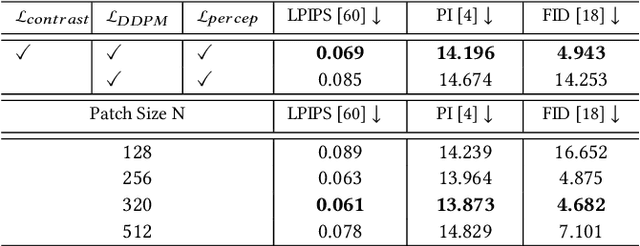
Traditional image codecs emphasize signal fidelity and human perception, often at the expense of machine vision tasks. Deep learning methods have demonstrated promising coding performance by utilizing rich semantic embeddings optimized for both human and machine vision. However, these compact embeddings struggle to capture fine details such as contours and textures, resulting in imperfect reconstructions. Furthermore, existing learning-based codecs lack scalability. To address these limitations, this paper introduces a content-adaptive diffusion model for scalable image compression. The proposed method encodes fine textures through a diffusion process, enhancing perceptual quality while preserving essential features for machine vision tasks. The approach employs a Markov palette diffusion model combined with widely used feature extractors and image generators, enabling efficient data compression. By leveraging collaborative texture-semantic feature extraction and pseudo-label generation, the method accurately captures texture information. A content-adaptive Markov palette diffusion model is then applied to represent both low-level textures and high-level semantic content in a scalable manner. This framework offers flexible control over compression ratios by selecting intermediate diffusion states, eliminating the need for retraining deep learning models at different operating points. Extensive experiments demonstrate the effectiveness of the proposed framework in both image reconstruction and downstream machine vision tasks such as object detection, segmentation, and facial landmark detection, achieving superior perceptual quality compared to state-of-the-art methods.
DenseFusion-1M: Merging Vision Experts for Comprehensive Multimodal Perception
Jul 11, 2024



Existing Multimodal Large Language Models (MLLMs) increasingly emphasize complex understanding of various visual elements, including multiple objects, text information, and spatial relations. Their development for comprehensive visual perception hinges on the availability of high-quality image-text datasets that offer diverse visual elements and throughout image descriptions. However, the scarcity of such hyper-detailed datasets currently hinders progress within the MLLM community. The bottleneck stems from the limited perceptual capabilities of current caption engines, which fall short in providing complete and accurate annotations. To facilitate the cutting-edge research of MLLMs on comprehensive vision perception, we thereby propose Perceptual Fusion, using a low-budget but highly effective caption engine for complete and accurate image descriptions. Specifically, Perceptual Fusion integrates diverse perception experts as image priors to provide explicit information on visual elements and adopts an efficient MLLM as a centric pivot to mimic advanced MLLMs' perception abilities. We carefully select 1M highly representative images from uncurated LAION dataset and generate dense descriptions using our engine, dubbed DenseFusion-1M. Extensive experiments validate that our engine outperforms its counterparts, where the resulting dataset significantly improves the perception and cognition abilities of existing MLLMs across diverse vision-language benchmarks, especially with high-resolution images as inputs. The dataset and code are publicly available at https://github.com/baaivision/DenseFusion.
Unveiling Encoder-Free Vision-Language Models
Jun 17, 2024Existing vision-language models (VLMs) mostly rely on vision encoders to extract visual features followed by large language models (LLMs) for visual-language tasks. However, the vision encoders set a strong inductive bias in abstracting visual representation, e.g., resolution, aspect ratio, and semantic priors, which could impede the flexibility and efficiency of the VLMs. Training pure VLMs that accept the seamless vision and language inputs, i.e., without vision encoders, remains challenging and rarely explored. Empirical observations reveal that direct training without encoders results in slow convergence and large performance gaps. In this work, we bridge the gap between encoder-based and encoder-free models, and present a simple yet effective training recipe towards pure VLMs. Specifically, we unveil the key aspects of training encoder-free VLMs efficiently via thorough experiments: (1) Bridging vision-language representation inside one unified decoder; (2) Enhancing visual recognition capability via extra supervision. With these strategies, we launch EVE, an encoder-free vision-language model that can be trained and forwarded efficiently. Notably, solely utilizing 35M publicly accessible data, EVE can impressively rival the encoder-based VLMs of similar capacities across multiple vision-language benchmarks. It significantly outperforms the counterpart Fuyu-8B with mysterious training procedures and undisclosed training data. We believe that EVE provides a transparent and efficient route for developing a pure decoder-only architecture across modalities. Our code and models are publicly available at: https://github.com/baaivision/EVE.