 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Scalable Image Feature Compression: A Content-Adaptive and Diffusion-Based Approach
Paper and Code
Oct 08, 2024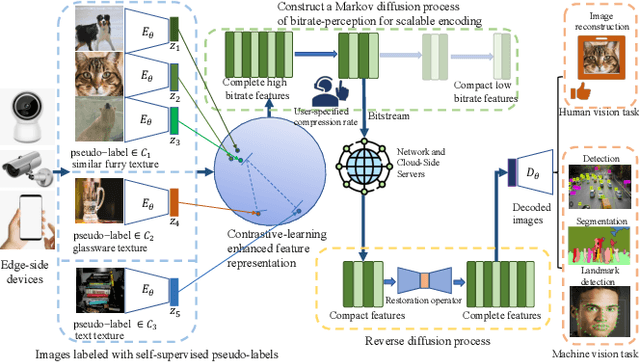
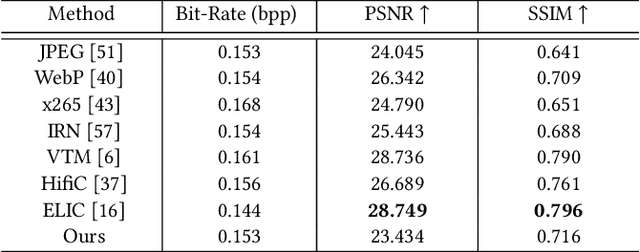

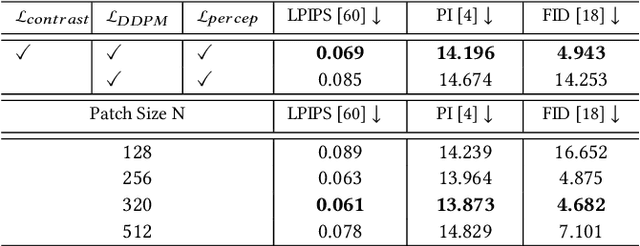
Traditional image codecs emphasize signal fidelity and human perception, often at the expense of machine vision tasks. Deep learning methods have demonstrated promising coding performance by utilizing rich semantic embeddings optimized for both human and machine vision. However, these compact embeddings struggle to capture fine details such as contours and textures, resulting in imperfect reconstructions. Furthermore, existing learning-based codecs lack scalability. To address these limitations, this paper introduces a content-adaptive diffusion model for scalable image compression. The proposed method encodes fine textures through a diffusion process, enhancing perceptual quality while preserving essential features for machine vision tasks. The approach employs a Markov palette diffusion model combined with widely used feature extractors and image generators, enabling efficient data compression. By leveraging collaborative texture-semantic feature extraction and pseudo-label generation, the method accurately captures texture information. A content-adaptive Markov palette diffusion model is then applied to represent both low-level textures and high-level semantic content in a scalable manner. This framework offers flexible control over compression ratios by selecting intermediate diffusion states, eliminating the need for retraining deep learning models at different operating points. Extensive experiments demonstrate the effectiveness of the proposed framework in both image reconstruction and downstream machine vision tasks such as object detection, segmentation, and facial landmark detection, achieving superior perceptual quality compared to state-of-the-art methods.